- Published on
This Week I learned 8
Summary
1. [Paper] Grasp as You Say: Language-guided Dexterous Grasp Generation
2. [Paper] GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
3. [Paper] RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
4. [paper] DexGrasp Anything: Towards Universal Robotic Dexterous Grasping with Physics Awareness
[Paper] Grasp as You Say: Language-guided Dexterous Grasp Generation
Concept
- 풀고자 하는 문제: Dexterous Grasp as You Say(DexGYS)
- Dexterous Grasp 란 높은 자유도(DoF)를 갖는 로봇 손을 사용하여 파지하는 것을 의미
- 자연어로 된 사람의 명령에 따라 로봇이 물체를 쥘 수 있도록 하는 테스크
- DexGYSNet 데이터셋 제안
- 자연어로 된 사람의 가이드를 포함하는 관련 데이터셋이 없음 → 데이터셋 제안
- DexGYSGrasp 프레임워크 제안
- 사람의 의도를 반영한 고품질의 다양한 형태의 grasp 를 수행할 수 있는 프레임워크
- grasp distribution 을 학습하는 컴포넌트와, grasp 의 품질을 향상시키는 컴포넌트로 구성됨
DexGYSNet Dataset
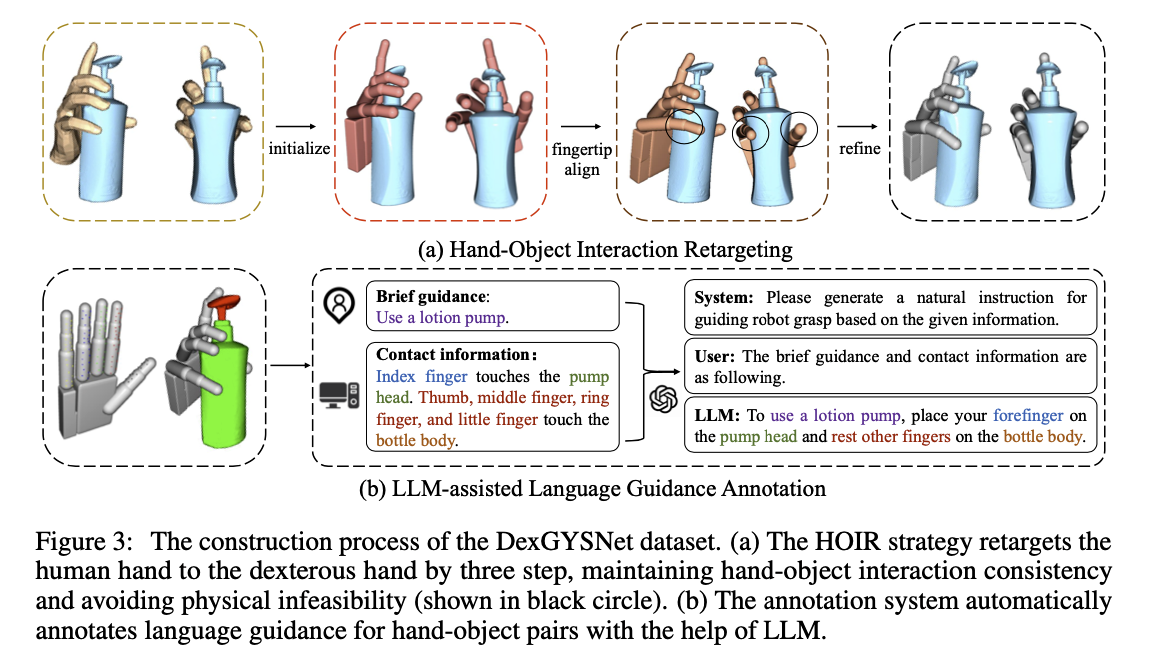
- 데이터셋 생성은 다음 세 가지 과정을 거침
- 다른 데이터셋에서 object mesh 와 human grasp 데이터를 추출함
- Hand-Object Interaction Retargeting(HOIR) 를 활용하여 human grasp 를 dexterous grasp 로 변환함
- LLM-assisted Language Guidance Annotation System 을 활용하여 language guidance 를 생성함
Hand-Object Interaction Retargeting(HOIR)
- 위 그림의 (a)
- 사람 손-객체 상호작용 데이터를 로봇 손-객체 상호작용 데이터로 변환하는 데에 사용
- 여기서 는 dexterous pose 를 의미
- rotation 은 global rotation 을 의미함
- translation 이란 로봇 손이 3차원 공간(world coordinates) 에서 어디에 있는지를 나타내는 위치 정보를 말함(로봇 손 기준점의 위치)
- 는 -DoF 차원의 손목 관절 각도를 뜻함
- 세 가지 step 으로 구성
- Pose Initialization
- 사람의 손 포즈 데이터를 카피하여 초기 dexterous pose 를 생성하는 단계
- dexterous pose 의 파라미터를 사람 손의 포즈를 고려하여 초기화
- Fingertip Alignment
- 손가락의 끝 위치를 조정하여 사람의 손과 유사하도록 개선하는 단계
- 사람의 Fingertip 위치 와 dexterous pose 의 Fingertip 위치 를 맞춰주는 식으로 개선
- Objective Function:
- Interaction Refinement
- 일관성을 유지하면서 물리적 상호작용의 실현 가능성을 높이는 단계
- 손-객체 상호작용 데이터와 물리적 제약 조건을 고려하여 최적화 진행
- 최적화된 자세의 접촉 영역이 step 2의 결과와 일관되도록 함 + 손의 기준점(translation)을 고정함 → 접촉 영역 유지 + 회전과 관절 각도만을 조정하는 단계
- Objective Function:
- : 손-객체 침투 깊이에 대한 페널티
- : 손의 다른 부분 간의 자체 침투에 대한 페널티
- : 로봇 손의 물리적 구조 제한(지정된 상한 및 하한)을 벗어나는 관절 각도에 대한 페널티
- : 객체 위의 접촉 맵이 2단계의 출력과 일관되도록 보장
- Pose Initialization
LLM-Assisted Language Guidance Annotation
- coarse-to-fine automation
- 다음 두 논문에서 영감
- Anyskill: Learning open-vocabulary physical skill for interactive agents
- Semgrasp: Semantic grasp generation via language aligned discretization.
- 세 단계로 구성
- 객체의 카테고리와 사람의 간략한 의도를 기반으로 간략한 가이던스를 생성함
- 사람의 의도 예시: “use a lotion pump”
- human dataset(Oakink) 에서 수집한 정보들임
- 손 위의 접촉 앵커(contact anchors)와 객체의 다양한 부분(different parts of the object) 간의 거리를 구해 contact information 을 컴파일함
- 접촉 앵커는 손 위에 미리 정의된 지점들 - 거리 계산의 기준 점
- 1 에서 생성한 간략한 가이던스와 2에서 생성한 contact information 을 GPT3.5 로 자연어 가이던스 주석으로 생성함
- 사용한 프롬프트는 다음과 같음
- 객체의 카테고리와 사람의 간략한 의도를 기반으로 간략한 가이던스를 생성함
System Prompt: "You are an assistant in creating language instruction, aimed at guiding robot on how to grasp objects. Given a brief instruction and a fine-gained interaction information. Your task is generate a natural and more informative instruction. The instruction should start with the given brief instruction, which is limited in a sentence and about 10-15 words."
User Prompt: "Brief instruction: To <brief intention> a <object category>. Hand-object interaction information: <contact information>. "
DexGYSGrasp framework
- 객체의 전체 point cloud 와 language guidance 가 입력으로 주어져 있을 때, 의도에 맞게 dexterous grasp 를 생성하는 것이 목표
- intention alignment, high diversity, high quality
Objectives
- 일반적으로 사용하는 penetration loss 를 높이는 것은 object penetration 은 줄여주더라도 다른 사이드 이펙트들이 있었음 → 두 개의 Objectives 를 추가함
- First Objective - Generative: 퀄리티보다는 사람의 의도와 생성 다양성에 맞춰 grasp distribution 을 학습함
- Second Objective - Regressive: 간략한 grasp 를 의도는 유지하며 높은 수준의 grasp 로 정제함
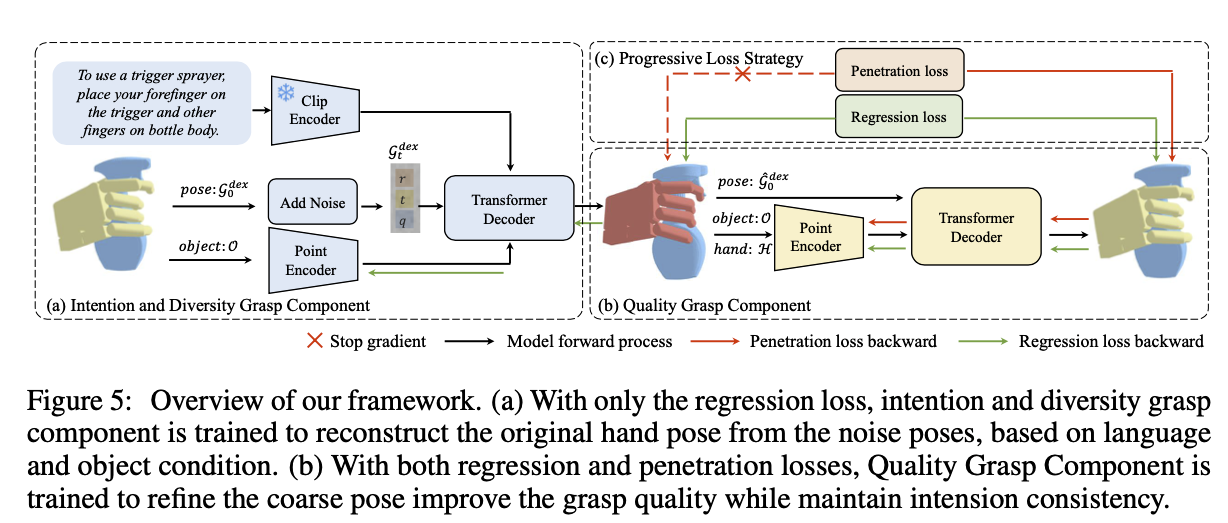
Progressive Grasp Components
- 다음 두 component 로 구성
- Intention and Diversity Grasp Component(IDGC)
- 의도에 맞춰 다양한 손 동작을 생성하는 Grasp distribution 을 효율적으로 배우는 것을 목표로 함
- conditional diffusion model 을 사용하여 노이즈가 추가된 로부터 dexterous pose 를 예측함 - due to distribution modeling objective(?)
- Object Point Cloud 는 Pointer++ 로 encoding
- instruction 은 CLIP 으로 encoding
- sampling process 로 DDPM 을 사용함
- Quality Grasp Component
- IDGC 로 생성된 grasp 는 객체를 관통하는 등 질적으로 좋지 못함
- 입력으로 Coarse Pose , Coarse hand point cloud , Object Point Cloud 를 받음
- 출력으로 자세 변화량 을 내놓음. 이를 통해 개선된 grasp 를 구할 수 있음
Progressive Grasp Loss
- loss function 도 두 가지로 구성됨
- Intention and Diversity Grasp Loss
- regression loss 는 사용하고, penetration loss 는 배제함 - penetration loss 는 품질 향상과 관련, 여기서 포함시키면 다양한 포즈 생성에 어려움을 겪음
- loss function 을 보게 되면, 예측한 손 모양이 정답과 유사해지도록 학습이 이뤄짐
- 는 l2 loss(MSE) 로 손이 가지는 파라미터의 차이를 계산한 것 → 손의 파라미터가 얼마나 유사한가
- 는 hand point cloud 의 예측과 정답 간의 차이를 계산한 것 → 손 모양이 얼마나 유사한가
- 이때 point cloud 는 Hand mesh 를 샘플링해서 얻어짐
Quality Grasp Loss
- penetration loss 를 포함하여 생성된 손 모양을 질적으로 개선하도록 Loss 를 구성함
- : 위와 동일
- : 위와 동일
- 은 손이 객체를 관통한 깊이를 계산한 것 → 객체를 관통하지 못하도록
- : 객체 위의 예측된 접촉 맵과 목표 접촉 맵 간의 차이를 계산한 것 → 목표와 유사한 곳에 손이 닿도록
- 은 손의 부분 간의 관통한 깊이를 계산한 것 → 다른 손도 관통하지 못하도록
Experiments
metric
- intention consistency
- FID(Frechet Inception Distance) 로 생성된 hand 와 정답을 비교함
- CD(Chamfer Distance): 예측된 손 Point cloud 와 정답 손 Point Cloud 간의 거리 측정
- Con(Contact Distance): 예측된 객체 접촉 맵과 정답 접촉 맵 간의 L2 거리 측정
- grasp quality
- Success Rate: Issac Simulator 환경에서 안정적으로 물체를 잡는 데에 성공했는지 여부
- Q1: 접촉 임계값 1cm, 관통 임계값 5mm 로 설정하고 Grasp 의 안정성 측정
- 다음 논문 참고 - Planning Optimal Grasps
- Maximal Penetration Depth: Point Cloud 에서의 최대 관통 깊이
- grasp diversity
- 동일한 입력으로 8개의 출력 생성, 각 샘플 간의 transition, rotation, joint angle 의 표준편차 계산
- 다양성이 높을 수록 좋음 - 인간의 명령이 구체적이지 않을 가능성이 높은 만큼 여러 가지 가능성이 높은 파지를 제안할 수 있어야 함
[Paper] GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
Concept
- 자연어로 된 Instruction 과 하나의 RGB-D frame 이미지를 받아 의미적으로 적절한 grasp 를 예측하는 모델 GraspMolmo 를 제안함
- “Pour me some tea” → teapot 의 body 가 아닌 handle 을 잡음
- 단순하고 부족한 양의 기존 데이터셋 문제를 극복하기 위해 GraspMolmo 는 PRISM dataset 을 제안함 + 이를 활용해 VLM 모델을 파인튜닝함
- PRISM - 다양한 환경에 대해 복잡하고 현실적인 task description 을 포함하는 데이터셋
- Hand 가 아닌 7-DoF 의 Gripper 를 사용함
Generation of PRISM-Train and PRISM-Test
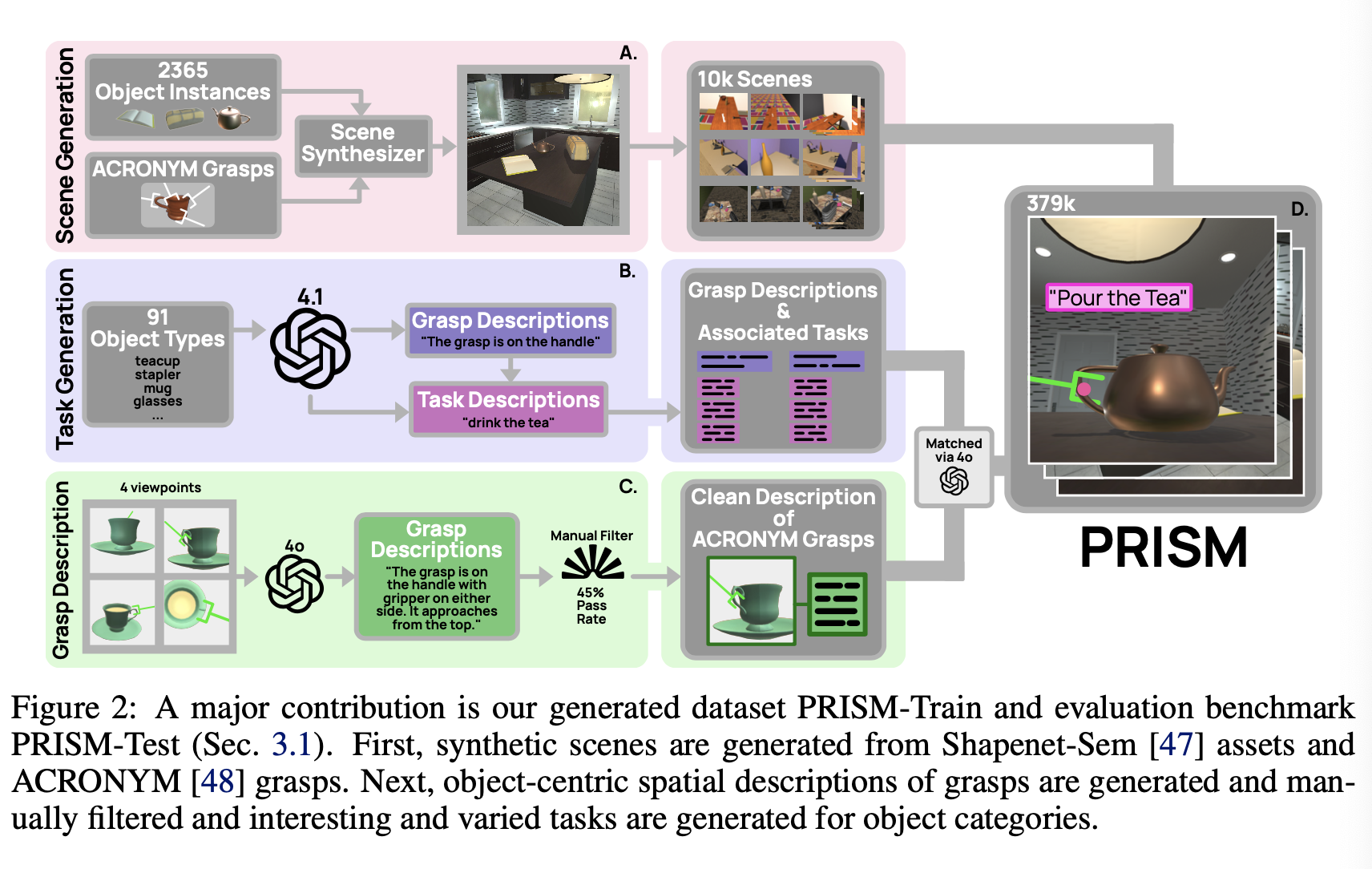
- ShapeNet-Sem, ACRONYM 데이터셋을 사용함
- Scene Generation
- 다양한 각체에 대해 조명과 카메라의 위치를 변경해가며 렌더링하여 수집
- Grasp Description as a Bridge
- task-object-grasp triple 에 대해 주석 처리가 되어야 한다는 점에서 어려움
- description 을 task 와 grasp 간의 bridge 로 사용함 → 공통된 구조를 최대한 활용하여 해소
- 머그컵에서 물을 마시는 것과 머그컵에서 물을 따르는 것은 grasp 동작의 관점에서는 동일함
- 객체-그립 쌍에 대해 그립이 객체를 어떻게 잡고 있는지에 대한 자연어 주석 추가 + 각 작업에 대해 작업을 완료하기 위해 객체를 어떻게 잡어야하는 지에 대한 설명 작성 → “객체-그립 쌍” 에 맞는 “작업 설명” 을 연결하면 task-object-grasp triple 이 생성됨
- Grasp Description Generation
- GPT-4 사용하여 잡히고 있는 객체의 여러 시점(viewpoints)이 주어졌을 때 합성 그립 설명을 생성
- 55% 정도는 사람이 수동으로 편집을 해야했음
- Task Generation
- GPT-4.1에 프롬프트를 입력하여 manipulation task 에 대해 최대한 다르면서도 여전히 그럴듯한 두 가지 그립 설명을 생성하도록 함
- 다음으로 GPT-4.1은 각 그립에 대해 네 가지 유효한 의미론적 작업을 생성함
- 총 91개 객체 클래스 각각에 대해 두 가지 그립에 해당하는 728개의 고유한 작업이 생성
- Matching Tasks to Grasps
- GPT-4o를 사용하여 각 객체-그립 쌍에 대해 생성된 그립 설명을 생성된 작업의 설명과 매칭시킴
- LLM이 씬에 있는 기존 그립 중 하나가 생성된 설명과 일치한다고 결정하면, 해당 작업은 task-object-grasp triple 을 생성하고 데이터셋에 추가됨
- PRISM-Train은 2,356개의 고유한 객체에 걸쳐 9,424개의 고유한 객체 중심 그립 인스턴스를 포함함
TaskGrasp-Image
- TaskGrasp 는 Task-Oriented grasping 분야의 대표적인 데이터셋
- 안정적인 집기 포즈에 대한 partial point cloud 로 구성됨 + task 에 대한 레이블이 작업 동사(scoop, cut, …)로 되어 있음
- point cloud 의 단점 - self-occlusions, segmentation artifacts (?)
- 단일 동사로 구성된 레이블의 한계
- TaskGrasp 에서 파생된 이미지 기반 데이터셋 TaskGrasp-Image 제안
- point cloud 대신에 RGB-D 이미지들로 구성됨
GraspMolmo
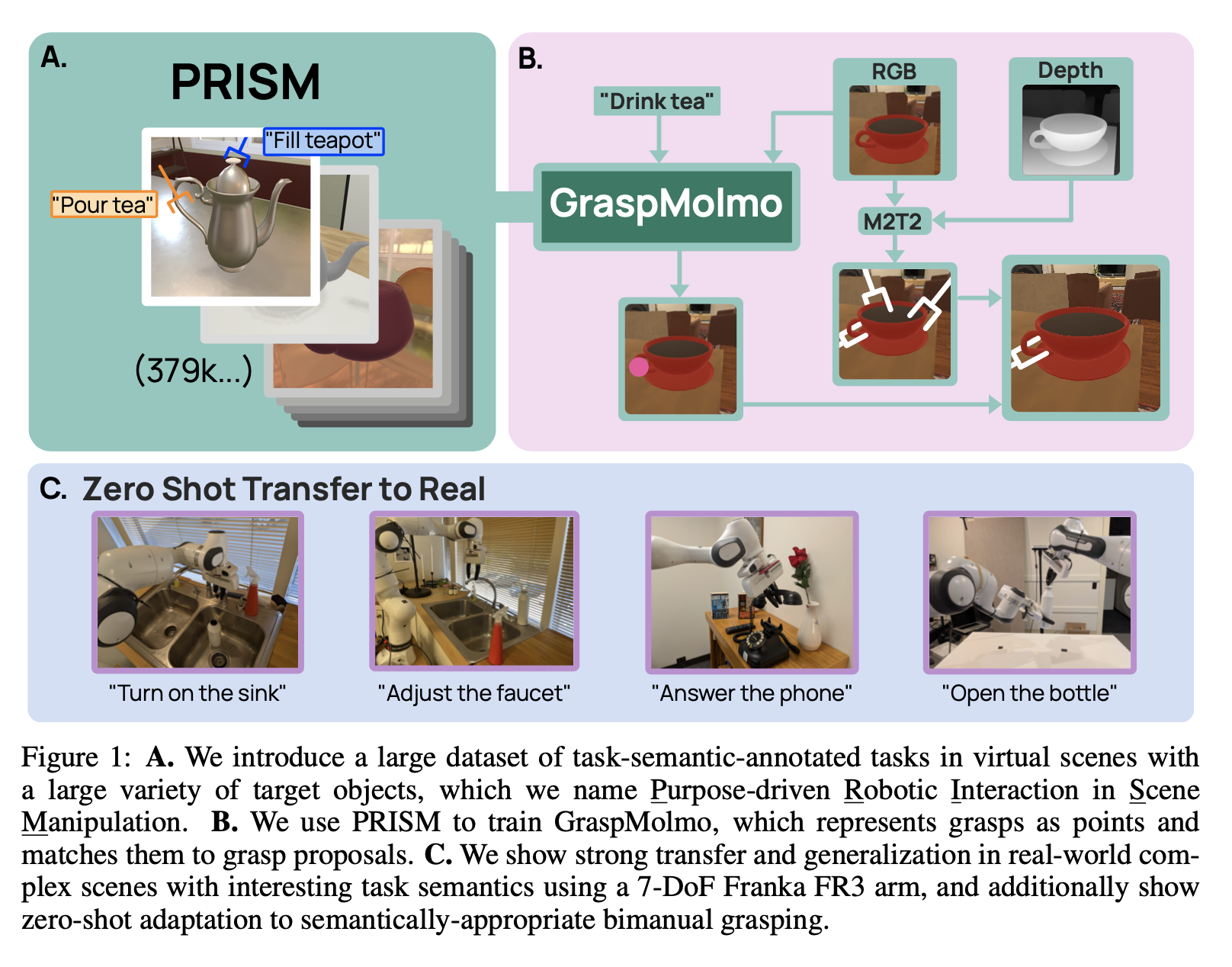
- VLA 모델 Molmo 를 PRISM-Train 과 TaskGrasp-Image 로 파인튜닝하여 GraspMolmo 를 만듦
- 일반화 성능 유지를 위해 Molmo 학습 시 수행한 작업들도 함께 학습함
- CoT 를 적용하여 모델이 파악한 픽셀의 위치와 그에 대한 객체 중심 설명을 출력하도록 함
- GraspMolmo 는 이미지 평면 상의 포인트를 출력함
- 이때 평면 상의 2D 포인트를 3d point cloud 로 곧바로 전환하지는 않음 - 최단 거리로 찾을 수는 있으나, depth 정보가 충분하지 않은 상태에서 사용하면 작은 오차가 매우 커질 수 있음
- 대신에 모든 candidate grasp 를 pixel space 로 변환하고, 그 중 가장 가까운 포인트를 매칭함 - 앞서 언급한 문제의 완전한 해결책은 아니나, 적절치 않게 어려지는 grasp 는 줄일 수 있음, recall 이 올라감
Experiment
- Settings
- Prompt
- Training: “Point to the grasp that would accomplish the following task:
<task>” - Evaluation: “Point to where I should grasp to accomplish the following task:
<task>”
- Training: “Point to the grasp that would accomplish the following task:
- VLA model: Molmo-7B-D-0924
- GPU: 64개의 Nvidia H100 GPU
- Prompt
[Paper] RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
Concept
- LLM 의 강력한 추론 능력을 robotic grasping 테스크에 적용하는 방법
CNN vs Multi-Modal vs RT-Grasp
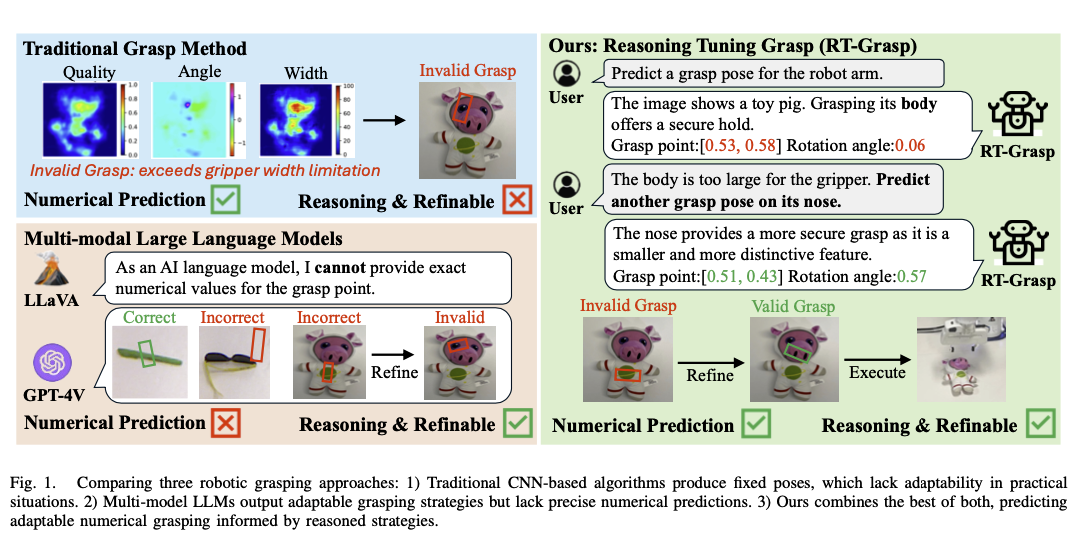
- CNN 기반의 알고리즘은 scene understanding 능력이 떨어짐
- 무엇을 잡고 았는지 알지 못함 + 왜 잡아야 하는지 알지 못함 → 입력을 명시적이고 구체적으로 줘야 함(lack of adaptability)
- Multi-Modal 기반의 알고리즘은 정밀한 예측 능력이 떨어짐
- numerical prediction 에서 좋지 않은 성능을 보임
- 이러한 이유로 high-level planning 에서 주로 사용되어옴
- RT-Grasp
- 추론된 전략에 기반해 적응 가능하고 정밀한 수치적 그립을 예측함
- 두 가지의 단점을 보완한 방법
Method Overview
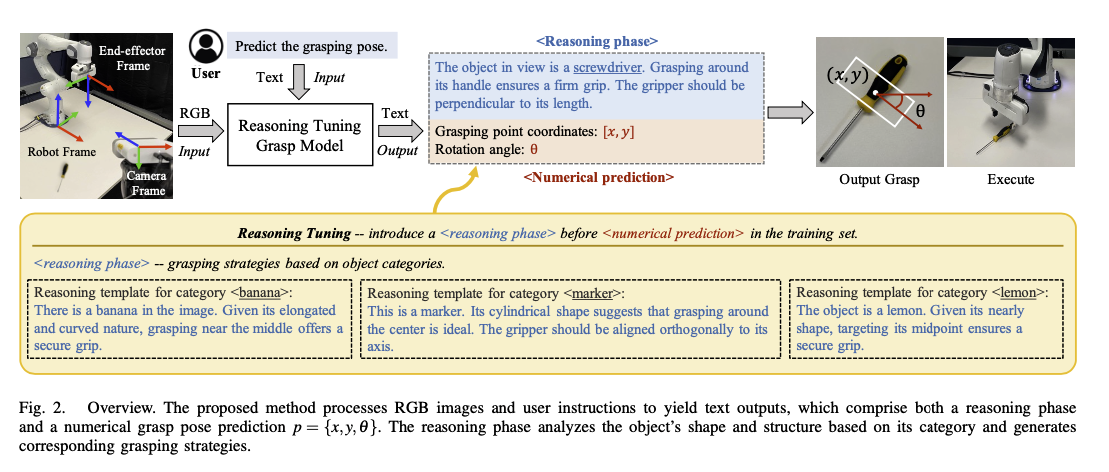
- LLaVA 에 LoRA 를 적용하여 파인튜닝
- 모델은 RGB 이미지와 자연어 명령을 입력으로 받아 적절한 추론을 거친 뒤 Grasp Point Coordinates 와 Rotation angle 을 반환해 Gripper 가 잡을 위치와 각도를 알려주게 됨
- Reasooning Tuning 제안
- 출력을 Reasoning phase 와 Numerical prediction 을 가지는 structured form 으로 만듦
- 모델의 Reasoning 성능을 끌어올리고, Coordinate 와 angle 등 수치 예측의 정확도를 높이기 위함임
[paper] DexGrasp Anything: Towards Universal Robotic Dexterous Grasping with Physics Awareness
Concept
- dexterous hand 의 높은 DoF 로 인해 다양한 객체에 대해 높은 수준의 grasping 을 구현하이 어려웠음
- diffusion-based generative model 에 물리적인 제약조건을 통합하여 기존에 동 모델이 가지는 문제들을 해소하는 Dex-Grasp Anything 프레임워크를 제안함
- Diffusion model 기반 방법들은 적절한 물리적 제약 조건이 없을 때 좋은 결과를 생성하지 못하는 경우가 많았음 → Physical Constraint 와 관련된 term 을 objective 에 더해주어 학습할 수 있도록 함
- 주어진 객체를 안전하게 쥐는 grasping pose 를 생성하는 것을 목표로 함
Method Overview
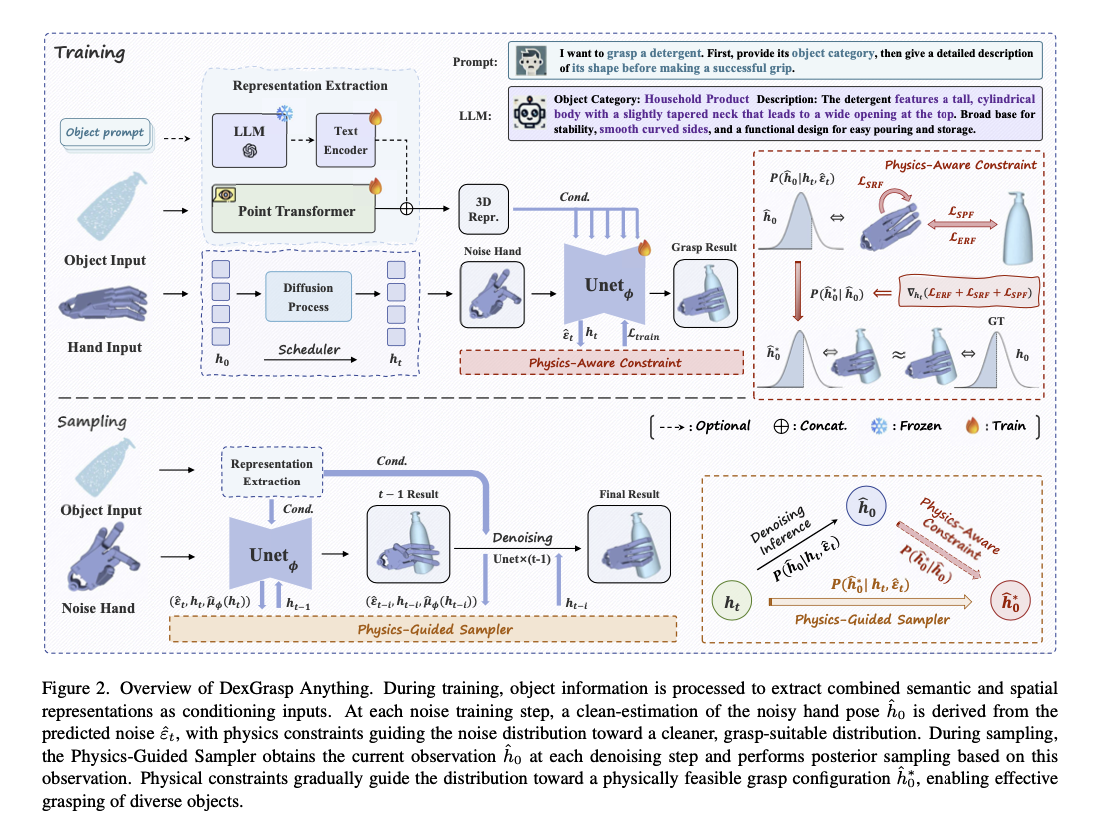
문제 정의
- 어떤 3D 객체에 대한 관측 가 주어졌을 때 다양한 dex-grasping pose 를 샘플링할 수 있는 조건부 확률 분포 을 만드는 것을 목표로 함
- 이때 은 다음과 같이 구성됨
- 손의 관절 움직임: (ShadowHand 기준)
- 전역 회전:
- 전역 이동 벡터:
- 는 diffusion model 로 모델링
물리적 제약 조건
- Diffusion model 기반 방법들은 적절한 물리적 제약 조건이 없을 때 좋은 결과를 생성하지 못하는 경우가 많았음
- 세 가지 물리적 제약 조건을 도입함
- Surface pulling force: 손가락 관절과 물체 사이의 근접성을 높혀 그립의 실현 가능성을 높임
- External-Penetration repulsion force: 손과 물체 간의 충돌 방지를 위해 포인트 클라우드 간의 교차 최소화
- Self-Penetration repulsion force: 손의 부분별 충돌을 방지하여 손의 기하학적 구조 유지 목표
Physics-Aware Training
- diffusion generator 가 학습을 진행하는 도중에 physics prior 를 포착할 수 있도록 하기 위해 Physics-Aware Training Paradigm 을 도입함
- 다음 식과 같이 MSE objectice 에 앞에서 살펴 본 세 가지 physical constraint objective 를 더하는 식으로 objective function 을 정의함
Physics-Guided Sampling
- 물리적으로 그럴싸한 Dex-Grasph 를 생헝할 수 있는 모델에서 좋은 샘플을 만들어내는 방법
- Classifier guidance 방법에서 착안
LLM-enhanced Representation Extraction
- LLM 으로부터 의미론적 지식(semantic prior)로 보완하는 과정을 거침
- 기하학적 특징 추출
- Point Transformer 사용 →
- LLM 을 통한 의미론적 특징 강화
- 다음과 같은 프롬프트 사용: “I want to grasp a [object label]. First, provide its object category, then give a detailed description of its shape before making a successful grip.”
- 세 가지에 대한 질문 → 여러 문장으로 답변이 생성됨
- 각 문장에 대해 BERT-large-uncased 모델 적용하고, 매 문장의 의미론적 표현을 담고 있다고 할 수 있는
CLS토큰 추출 - 추출된 CLS 토큰들 에 max-pooling 적용 →
- 두 벡터를 concat → N + 1) \times C$$
- 크로스 어텐션을 적용하여 diffusion backbone 에 통합
- 다음과 같은 프롬프트 사용: “I want to grasp a [object label]. First, provide its object category, then give a detailed description of its shape before making a successful grip.”
- 이를 통해 문맥적으로 적절한 그립 자세를 생성하는 능력을 향상시킴