- Published on
This Week I learned 9
Summary
1. [Dev] Supabase
2. [Dev] Naver API 로 OAuth credentials 얻기
3. [Paper] General Grasp, Dexterous grasp 관련 논문 정리
4. [Paper] Dexterous Grasp Transformer
5. [Paper] DexTOG: Learning Task-Oriented Dexterous Grasp with Language Condition
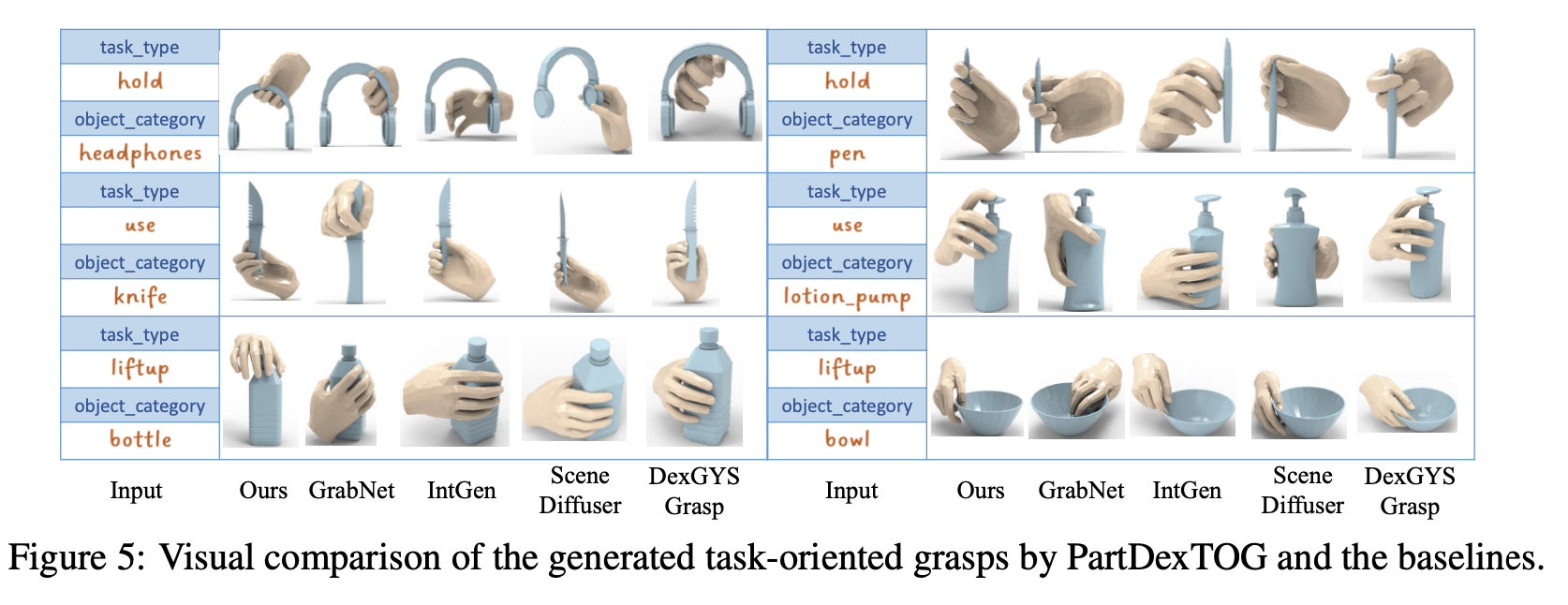
6. [Paper] PartDexTOG: Generating Dexterous Task-Oriented Grasping via Language-driven Part Analysis
[Dev] Supabase
Concept
- PostgreSQL 기반 Baas(Backend as a Service)
- Firebase 는 NoSQL 기반
- 핵심 기능
- 데이터베이스
- Authentication
- 파일 스토리지
- 자동 RESTful API 생성
Authentication
- supabase 에서는 기본 인증 기능을 내장하고 있음
- 이메일/비밀번호, 소셜 로그인 기능 제공
- 다만 OAuth 제공자가 제한적임
- Google, Github, Apple, Discord, Facebook 등은 가능
- Naver, Kakao Talk 불가능
- 이 경우에는 Supabase signInWithIdToken 을 사용하여 커스텀 OAuth 를 붙일 수도 있고, NextAuth + Supabase 조합을 생각해 볼 수 있음
- 네이버 로그인이 필수라면 NextAuth 를 도입하고, Supabase는 db 로만 사용하는 것이 현실적임
- Supabase 는 Row Level Security (RLS)로 데이터 보안 설정을 변경해주어야 함
[Dev] Naver API 로 OAuth credentials 얻기
- Naver Developers 에서 Application 등록을 진행해야 함
어플리케이션 이름입력하기- 사용 API 로
네이버 로그인선택 - 로그인 오픈 API 서비스 환경에서,
서비스 URL과네이버 로그인 Callback URL넣어주고 등록하기
- 이것까지 해주게 되면 CLIENT_ID 와 CLIENT_SECRET 을 발급받을 수 있음
[Paper] General Grasp, Dexterous grasp 관련 논문 정리
| FrameWork | Base Model | Input | Output | GPU Resource | Grasp Gear | etc | Strength | Weakness | Link |
|---|---|---|---|---|---|---|---|---|---|
| DexTOG | Conditional Diffusion Model (Conditional DDPM) | 자연어 명령, 3D 객체 관측 (Point Cloud) | Dexterous Grasp Pose | N/A | Shadow Hand | Conditional Diffusion Process + 작업 지향적 그립(Task-Oriented Grasping) 생성에 중점 | 자연어 명령에 맞는 포즈 생성, 5가지 작업 지향적 그립을 다룸. 각 포즈에 대한 데이터셋 확보 방법 제안. 데이터셋도 도움이 될 듯 | 코드를 찾기 어려움 | https://arxiv.org/html/2504.04573v1 |
| PartDexTOG | Category-Part Conditional Diffusion Model | 언어 지침 (Manipulation Task), 3D 객체 (Point Cloud) | Dexterous Grasp | RTX 4090 * 1 | Dexterous Hand | GPT-4o 를 사용하여 언어 기반 부위 분석을 통한 작업 지향적 그립 생성 | 객체의 부위들과 명령어의 특징을 분석하는 방법이 특징, 고정적인 객체 유형 - 작업 유형 조합에 국한되지 않음 | 코드를 찾기 어려움 | https://arxiv.org/pdf/2505.12294 |
| DexGYSGrasp (Grasp as You Say) | Conditional Diffusion Model | 자연어 명령, Full Object Point Cloud | Pose Parameter (rotation, translation, angle) | RTX 4090 * 1 | 22-DoF Dexterous Hand | 언어 기반의 미세 조정 가능한 그립 생성 | Hand Parameter 예측 | https://arxiv.org/pdf/2405.19291, https://github.com/iSEE-Laboratory/Grasp-as-You-Say | |
| DexGrasp Anything (DGA) | Diffusion Model | 3D 표현 (Object Input), 언어 프롬프트 (Object prompt) | Grasp Result (Dexterous Grasp Pose) | N/A | ShadowHand (Dexterous Hand) | Physical Awareness 개념과 Diffusion model 에의 적용 | Physical constraint 를 적용하여 hand pose 생성 | Diffusion model 의 한계를 해소하는 것을 주요 목적으로 함. text 는 객체에 대한 특징 추출을 목적으로 함. 의도를 담고 있지는 않음 | https://arxiv.org/pdf/2503.08257 |
| GTR (Dexterous Grasp Transformer) | Transformer (Set Prediction) | 객체 Point Cloud | Dexterous Grasp Pose | N/A | ShadowHand (22-DoF) | 한 번의 Forward path 로 복수의 안정적인 그립 예측, 추론 때에 refine 하는 알고리즘 제안 | 한 번에 복수의 그립을 예측할 수 있음 | 자연어 인스트럭션을 입력으로 받지 않음, 복수의 예측이 우리에게 과연 필요할까 | https://arxiv.org/pdf/2404.18135 |
| GraspMolmo | VLM(Molmo) | 자연어 명령, RGB-D 이미지 | 2D point (Grasp Point) | Nvidia H100 GPU * 64 | 6 DoF Gripper (Franka FR3) | M2T2 로 2d point 를 grasp pose 로 변환함 | Gripper 사용, VLM 파인튜닝 | https://arxiv.org/pdf/2505.13441 | |
| Reasoning Grasping (RT-Grasp) | Multi-Modal LLM + LoRA | 자연어 명령, RGB-D 관측 | Grasp Detection (2D/6D Grasp Pose 예측) | N/A | Gripper | 로봇이 implicit 지침을 해석하고 잡을 대상을 추론하도록 함 | VLM 이 수치 예측을 잘할 수 있도록 유도 | Gripper 사용 | https://arxiv.org/pdf/2411.05212 |
[Paper] Dexterous Grasp Transformer
Concept
- object point cloud 를 처리하여 다양한 grasp pose 를 생성하는 프레임워크 DGTR(Dexterous Grasp TRansformer) 제안
- One forward pass 만을 가진다는 것이 특징
- 최적화 문제를 해결하기 위해 다음 두 가지 방법 적용
- Dynamic-Static Matching Training(DSMT)
- Adversarial-Balanced Test-Time Adaptation(AB-TTA)
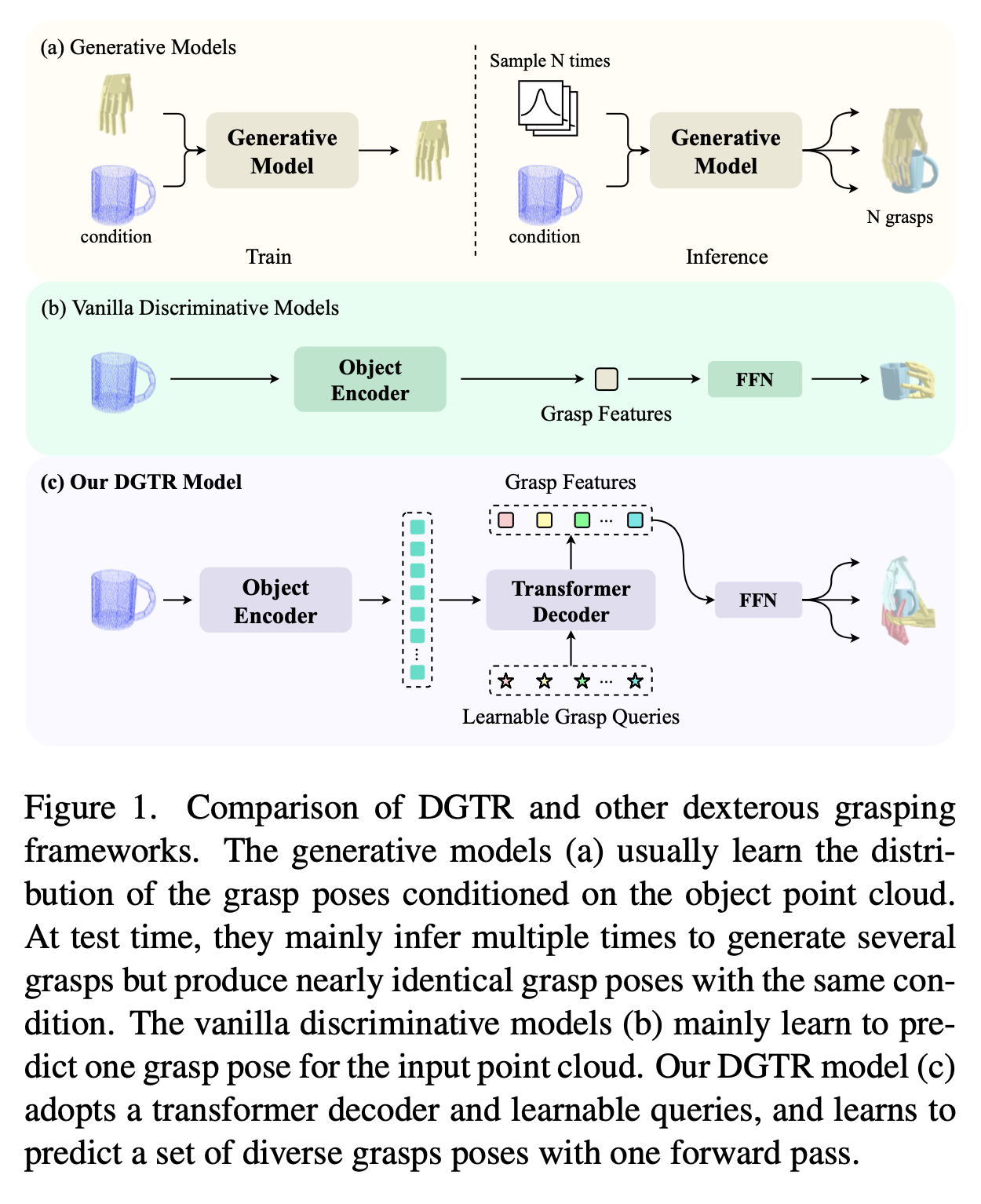
- 한 번의 forward path 를 통해 여러 개의 prediction 을 생성하는 것이 주요 Contribution 중 하나
Method Overview
Problem Formulation
- complete object point cloud 로부터 다양한 Grasp들을 생성하는 그립 자세를 생성하는 것을 목표 → 하나가 아닌 set prediction 을 목표로 함
- object point cloud:
- 숙련된 개의 그립 자세:
- 개별 그립 자세 g_i$$는 다음과 같이 구성
- : global rotation
- : global translation
- : joint angles(-DoF, ShadowHand는 22)
DGTR Architecture
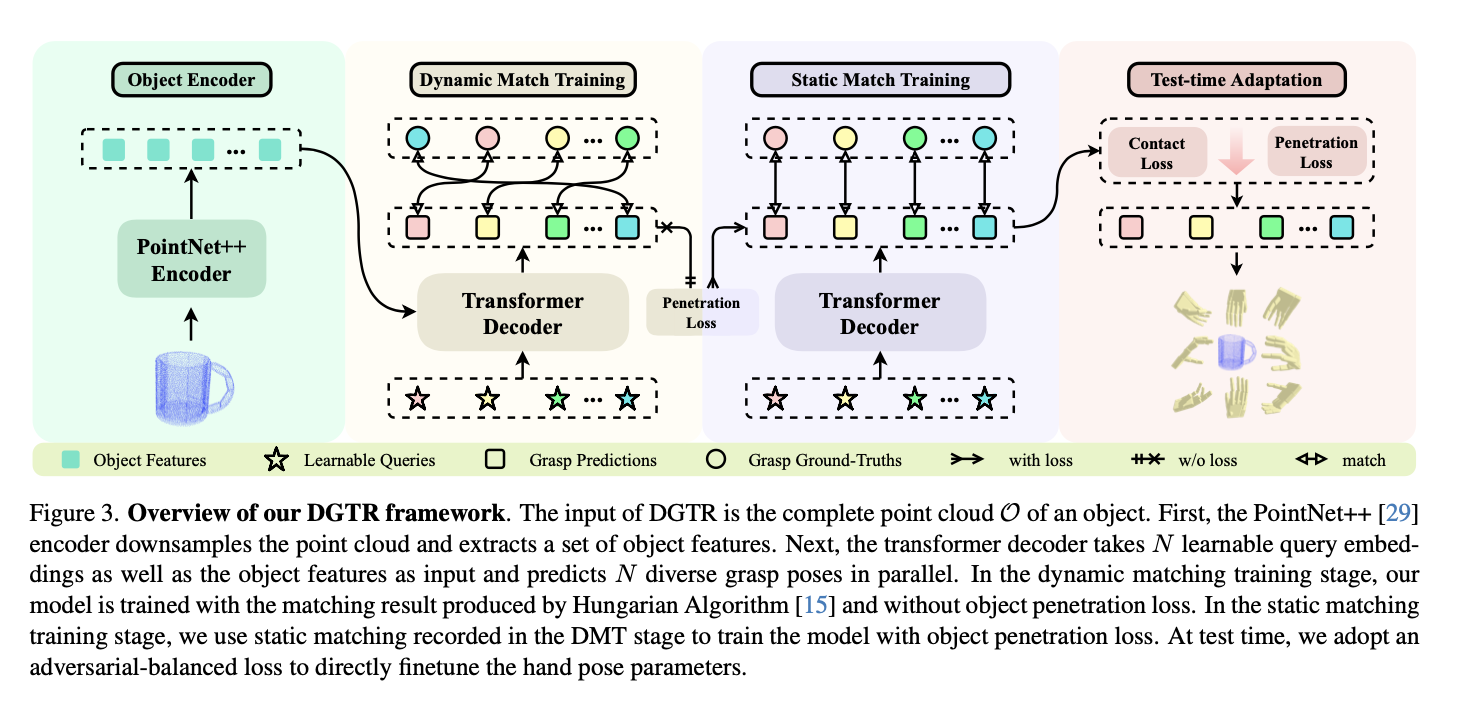
- 다음 세 가지 컴포넌트로 구성됨
- point cloud encoder
- 3 layer PointNet++ 를 사용하여 object point cloud 의 특징을 추출함
- transformer decoder
- 다음 두 논문에서 set-prediction 에 대한 영감을 얻음
- extracted point cloud feature 와 N개의 learnable grasping queries 을 입력으로 받아 N 개의 grasp feature 를 생성함
- feed-forward network
- 를 입력으로 받아 grasp pose set 을 생성함
- 는 sigmoid function 으로 정규화하여 생성(0~1)
- 는 L2 normalization 을 적용해 Unit quaternion 으로 정규화하여 생성
- 를 입력으로 받아 grasp pose set 을 생성함
- loss 계산
- 예측치가 하나가 아닌 복수이므로 Loss 계산에 문제가 생길 수 있음
- 여기서는 헝가리안 알고리즘을 사용하여 가장 가까운 gt 를 찾고, 해당 gt 와의 차이를 통해 loss 를 계산하는 방식을 사용함
- 이를 optimal bipartite matching 이라고 부름
- 다만 이 방법은 매칭의 모호성으로 인해 model collapse 와 object penetration 간의 딜레마의 원인이 됨
Dynamic-Static Matching Training Strategy(DSMT)

- model collapse 와 object penetration 간의 딜레마
- model collapse: penetration penalty 를 높게 주면 대부분의 예측이 거의 유사해지는 문제가 있음
- object penetration: penetration penalty 를 낮게 주면 객체를 관통하는 문제가 자주 발생함
- 최적화 문제를 두 단계로 나누어 접근하는 방식으로 해소
- Dynamic Training: 헝가리안 알고리즘의 유연성을 활용, 다양한 그립 패턴을 학습하도록 유도
- Static Training: 객체 관통 문제에 대한 최적화 적용
- 최종적으로 다음 세 가지 단계로 학습을 구성함
- Dynamic Matching Training
- 관통 패널티는 제외함, 모델이 다양한 그립 타겟을 자유롭게 학습할 수 있도록 함
- Static Matching Warm-up
- 헝가리안 알고리즘으로 찾은 가장 안정적인 매칭 결과 기록을 바탕으로 label 을 고정하고 학습, 관통 패널티는 여전히 제외됨
- Static Matchting Penetration Training
- 관통 패널티를 적용하여 객체 관통 문제를 해결하는 방향으로 학습
- Dynamic Matching Training
Adversarial-Balanced Test-Time Adaptation(AB-TTA)
- 추론 단계에서 그립의 자세를 refine 하는 방법
- 두 가지 Adversarial 한 loss 인 객체 관통 손실()과 손-객체 거리 손실( or ) 를 최소화하도록 함
- 두 가지 loss 는 손과 물체의 거리에 따라 서로 상반되게 변하므로 두 가지를 균형있게 개선하는 것이 핵심
- 두 가지를 통합하여 균형 있게 최적화함
- 손 자세가 과도하게 변화하는 것을 막기 위한 전역 이동 조정(Translation Moderation)
- 손이 객체로부터 너무 멀리 떨어져 나가는 것을 방지하고 접촉을 유지하도록 제약하는 일반화된 TTA 거리 손실(Generalized TTA-Distance Loss)
[Paper] DexTOG: Learning Task-Oriented Dexterous Grasp with Language Condition
Concept
- language-guided diffusion-based learning framework 인 DexTOG 제안
- TOG: Task-Oriented Grasping
- DexTOG 는 쥐는 포즈를 생성하는 diffusion Model 인 DexDiffu 와 이를 지원하는 Data engine 으로 구성됨
DiffuTOG Overview
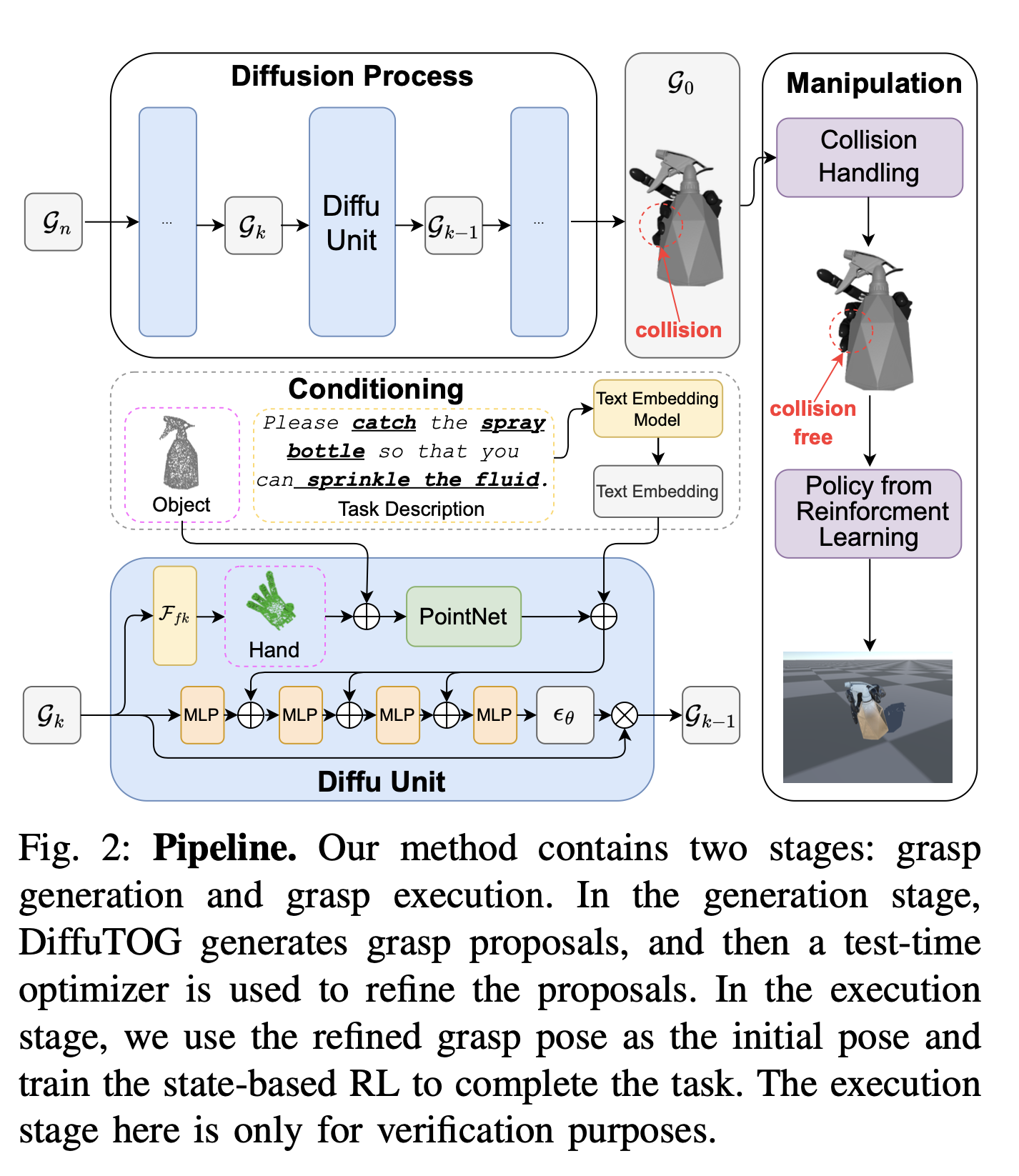
Formulation
- 3D Point Cloud , Task Desc , 로봇 손 모델 이 주어져 있을 때, 그립 자세 를 예측하는 것이 목표
- 이때 그립 자세는 Wrist rotation, Translation, -DoF Joint Pose 로 구성됨
Grasping Generation Through Denoising Diffusion Probabilistic Models (DDPMs)
- Task agnostic grasping 을 unconditioned diffusion process 로 수식화할 수 있으므로, Task-oriented grasp 는 conditional diffusion process 로 수식화할 수 있음
- 일반적인 diffusion model 의 Denoising process 의 iterative equation
- 는 파라미터 를 가진 노이즈 예측 네트워크
- 은 매 단계마다 추가되는 가우시안 노이즈
- 널리 사용되어온 quaternion vector 로 wrist rotation 을 표현하는 방법은 문제가 있음
- quaternion vector 에서의 rotation 은 곱셈으로 적용되나, diffusion process 에서의 Noise 는 덧셈으로 추가되기 때문임
- 이로 인해 quaternion vector 에 대한 증가가 rotation 의 증가로 직접 대응되지는 못하고, 약간의 노이즈로 인해 잘못된 자세가 생성될 가능성이 커짐
- 이를 해결하기 위해 6D rotation representation 방법론을 적용함
- 임의의 3차원 벡터 를 사용하여 고유의 hand-wrist coordinate 을 구성할 수 있음
Conditional Embedding & Conditional DDPM Training
- 세 가지 conditional embedding 을 diffusion process 에 추가하여 이에 맞는 pose 를 생성할 수 있도록 함
- Hand Encoder
- hand point cloud 를 full-1 vector 로 보강하여 로 만듦
- 이를 PointNet 에 통과시켜 를 생성함
- Object Encoder
- object point cloud 를 full-0 vector 로 보강하여 를 생성함
- 이를 PointNet 으로 인코딩하여 를 생성함
- 손과 달리 객체는 변화하지 않으므로 한 번만 호출됨
- Task Desc Encoder
- Task Desc 를 OpenAI 임베딩 모델(text-embedding-ada-002) 로 인코딩하여 를 생성함
- 이를 3 layer MLP 로 256차원 로 압축함
- Hand Encoder
- 이 세 가지 조건부 임베딩은 Diffu Unit 내부의 MLP 의 입력으로 전달되어, diffusion model 이 객체의 특징, 현재 손의 상태, 작업 목표에 따라 노이즈를 예측하고 denoising 하도록 유도함
- 최종적으로 다음과 같은 Conditional DDPM 수식을 얻을 수 있음
- 학습은 Diffusion Loss 와 Recon Loss 의 합으로 구성됨
- Diffusion Loss: 추가된 gaussian noise 과 추정 노이즈 간의 차이(L2)
- Recon Loss: 예측된 자세와 실제 자세 간의 차이
- Total loss
DEXTOG, DATA ENGINE Overview
- 작업 지향적 그립 데이터셋을 구축하는 방법

작업의 종류
- 다음 다섯 가지 작업
- Stapler Clicking
- Spray Bottle Pressing
- Spray Bottle Triggering
- Bottle Cap Twisting
- Ballpoint Pen Pressing
- 안정적인 그립 + 특정 기능적 구성 요소 근처에 정확히 손가락을 배치해야 하는 테스크들
작업 설명 생성
- ChatGPT 사용
- 총 22개의 템플릿과 5개의 행동 속성, 16개의 부품 속성, 18개의 어포던스 속성이 사용
작업 지향적 그립 생성
- Task-agnostic grasping 에서 시작하여 coarse-to-fine 으로 진행되는 파이프라인을 통해 Task-oriented grasping 자세를 필터링하는 방법 사용
- AKB-48 dataset 에서 객체를 임의로 선택함
- ISF 라는 분석적인 그립 계획 알고리즘을 통해 Task-agnostic grasping 을 생성하고, 이를 물리 기반 시뮬레이터에서 검증함
- ISF - Grasp planning for customized grippers by iterative surface fitting
- 제약 조건을 고려하지 않으므로 0.1% 정도만이 쓸모가 있음, 어떻게 필터링하느냐가 중요함
- Rule-based Filtering
- 휴리스틱 기준을 적용하여 coarse 하게 필터링하는 방법
- 예를 들어, 볼펜 누르기의 경우 엄지 또는 검지의 끝점이 버튼 상단 표면으로부터 2.5mm 이내에 위치하여야 함
- Bootstrapping with DiffuTOG
- DiffuTOG 를 부트스트래핑하여 제한적인 갯수의 유효한 그립을 늘리도록 함
- 필터링된 유효한 그립으로 먼저 DiffuTOG 모델을 학습
- 이를 통해 유효한 샘플의 갯수가 대폭 증가함
- TOG Selection with RL
- DiffuTOG을 통해 증폭된 그립 자세가 실제로 작업을 성공적으로 수행할 수 있는지 시뮬레이션 환경에서 검증하는 단계
- 각 작업에 대한 Policy 를 훈련하여 시뮬레이터 내에서 작업을 성공적으로 수행할 수 있는지 확인하는 방식으로 검증
- PPO 알고리즘 + 보상 함수(작업 보상 + 들어올리기 보상 + 작업 완료 보상 + 낙하 패널티)
- 작업 보상은 작업의 진행에 대한 보상으로, 관절의 각도 변화량으로 측정함
- 작업 완료 보상은 최종 목표 달성 시 주어지는 보상으로, 객체 높이 및 관절 각도의 최종 통과를 기준으로 함
- Action Space 에 대한 언급은 없는 듯
[Paper] PartDexTOG: Generating Dexterous Task-Oriented Grasping via Language-driven Part Analysis
Concept
- 객체를 part 별로 나누어 분석하여 상세한 정보를 제공함으로써 grasping 을 발전시킬 수 있음
- 3D 객체와 자연어 설명을 입력으로 받아 LLM 을 활용해 자연어로 된 category-level 및 part-level description 을 생성함
- category-part conditional diffusion model 을 적용해 dexterous grasp 를 생성함
- grasping 과 부품 간의 geometric consistency 를 계산하여 그럴듯한 조합 선택을 유도함
Method Overview
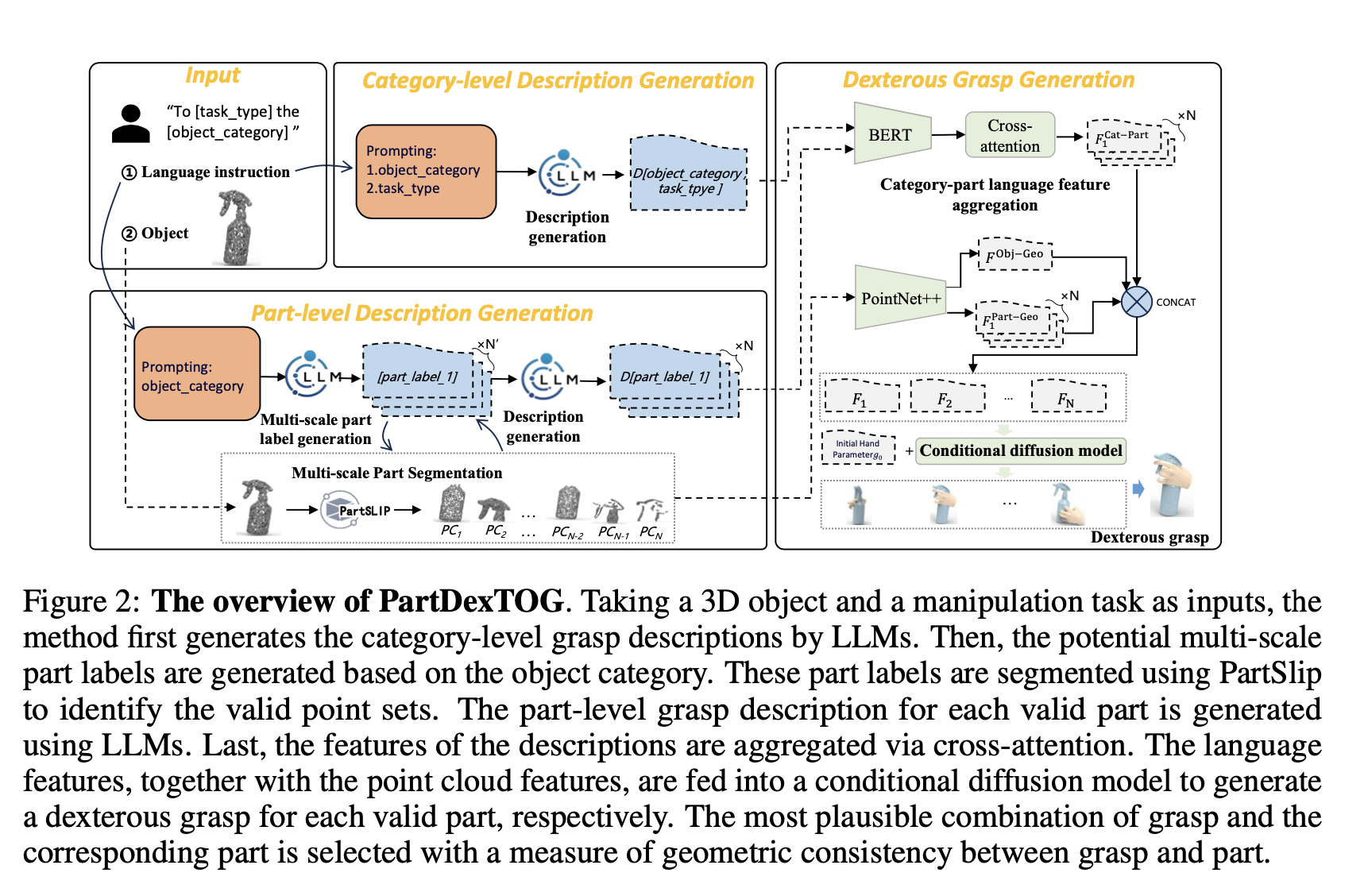
- 3D 객체와 언어로 표현된 조작 작업을 입력으로 받아, dexterous TOG 를 생성하는 프레임워크
- Category-level description 과 Part-level description 을 먼저 생성하고, 이를 Conditional diffusion model 의 입력으로 전달하여 Dexterous TOG 를 생성하게 됨
Category-level grasping description
- 기존 알고리즘들은 의미론적 표현을 생성하여 객체의 카테고리와 작업의 유형 간의 대응 관계를 설정함
- 이러한 방법은 폐쇄적으로만 작동함, 즉 학습 단계에서 명시적으로 정의하거나 학습한 객체 카테고리나 작업 유형만을 다룰 수 있음. 따라서 일반화 성능이 제한적임
- 이러한 한계를 극복하기 위해 자연어로 된 description 을 LLM 이 작성하도록 함
- 사람은 객체가 어떤 유형(category)인지만 알아도 그 물건을 어떻게 쥐어야하는지 상상할 수 있음 → category 가 중요한 정보로 작용할 수 있을 것
- 객체의 유형과 작업의 유형을 모두 고려하는 프롬프트를 LLM 의 입력으로 전달하여 카테고리에 맞는 파지 방법을 설명하도록 함
Part-level grasping description
- part-level grasping description 은 LLM 으로부터 얻은 파지 지식을 객체의 기하학적 특성과 연결함
- 이를 위해 먼저 category-wise multi-scale part label 을 생성하고, part segmentation algorithm 으로 입력 객체에 해당 part label 이 존재하는지 확인함. 끝으로 LLM 을 사용하여 part level description 을 생성함
- Multi-scale part label generation
- 가시성, 기능성, 일반성 등을 고려하여 잠재적인 part label 을 생성함
- Part segmentation.
- PartSLIP 알고리즘을 사용하여 part segmentation 을 수행함
- PartSLIP 은 point cloud set 을 생성함
- Description generation
- 각 파트에 대한 설명을 생성하는 단계
- 이때, 작업 유형 정보는 입력으로 전달하지 않음 → 일반화 성능 향상