- Published on
This Week I learned 7
Summary
1. [Paper] PAVLM: Advancing Point Cloud based Affordance Understanding Via Vision-Language Model
2. [Paper] ForceGrip: Reference-Free Curriculum Learning for Realistic Grip Force Control in VR Hand Manipulation
3. [Paper] TEXT2REWARD: REWARD SHAPING WITH LANGUAGE MODELS FOR REINFORCEMENT LEARNING
4. [Paper] EUREKA: HUMAN-LEVEL REWARD DESIGN VIA CODING LARGE LANGUAGE MODELS
5. [Dev] Agentic Design Pattern
[Paper] PAVLM: Advancing Point Cloud based Affordance Understanding Via Vision-Language Model
Concept
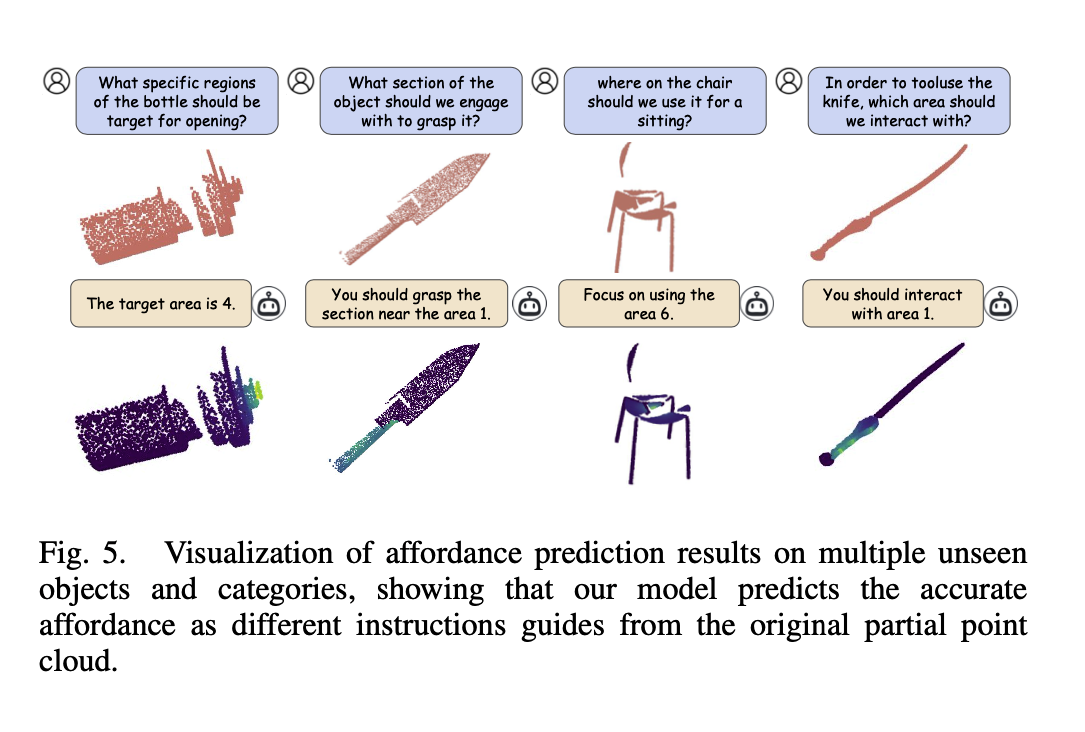
- VLM 은 high-level reasoning 과 long-horizon planning 에 강점, 뉘앙스를 고려한 grasping 에는 어려움을 겪음
- Instruction 과 3D point cloud 가 주어졌을 때, 그에 맞는 영역 masking 하는 task 수행
- PAVLM(Point cloud Affordance VLM) 제안
- 3D affordance understanding of point cloud 에 대한 이해 향상 목표
Method Overview
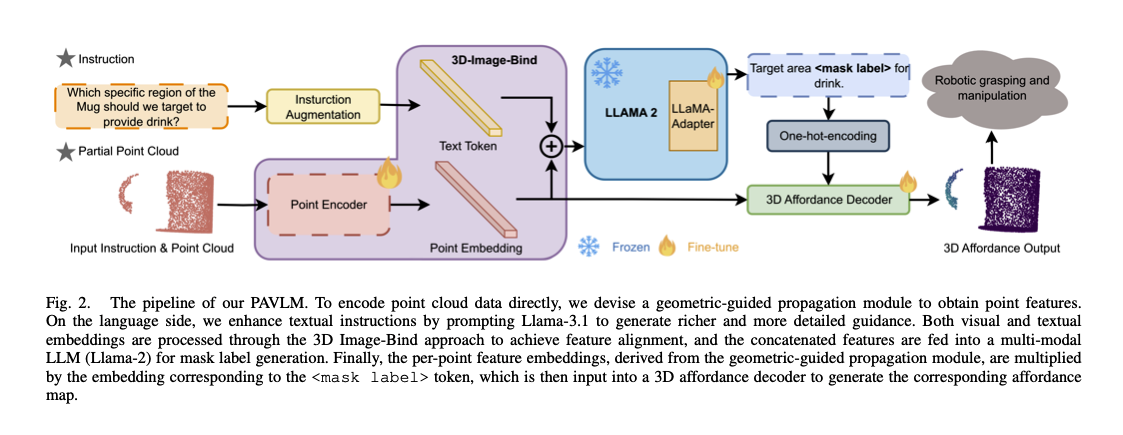
- 입력: point cloud , textual instruction
- 출력: 3D affordance map guided by a
<mask label > - Instruction Augmentation
- Llama-3.1 70B → 시스템의 추론 능력 향상, 깊은 의미론적 단서 확보, point cloud data 와의 얼라인
- AffordanceLLM 에서 영감을 받아 QA approach 적용
- 3D의 특성에 맞도록 설계된 프롬프트로 6개의 QA pairs 를 생성함 → 이를 다음 layer로 전달

- 3D Image-Bind
- Image-Bind, Point-Bind 에서 영감
- Point 임베딩과 Text 임베딩 의 결합 → Multimodal consistency 확보 목표
- poin-paired data 를 Contrastive learning 으로 학습시켜, 3D, text 등을 동일한 Unified representation space 에 위치시키도록 함
- Loss 를 다음과 같이 정의, Point, Text Pair 의 거리가 줄어들도록 함
- Llama-2
- ImageBind-LLM 에서 영감
- LLaMA-Adaptor 를 적용함. feature embedding 을 입력으로 받아 특수 토큰
<mask label>를 출력함- 멀티모달 입력 처리를 위해 LLaMA Adaptor 적용
<mask label>는 다시 18개의 Category(3D AffordanceNet Benchmark)를 가지는 one-hot encoding 되어, query embedding 을 생성하는 데에 사용됨(정확히는 HIdden state 를 사용함)- 왜 Llama-2 와 같은 언어모델을 사용했을까
- LLM 의 멀티모달 지식 활용, LLM 은 point cloud 의 지식을 통합하는 능력을 가지고 있다고 가정(ImageBind-LLM)
- 광범위한 사전 학습 지식과 추론 능력을 활용할 수 있음
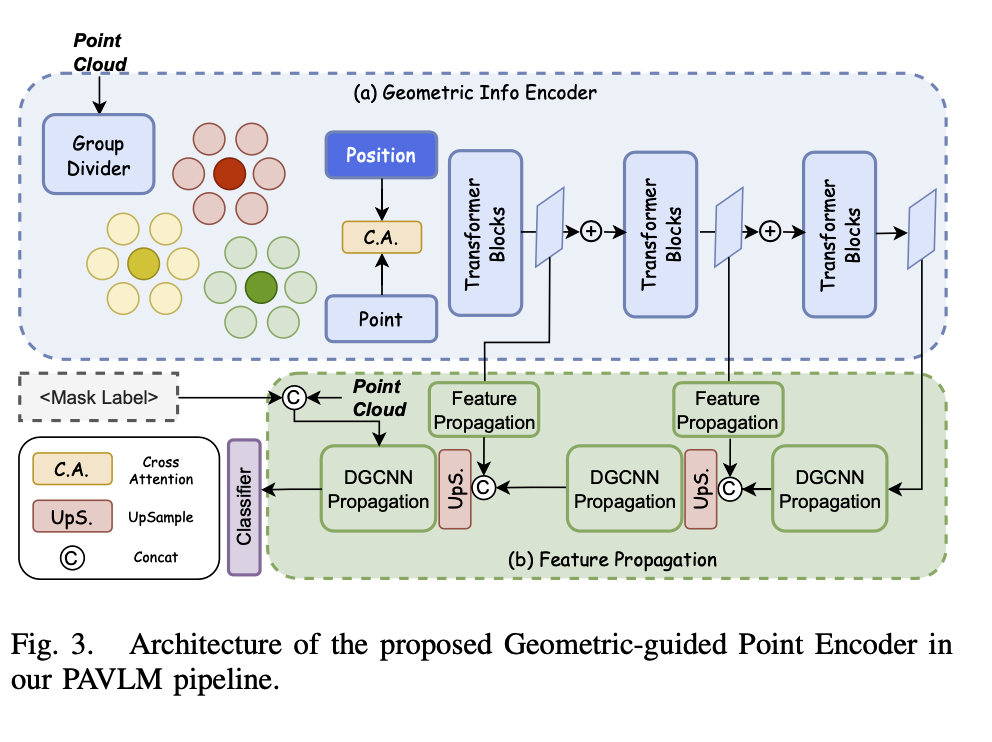
- Geometric-guided Point Encoder
- 두 개의 파트로 구성: Geometric Info Encoder, Feature Propagation
- Geometric Info Encoder
- Point Cloud 에서 정보 추출을 목표로 함
- 2048개의 Point 를 256 개씩 그룹핑 - Point-BERT 에서 영감
- 각 patch 에 대해 Conv layer 를 적용 → point-wise feature 를 추출함 (차원 감소)
- point-wise feature 에 positional embedding 을 더해줌
- 이를 Transformer block 에 입력으로 전달
- 최종적으로 정제된 geometric feature 를 뽑는 것을 목표로 함
- Feature Propagation
- Upsampling 과 DGCNN(Dynamic Graph CNN)을 적용하여 포인트 당 임베딩을 생성함
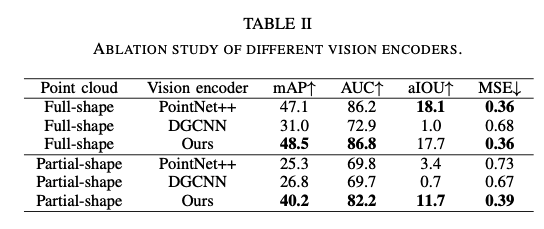
- ablation study
- Geometric-guided Point Encoder 와 다른 cloud-based network (PointNet++, DGCNN) 간의 비교
- mAP, aIOU 등에서 높은 성능을 보여줌
- Geometric-guided Point Encoder 와 다른 cloud-based network (PointNet++, DGCNN) 간의 비교
[Paper] ForceGrip: Reference-Free Curriculum Learning for Realistic Grip Force Control in VR Hand Manipulation
Introduction
- hand tracking 을 사용하지 않는 controller-based interface 가 널리 사용됨
- 기존 방법들은 이진 트리거 입력 여부로 판단 → grip force 의 미묘한 제어를 간과함
- 그런데 이러한 미묘한 제어(nuanced control of grip force)는 VR 로 변환하는 것이 어려움
- 기존 데이터셋이 접촉력, 손가락 토크와 같은 물리적 속성을 포함하지 않고 있기 때문
- ForceGrip 으로 극복
- Controller 의 입력을 현실적인 grip force dynamics 로 변환하는 모델
- 다양한 종류의 객체, 입력 신호 값, 손목 움직임을 가지는 다양한 시나리오들을 임의로 생성하여 학습에 사용
- 커리큘럼 학습 적용: Finger Positioning, Intention Adaptation, Dynamic Stabilization 의 세 phase 로 구성
- proximity-based reward: 모션 데이터를 참조하는 것이 아니라 근접 기반 보상을 통해 자연스러운 손 움직임을 구현함
- 세 가지 Contribution
- Reference-free training: 참조 데이터 없이 학습 진행
- User-controlled grip force: 사용자의 grip force 를 자연스러운 손 동작으로 표현
- Effective curriculum learning: 커리큘럼 학습을 통해 복잡성이 높은 VR 에서의 손 동작 표현을 학습함
Framework
- Unity + Nvidia PhysX 로 물리 시뮬레이션 환경 구현
- 시뮬레이터는 120Hz 로, 에이전트는 30Hz 로 동작
- 매 time step 마다 에이전트는 손가락 관절의 토크를 출력함 → PD(proportional-derivatvie) controller 가 실제 손의 포즈로 변환
- 훈련 중에는 사전에 정의된 손목의 경로를 따름 → 실제 사용 시에는 VR 컨트롤러의 움직임을 따름
- 다양한 객체, 사용자 입력, 손목의 움직임을 가지는 다양한 시나리오를 생성하여 학습에 사용
- 시나리오의 다양성이 너무 높으면 학습에 이려움 → 커리큘럼 러닝 도입
- PPO 알고리즘을 적용하여 학습, 576 개의 에이전트를 서로 다른 seed 로 동시에 실행
- 객체로부터 손목이 10cm 이상 멀어지면 early termination 적용 - https://arxiv.org/pdf/1804.02717
Hand Model and Objects
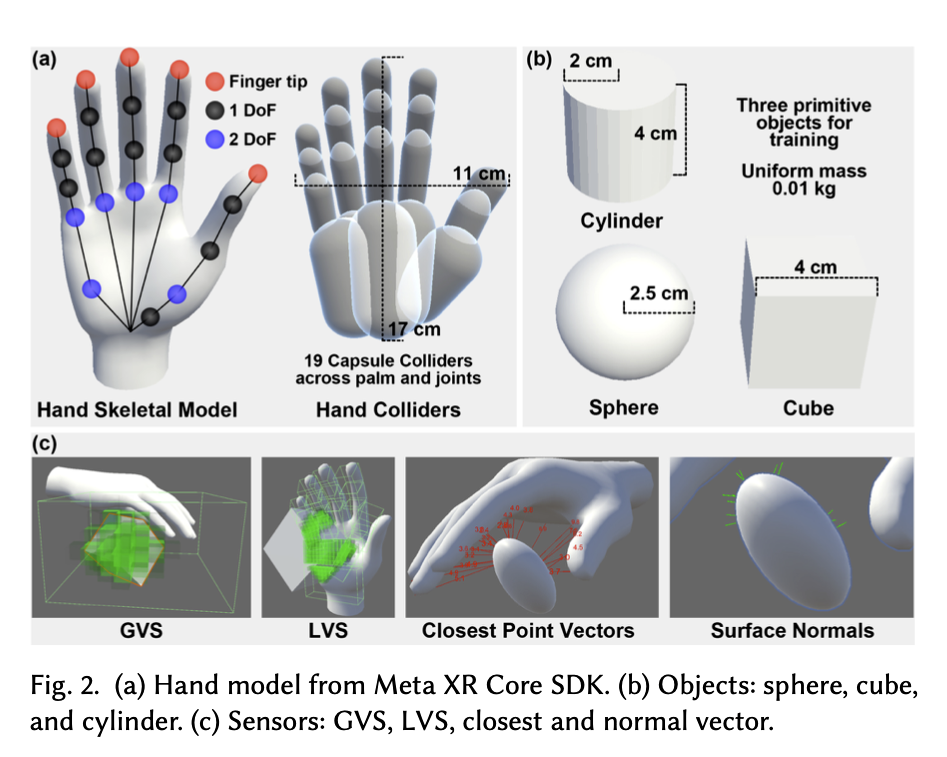
- Hand Model: MetaXR Core SDK 의 hand model 을 사용함
- 17 개의 손가락 조인트, 23 DoFs, 19개의 non-self-colliding capsule colliders
- collider 란, 손 모델의 물리적인 경계를 정의하고, 객체와의 접촉 및 충돌을 감지하는 역할 수행
- Objects
- Sphere, Cube, Cylinder 의 세 가지로 구성, 0.01kg 의 균일한 질량을 가짐
- 질량이 많으면 물건을 자주 떨어뜨림 → 과도하게 조기 종료되는 문제를 방지하기 위해 질량을 최소화
State, Action, Reward
- State 는 총 3023 개의 차원으로 구성, hand model, object, task 에 대한 정보로 구성됨
- Hand Model Information = joint position(66), joint DoF angle(23), joint linear velocities(51), joint DoF velocities(23), joint DoF acceleration(23) 으로 구성
- Object Information = gravity vector in wrist coordination(3), global voxel sensor(450), local voxel sensor(2160), closest point vector(69), surface normals(69)
- Task-related information = current force vector(57), user trigger signal history(6), prev action(23)
- Action 은 23개의 차원으로 구성, 손가락 관절에 대한 토크(torques) 값을 의미함
- Reward 는 두 가지로 구성됨 - force reward + proximity reward
- force reward
- : collider 별 force vector
- : 최대 그립 힘으로 여기서는 10kgf
- : 최근 6프레임 동안의 평균 트리거 신호
- 즉, 사용자의 입력에 따른 target force 와 실제로 충돌체가 가지는 힘이 비슷할수록 보상이 커지도록 구성
- proximity reward:
- : 번째 관절에서 객체의 표면까지의 거리 벡터
- : 가중치 - 손가락의 끝의 경우 0.0625, 이외의 경우 0.03125
- 1cm 이내에 있는 관절/손가락의 끝은 가중치 합산 전에 0.9 이상의 보상을 얻게 됨 → 자연스러운 접촉 장려
- total reward:
- 모든 물체를 항상 들어 올릴 수 있도록 보장하는 것이 아니라, 오직 사용자가 의도한 힘을 충실하게 반영하는 것을 목표로 함
- 힘의 부족하여 놓치는 경우에는 자연스러운 결과로 간주함
- force reward
Training
- 90프레임으로 구성된 3초짜리 트레이닝 시나리오들을 생성함
- 트레이닝 시나리오 구성 시 고려한 세 가지 Key factor
- Object randomization
- 객체의 크기를 x,y,z 축에 따라 0.5~1.5 의 계수로 임의로 변경함
- 손 앞에 미리 정의된 공간 상에 무작위로 위치가 결정됨
- 처음 0.5 초 간에는 객체의 안정화가 수행됨
- kinematic 상태로 렌더링 됨(물리적 힘의 영향을 받지 않음)
- 미끄러짐 없이 객체에 접근하여 포즈를 안정화하기 위함
- Trigger variation
- Sin 함수와 Gaussian noise 를 섞어서 잡음이 있는 트리거 신호 합성 → 오버 피팅 방지
- Write movement
- 객체의 안정화 이후, floor 를 제거하고 무작위적인 손목 가속도, 각 가속도를 각 물리 시뮬레이션 단계마다 도입함
- Object randomization
- Curriculum learning
- 세 개의 페이즈로 구성됨, 점진적으로 더욱 역동적이고 현실적인 조건을 처리하도록 구성
- Finger Positioning
- 객체 무작위화만 진행됨, 손목의 움직임과 트리거는 고정
- 충돌 처리 및 초기 그립 형성과 같은 기초적인 행동을 학습
- Intention Adaptation
- 트리거 변동을 추가함
- 에이전트는 변동하는 트리거 신호를 해석하여 그에 맞는 힘을 적용할 수 있도록 학습
- Dynamic Stabilization
- 손목 움직임까지 추가함
- 중력 및 관성력이 변화할 때에도 그립을 잃지 않고 접촉 힘을 보존하는 방법을 학습
[Paper] TEXT2REWARD: REWARD SHAPING WITH LANGUAGE MODELS FOR REINFORCEMENT LEARNING
- ICLR 2024
- https://arxiv.org/pdf/2309.11489
Concept
- Reward function 을 디자인하는 것은 domain knowledge 를 필요로 한다는 점에서 비용이 많이 듦
- TEXT2REWARD 는 Data 없이 LLM 을 활용하여 dense reward function 을 생성해줌
- inverse RL, LLM as a sparse reward code 등과 차별화
- 해석 가능하다는 점, 자유로운 dense reward code 를 가지는 점, 다양한 테스크에 대응할 수 있다는 점, 사람의 피드백을 포함시킬 수 있다는 점이 장점
- 여러 벤치마크에 적용함
- 두 개의 로보틱스 벤치마크: MMANISKILL2, META-WORLD → 13/17 개에서 전문가가 작성한 reward function 보다 비슷하거나 더욱 높은 성능을 보임
- 두 개의 보행 환경: MUJOCO → 94% 의 성공률을 보임
Background
- Reward code
- 말 그대로 진짜 Code, Python 코드 같은 것을 말함 - 주어진 목표에 따라 상황에 맞춰 보상을 계산할 수 있는 실행 가능한 프로그램 정도로 정의 가능 → LLM 이 상황에 맞게 reward 를 계산하는 code 를 생성함
- reward functoin 은 neural net 이나 reward code 조각과 같은 다양항 형태를 취할 수 있음
- 논문에서는 reward code 에 초점을 맞춤 → 해석 가능성을 높이기 위함
- Reward function
- task 가 완료될 때에만 보상을 받는 sparse, delayed reward 는 학습을 어렵게 하는 원인 중 하나임
- reward code 형태로 보상이 주어지면 각 timestep 마다 다른 기능적 형태를 취할 수 있음
- 읽으며 생각난 질문들
- 상황에 따라 서로 다른 reward code 를 사용한다면,
- 매 reward code 로 생성되는 reward 간의 scale 은 어떻게 조절할 수 있는가 - scale 이 일정치 않으면 안정적인 학습이 어려울 것 같음
- Reward hacking 은 어떻게 방지할 수 있을까 - 다음 reward code 로 변경되지 않는 선에서 중간 단계의 reward code 만 exploit 하는 경우
- 상황에 따라 서로 다른 reward code 를 사용한다면,
Overview: Zero-shot and Few-shot dense reward generation
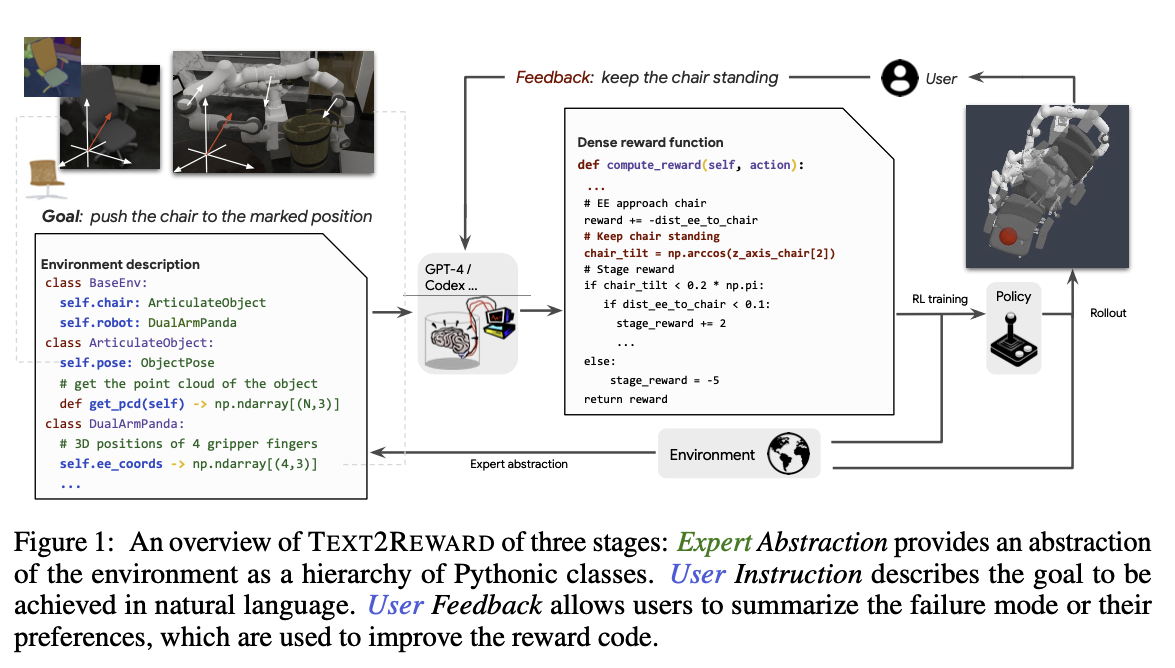
- Instruction
- 자연어 문장 형태로 주어짐 - “Push the chair to the marked position”
- 사용자가 직접 입력할 수도, LLM Planner 가 생성할 수도 있음
- Env AbstractionS
- 환경(로봇, 객체)의 특성과 능력에 대해 LLM 에게 알려주어야 환경에 대한 이해를 높일 수 있음
- LLM 이 익숙한(학습 과정에서 많이 본) 파이썬 코드 형태로 description 을 작성하여 전달함
- Background Knowledge
- dense reward code 를 생성하는 것은 쉬운 일이 아님
- 따라서 환경을 이해하는 데에 도움이 될 만한 추가적인 정보(e.g. Numpy/SciPy functions)를 함께 제공함
- Few-Shot examples
- Instruction - reward code pair 로 이뤄진 pool 을 생성함
- 초기에는 전문가들이 생성, 이후에는 모델에 의해 생성된 Dense reward code 도 추가
- Instruction 이 들어오면 retriever 를 활용해 유사한 Instruction - reward code pair 를 k 개 샘플링
- few-shot example 로 제공함
- Instruction - reward code pair 로 이뤄진 pool 을 생성함
- Reducing error with code execution
- reward code 를 생성하면 일단 돌려봄 → syntax, runtime error error 등을 잡아낼 수 있음
- error 가 확인되면 iterative refinement 를 진행함
- 10% 에러율이 0에 가까워짐
- human feedback
- 인간은 한 번의 상호작용 만으로 정확한 의도를 명시하는 경우가 거의 없음 → 곧바로 사용하는 것보다 개선하는 것이 필요
- Sub-Optimal scenario: task 의 목적은 명확하나 수행 방법이 최적이 아닌 경우 - 캐비닛을 단순히 열라고만 지시하면, “문의 손잡이”를 이용해 캐비닛을 열라고 하지 않고 모서리를 잡아 당겨 열 수도 있음
- Pessimistic Scenario: 달성 방법과 평가 방법이 모호한 경우 - “책상을 치워라”고 하는 것은 모호함. “책상 위의 물건을 집어 올려 선반 위에 올려라”와 같이 중간 목표를 제공하면 더욱 쉽고 명확해짐
- 이러한 문제를 극복하기 위해 human feedback 을 요청함
- RL 트레이닝 사이클이 한 번 끝날 때마다 롤아웃 비디오 제공
- 비디오를 보고 사용자가 피드백을 제공함
- 이후 프롬프트에 해당 피드백을 포함하도록 하여 Reward function 생성 시 반영하도록 함
- 이를 통해 과제의 모호성 문제를 해소할 수 있었음
- 인간은 한 번의 상호작용 만으로 정확한 의도를 명시하는 경우가 거의 없음 → 곧바로 사용하는 것보다 개선하는 것이 필요
Experiments and Results
- Tasks
- Manipulation Tasks: METAWORLD, MANISKILL2
- Locomotion Tasks: MUJOCO(Hopper, Ant)
- Interactive Generation with Human Feedback
- reward code 를 한 번에 생성하기 어려운 Stack Cube 문제와, 모호성이 높은 Ant lie down 문제를 대상으로 실험
- Zero-Shot, Few-shot 으로 각각 생성된 3개의 code 샘플링
- 2 회에 걸쳐 휴먼 피드백 루프 실행
- 이때 사용자는 코드를 직접 볼 수 없고, 롤아웃 비디오와 학습 곡선만 확인
- 3회 미만의 피드백 루프를 통해 성공률을 0에서 거의 100%까지 끌어 올릴 수 있음을 확인
- Few-Shot 이 보다 효율적으로 개선하고 수렴속도도 높았음
- reward code 를 한 번에 생성하기 어려운 Stack Cube 문제와, 모호성이 높은 Ant lie down 문제를 대상으로 실험
- Main Result
- 로봇 조작 테스크
- 로봇 조작 테스크 중 13/17 개에서 인간 Oracle(전문가가 설계한 보상 함수) 과 유사한 성능을 보임
- 4/17 개에서 인간보다 높은 성능(수렴 속도와 성공률)을 보임
- 베이스라인 프롬프트로 생성된 보상 함수 L2R(2023)의 경우 제한적인 테스크에만 적용됨, 제로샷과 유사한 성능을 보임
- 퓨샷을 사용하는 것이 성능이 더 좋았음
- 이동 테스크
- 6개의 이동 작업 전부에 대해 성공함, 94% 이상의 성공률을 보임
- 새로운 이동 행동을 학습하기도 함 → 일반화할 수 있는 Dense reward function 의 생성 가능성 확인
- 실제 로봇 시연에서도 성공적으로 배포 가능함을 확인
- 로봇 조작 테스크
감상
- 정리가 잘 되어있고, 문맥을 따라가기 쉬워 잘 쓰인 논문으로 생각됨
[Paper] EUREKA: HUMAN-LEVEL REWARD DESIGN VIA CODING LARGE LANGUAGE MODELS
Concept
- “펜 돌리기”와 같이 복잡한 저수준 조작 작업을 학습하는 데에 LLM 을 사용하는 것에는 어려움이 있음
- LLM 기반의 Reward 설계 알고리즘인 EUREKA 를 제안하여 이러한 문제를 극복하려 함
- reward code 에 대한 evolutionary optimization 을 통해 복잡한 기술 습득을 유도함
- 미리 정해진 보상 템플릿 없이도 전문가가 설계한 보상 함수보다 더욱 뛰어난 보상 함수 설계에 성공함
- EUREKA = Evolution-driven Universal REward Kit for Agent
- LLM 을 활용한 reward design algorithm
Overview
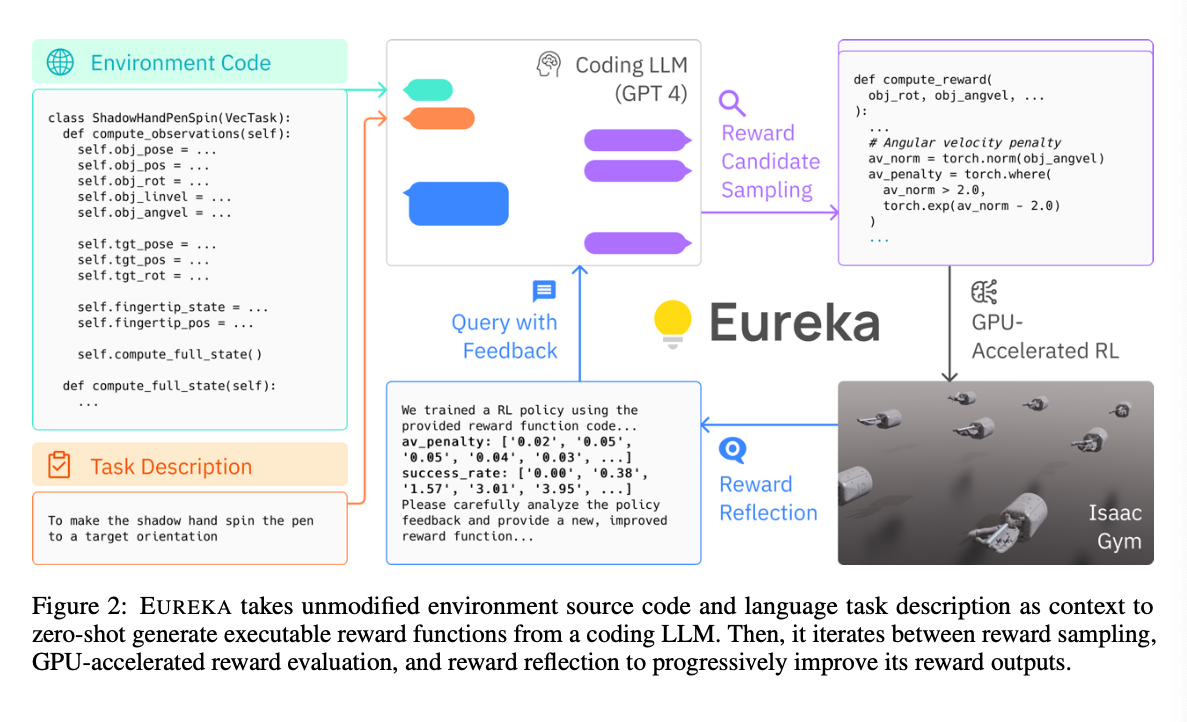
- 세 가지 컴포넌트로 구성됨
- Environment as Context: 실행 가능한 보상 함수의 제로샷 생성을 가능하게 해줌
- Evolutionary Search: 보상 함수 후보를 반복적으로 생성하고 개선함
- Reward Reflection: 세밀한 보상 함수 개선을 가능하게 함

- Environment as Context
- 환경에 대한 이해가 있어야만 LLM 이 적절한 보상 함수를 설계할 수 있음
- 보상 함수를 제외한 환경 관련 코드를 모두 LLM 에게 맥락으로 제공하도록 함
- 실제로는 context window 등을 고려하여 환경 코드 중에서 state 와 action 변수와 관련된 부분만 추출하여 제공함
- 실행 가능한 Python 코드 형태로 반환하도록 지시함
- 제로샷으로도 한 번에 꽤나 괜찮은 보상 함수를 생성할 수 있음 → 개선의 여지는 많음
- Evolutionary Search
- 생성된 보상 함수를 반복적으로 개선하는 과정
- 한 번에 개의 보상함수 후보를 생성함
- 생성된 보상함수는 i.i.d → 생성된 모든 보상 함수에 버그가 있을 확률은 샘플의 갯수가 늘어남에 따라 기하급수적으로 적어짐
- 으로 설정하면 대부분의 환경에 대해 최소한 하나 이상의 실행 가능한 보상 함수를 생성함
- 실행 가능한 보상 함수를 확보하면 “In-Context Reward Mutation”을 통해 개선된 보상 함수를 생성하게 됨
- Reward Reflection
- In-Context Reward Mutation 을 수행하기 위해서는 생성된 보상 함수의 수준을 자연어로 표현할 수 있어야 함
- 이를 위해 policy training dynamics 를 텍스트로 요약하는 자동화된 피드백인 “Reward Reflection” 제안
- 보상 함수가 Total reward 뿐만 아니라 이를 계산할 때에 사용되는 Reward component 의 값들도 출력하도록 함.
- 아래 그림을 보게 되면, 새로운 Reward Component 인 angular_velocity_penalty 가 개선을 통해 추가되었고, 해당 컴포넌트의 값을 reward_components 딕셔너리에 추가하여 반환하고 있음.
- LLM 은 개별 컴포넌트의 값과 Task Fitness Function 을 다음 개선에 활용함
- task fitness function 란, 현재 Policy 가 Task 에 얼마나 적합한지 평가하는 함수
- ground-truth metric 이 될 수 있어야 함. 벤치마크나 전문가에 의해 미리 정의된 함수
- 개별 Reward Components 의 값을 추가한 이유는 로는 부족하기 때문. 전체적인 좋고 나쁨을 아는 것만으로는 개선 포인트를 찾기 어렵다는 것과 개별 부분에 대한 개선 여부를 판단하기 어렵다는 것 두 가지를 이유로 제시.
[Q]를 사람이 매번 만들어줘야 한다면, automated 된 reward function 찾기라고 볼 수 있을까. Ground Truth Reward Function 이 너무 Sparse 해서 더욱 학습이 잘 되는 Reward function 을 찾겠다, 정도의 의의만 가지는 것 아닌가?

[Dev] Agentic Design Pattern
A Hands-On Guide to Building Intelligent Systems - Antonio Gullli
Chapter 1: Prompt Chaining
- 복잡한 문제를 여러 개의 sub task 로 쪼갬으로서 쉽게 이해 가능하고, 디버깅도 쉬워지며, 전체적인 프로세스를 더욱 강건하고 해석 가능하게 할 수 있다.
- 프롬프트 체이닝은 단순히 문제를 쪼개는 것만이 아니다. 외부 데이터 소스와 도구들을 통합할 수 있도록 해준다. 이러한 능력은 LLM 의 가능성을 크게 높혀준다.
- Agent 는 전략적으로 프롬프트 시퀀스를 구조화하여 동적인 환경에서 자율적으로 여러 스텝에 걸쳐 추론하고, 계획하며, 의사 결정을 내릴 수 있다.
- 각 프롬프트의 출력은 JSON 또는 XML 과 같이 정형화된 포맷을 따르는 것이 좋다. 모호하거나 적절치 않은 포맷으로 출력될 경우 이후의 모든 프롬프트 출력 결과에 영향을 미칠 수 있기 때문이다.
# Initialize the Language Model (using ChatOpenAI is recommended)
llm = ChatOpenAI(temperature=0)
# --- Prompt 1: Extract Information ---
prompt_extract = ChatPromptTemplate.from_template(
"Extract the technical specifications from the following text:\n\n{text_input}"
)
# --- Prompt 2: Transform to JSON ---
prompt_transform = ChatPromptTemplate.from_template(
"Transform the following specifications into a JSON object with 'cpu', 'memory', and 'storage' as keys:\n\n{specifications}"
)
# --- Build the Chain using LCEL ---
# The StrOutputParser() converts the LLM's message output to a simple string.
extraction_chain = prompt_extract | llm | StrOutputParser()
# The full chain passes the output of the extraction chain into the 'specifications'
# variable for the transformation prompt.
full_chain = (
{"specifications": extraction_chain}
| prompt_transform
| llm
| StrOutputParser()
)
# --- Run the Chain ---
input_text = "The new laptop model features a 3.5 GHz octa-core processor, 16GB of RAM, and a 1TB NVMe SSD."
# Execute the chain with the input text dictionary.
final_result = full_chain.invoke({"text_input": input_text})
print("\n--- Final JSON Output ---")
print(final_result)
- extraction_chain 은 “specification” 정보를 추출하는 역할 수행
- full_chain 에서는 extraction_chain 의 출력을 받아, 이를 JSON 형태로 변환하는 작업을 수행
- langchain 에서
|파이프 연산자는 UNIX 의 파이프 연산자처럼 이전 출력을 다음 입력으로 전달하도록 하여 파이프라인을 구성하는 데 사용됨- 이전 파이프의 출력과 이후 파이프의 입력 간의 타입이 호환되어야 함
StrOutputParser(): LLM 의 출력을 string 으로 변환해줌
Context Engineering and Prompt Engineering
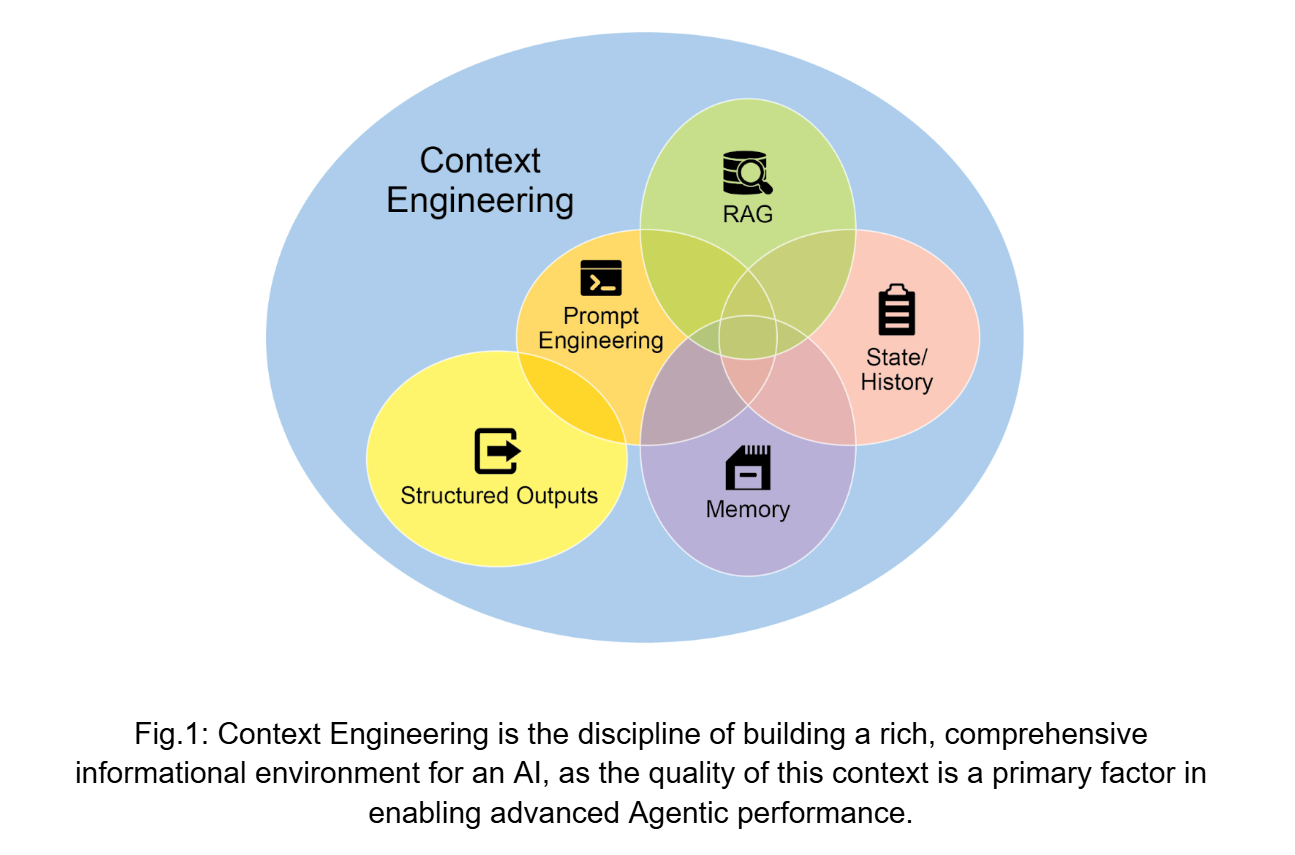
- Context Engineering 이란 LLM 이 token 을 생성하기에 앞서 완전한 정보를 제공하는 환경을 디자인하고 구축하며 제공해주는 시스템적인 원칙이다.
- Context Engineering 에서는 단순히 질문에 답하는 것에서 에이전트를 위한 포괄적인 운영 상황을 구축하는 것으로 작업을 재정의한다.
- AI의 기본적인 지침 세트라 할 수 있는 시스템 프롬프트
- 외부 데이터 베이스
- 외부 API 와 같은 툴
- 핵심 원칙은 고급 모델조차도 제한적이거나 잘못 구성된 운영 환경 정보를 제공받으면 성능이 저하된다는 것이다.