- Published on
This Week I learned 5
Summary
1. [Dev] MongoDB
- MongoDB 에서는 Collection 의 여러 개의 Document 를
Page 단위로 그룹화하여 저장함 - MongoDB 에서도 인덱스 기능이 있으며,
B+tree를 사용하여 서치함 - 적절한 인덱싱 기능, 캐싱 기능을 활용하는 것이 성능의 핵심, RDBMS 보다 빠르게 동작할 수 있다!
- Motor 는 MongoDB 의 Python async driver 이고, beanie 는 motor 기반의 비동기 MongoDB ODM 이다. 이를 활용하여 Schema 를 도입할 수 있다.
2. [Paper] ViT: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- Image specific 한 inductive bias 를 가진 구조(e.g. CNN)를 사용하지 않고, Transformer Encoder 만으로도 충분히 좋은 Image 모델을 만들 수 있다.
- 이미지를 patch 로 쪼개어 Sequential 하게 정렬한 다음, Learnable Position Encoding 과 함께 Transformer 에 입력으로 전달하여 image classification 문제에서 높은 성능을 기록하였다.
- pixel 단위가 아닌 patch 로 쪼개어 하는 것은 계산 효율성 때문이다. patch의 크기가 작아질수록 성능은 더 좋아지는 면이 있다.
- Attention distance 를 통해 global 한 정보에 집중하는지 local 한 정보에 집중하는지 확인할 수 있다.
3. [Paper] VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
- VLA 에 강화학습을 적용하여 학습을 하는 방법 제안
- 강화학습의 강점 중 하나는 탐색과 외부와의 상호작용을 통해 끊임없이 새로운 데이터를 접할 수 있다는 점 -> Static Dataset 을 학습한 VLM 의 단점 극복
- RPRM(Robotic Process Reward Model) 을 도입하여 Sparse Reward 문제를 해소함
4. [Paper] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
- RL in Embodied Agents 파트만 정리
5. [Paper] CoA-VLA: Improving Vision-Language-Action Models via Visual-Textual Chain-of-Affordance
- object, grasp, spatial, and movement 등 네 가지 종류의 affordance 를 활용하여 Chain of Affordance 를 구성함
- 각 Affordance 는 Textual, Visual 의 두 종류를 가짐
- 이들 Affordance 로 Chain of Affordances(CoA)를 구성하고, Action 을 결정하는 데에 사용함
[Dev] MongoDB
Database 와 Collection
- Database: 컬렉션 들의 물리적인 컨테이너로, 각 데이터베이스는 파일 시스템에서 별도의 파일 세트로 저장, 관리됨
- Collection: documents 의 그룹으로, RDBMS의 테이블과 유사하나, 스키마를 강제하지 않는다는 차이가 있음
| RDBMS | MongoDB |
|---|---|
| Database | Database |
| Table | Collection |
| Row/Record | Document |
| Column | Field |
데이터 저장 방식
- WiredTiger 스토리지 엔진을 기본 스토리지 엔진으로 사용
- 스토리지 엔진이란, 메모리와 디스크에서 데이터를 저장하고 접근하는 방식을 관리하는 도구
- 트랜잭션 지원, 락 프리(Lock Free) 알고리즘, 데이터 압축 등을 지원하는 key-value store
- WiredTiger Github
- KakaoTalk Tech blog
- 데이터 파일 구조
- 각 컬렉션과 인덱스는 별도의 파일로 저장됨
- Document 는 ‘페이지’ 단위로 그룹화되어 저장됨(기본 32K)
- 메모리 관리
- 페이지 단위로 메모리에 올려서 LRU(Least Recently Used) 알고리즘으로 캐시 관리
- 운영체제가 ‘파일’단위가 아닌 ‘페이지’단위로 메모리에 로드할 수 있는 기능을 제공함
- 변경된 페이지들은 체크 포인트를 통해 주기적으로 디스크에 저장
- 페이지 단위로 메모리에 올려서 LRU(Least Recently Used) 알고리즘으로 캐시 관리
인덱스/인덱싱
- 인덱스: 데이터베이스에서 빠른 검색을 위해 사용하는 별도의 데이터 구조
- MongoDB 에서는 Single Field Index, Compound Index, Multikey Index, Text Index, Geospatial Index 등을 지원함
// single field
db.users.createIndex({ email: 1 }) // 오름차순
db.users.createIndex({ createdAt: -1 }) // 내림차순
// compound
db.orders.createIndex({
customerId: 1, // 첫 번째 정렬 기준
orderDate: -1, // 두 번째 정렬 기준
status: 1 // 세 번째 정렬 기준
})
// text
db.articles.createIndex({
title: "text",
content: "text"
})
// GeoSpatial
db.places.createIndex({ location: "2dsphere" })
- MongoDB 는
B+Tree를 사용함- 모든 leaf node 가 동일한 레벨에 위치하는 tree
- 각 node 는 여러 개의 key 를 가질 수 있음
- 검색, 삽입, 삭제 모두
O(log n) - 순차 접근에도 효율적
- 인덱스 파일
- 인덱스 또한 파일로 저장 관리됨. 인덱스 별로 별도의 파일이 생성됨
- 인덱스 파일은 여러 개의 페이지로 구성되며, 각 페이지는 B-Tree 의 개별 노드에 대응함
- 각 페이지는 Header 와 Body 로 구성됨
- Header: Page Type(Root, Internal, Leaf), Key Count, Parent Page ID
- Body: Key Value Pair
기능 구현
- 장점
- 적절한 인덱스 설정 시 매우 빠른 조회 성능을 보임
- 수평 확장이 가능함
- 적절한 캐싱 전략을 사용하는 것이 중요함
- 로그인 기능 등을 구현함에 있어 RDBMS 와 유사한 성능 혹은 더 나은 성능을 보임. 대규모 사용자 환경에서 샤딩을 통한 확장성 면에서 장점이 있음
mongosh
- MongoDB 의 공식 JS 기반 Shell
motor
- Motor
- mongodb 비동기 Python 드라이버
- 비동기 I/O 지원 -> 데이터베이스 작업으로 인해 블로킹이 발생하지 않음
- 높은 동시성 -> 수천 개의 동시 연결 처리 가능
# Motor (비동기 방식)
import motor.motor_asyncio
import asyncio
client = motor.motor_asyncio.AsyncIOMotorClient("mongodb://localhost:27017")
db = client.mydb
async def find_user():
result = await db.users.find_one({"email": "john@example.com"}) # 논블로킹
return result
# 사용
user = asyncio.run(find_user())
- 코루틴 내에서 접근할 필요가 없다면 PyMongo 를 사용하는 것이 더 좋을 수 있음
beanie
- beanie
- motor 기반의 비동기 MongoDB ODM(Object Document Mapper)
- Pydantic 과 통합되어 타입 안정성과 데이터 검증 제공(파이썬의 타입 힌트 완벽 지원)
- 다음과 같이 ORM-like 하게 사용할 수 있도록 해줌
from beanie import Document, Indexed
from pydantic import BaseModel, Field
from typing import Optional, List
from datetime import datetime
from pymongo import IndexModel
class User(Document):
# 필드 정의
name: str
email: Indexed(str, unique=True) # 유니크 인덱스
age: int = Field(ge=0, le=120) # 나이 범위 검증
is_active: bool = True
tags: List[str] = []
created_at: datetime = Field(default_factory=datetime.now)
# 내장된 서브 문서
class Profile(BaseModel):
bio: Optional[str] = None
avatar_url: Optional[str] = None
location: Optional[str] = None
profile: Optional[Profile] = None
class Settings:
# 컬렉션 이름 지정
name = "users"
# 추가 인덱스 정의
indexes = [
IndexModel([("name", 1), ("age", -1)]), # 복합 인덱스
IndexModel([("tags", 1)]), # 배열 인덱스
IndexModel([("created_at", 1)], expireAfterSeconds=86400) # TTL
]
- 사용하기 위해서는 다음과 같은 작업을 해주어야 함
import asyncio
from motor.motor_asyncio import AsyncIOMotorClient
from beanie import init_beanie
async def init_database():
# MongoDB 클라이언트 생성
client = AsyncIOMotorClient("mongodb://localhost:27017")
# Beanie 초기화
await init_beanie(
database=client.mystore,
document_models=[User, Post, Category] # 모든 문서 모델 등록
)
print("Beanie 초기화 완료")
# 초기화 실행
asyncio.run(init_database())
[Paper] ViT: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Summary
- Image specific 한 inductive bias 를 가진 구조(e.g. CNN)를 사용하지 않고, Transformer Encoder 만으로도 충분히 좋은 Image 모델을 만들 수 있다.
- 이미지를 patch 로 쪼개어 Sequential 하게 정렬한 다음, Learnable Position Encoding 과 함께 Transformer 에 입력으로 전달하여 image classification 문제에서 높은 성능을 기록하였다.
- pixel 단위가 아닌 patch 로 쪼개어 하는 것은 계산 효율성 때문이다. patch의 크기가 작아질수록 성능은 더 좋아지는 면이 있다.
- Attention distance 를 통해 global 한 정보에 집중하는지 local 한 정보에 집중하는지 확인할 수 있다.
Contribution
- CNN 을 사용하지 않고 Image 를 patch 로 쪼개어 Transfomer 에 직접 sequence 로 넣어주어도 image classification task 에서 좋은 성능을 보일 수 있다.
- Image patch 를 word token 과 동일하게 취급함
- pixel 단위로 self-attention 을 적용하는 것은 현실적으로 불가능하기 때문에 이를 해소하기 위한 방법으로 patch 를 도입함 → 계산량 때문에 patch 도입
- CNN 에 비해 Transformer 는 상대적으로 Inductive bias 가 떨어지기 때문에 적은 수의 데이터셋으로는 좋은 성능을 보이지 못했으나, 많은 데이터로 학습하면 월등히 좋은 성능을 보인다.
Architecture
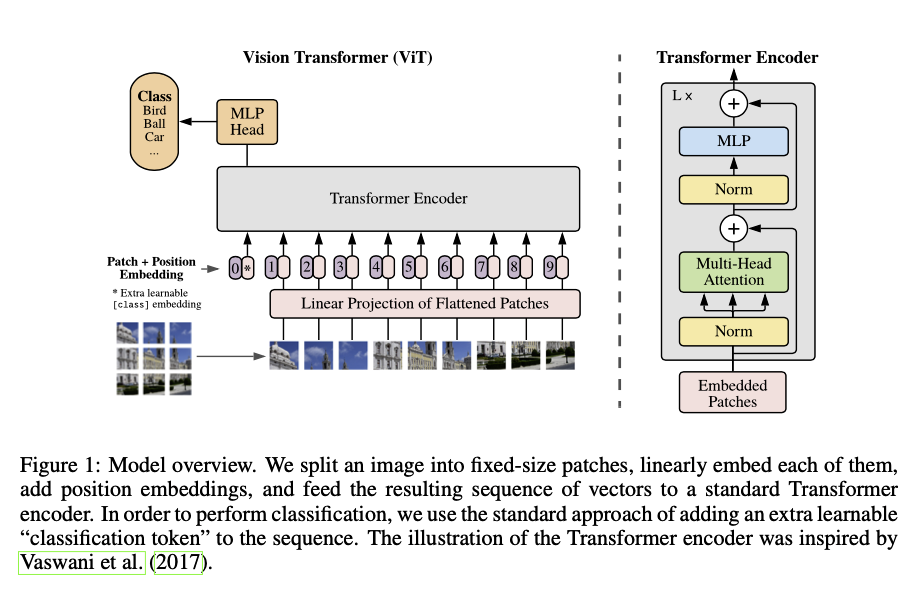
- 원본 이미지 를 와 같이 평면화된 배치 시퀀스로 만듦.
- 여기서 는 패치의 크기, 은 패치의 갯수라고 할 수 있음.
- 각 패치는 flatten 한 뒤 linear projection 을 통해 Transformer encoder 의 입력으로 전달할 수 있는 차원 로 만듦. 그리고 Position embedding 도 더해줌
(1).- 2D-aware position embedding 도 사용해봤으나, 1D 와 성능상 큰 차이가 없어, 1D position embedding 을 사용함
- 1D Positional Embedding: 이미지 패치를 일렬로 나열하고, 순서를 부여하는 방식
- 2D Positional Embedding: 이미지의 row, column 상 위치 정보를 각각 인코딩하는 방식 → 위치 정보가 명시적으로 들어감
- 2D-aware position embedding 도 사용해봤으나, 1D 와 성능상 큰 차이가 없어, 1D position embedding 을 사용함
- 첫 번째 토큰으로는 BERT 에서 사용되는
[class]토큰과 유사한 토큰을 도입함(1).- 이 토큰 위치의 출력 값이라 할 수 있는 Transformer Encoder 의 첫 번째 출력
(2, 3)에 LayerNorm 을 씌워, 이미지 전체에 대한 종합적인 정보를 담고 있는 를 계산함(4)
- 이 토큰 위치의 출력 값이라 할 수 있는 Transformer Encoder 의 첫 번째 출력
- 이 를 MLP layer 에 넣어 최종적으로 클래스 확률을 예측하도록 만듦
Experiments
- ViT-L/16 그리고 그보다 더 큰 ViT-H/14 두 모델로 성능을 비교함
- 두 모델 모두 ImageNet, ImageNet-ReaL, CIFAR-100 등에서 실험해 볼 때, 비슷한 크기의 모델보다 좋은 성능ㄹ 보여줌
- 유사한 크기의 ResNet 모델과 비슷한 추론 속도를 보여줌
- ResNet 모델에 비해 높은 메모리 효율성을 보여줌
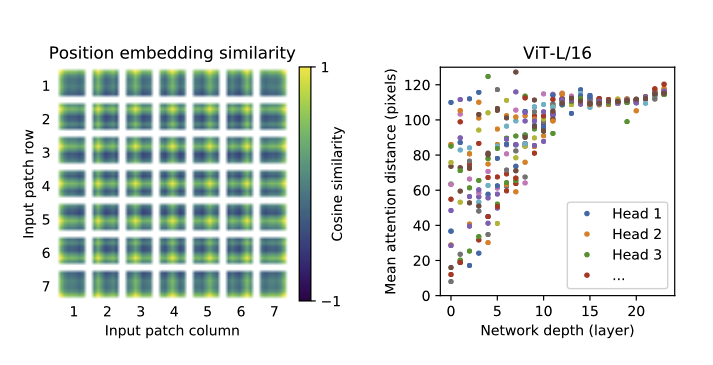
- Inspecting ViT
- positional encoding 은 학습 가능함. 학습된 positional encoding 간의 유사도를 구해보면, 패치의 위치가 가까울수록 코사인 유사도가 높은 쪽으로 학습됨을 알 수 있음. 이러한 점 때문에 1D positional encoding 을 하여도 2D와 비교하여 성능이 나쁘지 않을 것
- self-attention 을 통해 ViT 는 첫 번째 계층의 아웃풋에서부터 이미지 전체의 정보를 통합할 수 있음
- attention distance 란 attention weight 를 기반으로, 이미지 공간에서 정보가 통합되는 거리르르 의미함 - CNN 의 Receptive Field 와 유사한 개념
- Mean Attention Distance 는 특정 pixel(query pixel)과 다른 모든 pixel 간의 거리에 attention score 로 가중 평균하여 구하게 됨
- Attention Distance 가 크다는 것은 멀리 있는 픽셀의 정보를 많이 활용하고 통합한다는 것을 의미함
- 낮은 계층의 레이어에서는 Head 마다 서로 다른 경향성을 보임. 어떤 Head 는 global 하게 보려고 하고, 다른 어떤 Head 는 local 정보를 주로 보려고 함
- 네트워크의 깊이가 깊어질수록 모든 헤드에서 Attention distance 가 멀어지는 경향을 보임, 즉 이미지 전체의 의미를 통합하는 경향을 보이는 것으로 해석할 수 있음
[Paper] VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
- 강화학습의 강점 중 하나는 탐색과 외부와의 상호작용을 통해 끊임없이 새로운 데이터를 접할 수 있다는 점임. 이러한 점에서 정적인 데이터로만 학습된 모델의 약점을 해결하겠다는 것임
- VRA-RL 은 Trajectory-level 의 최적화를 Multi-modal, Multi-turn conversation 으로 formulation 하여 VLA 에서도 언어 모델에서 입증된 RL 의 장점을 적용하는 것을 목표
Introduction
- 인간의 행동을 모방하는 VLA 모델이 다수 제안되었음
- 하지만, 오프라인 데이터를 활용하는 것은 테스트 시 Out-of-Domain(OOD) 문제를 유발할 수 있음
- Welcome to the Era of Experience 에서 예시 드는 것과 같이 exploitation-based 방법론에서 exploration-based 방법론이 이러한 문제를 극복하는 데에 도움이 될 수 있음
- 오프라인 데이터 뿐만 아니라 온라인 데이터 또한 학습에 사용하는 방법이 유망한 패러다임으로 제시되고 있음
- 정리하자면, VLM 을 학습할 때에 사용한 데이터는 다량의 데이터이긴 하나, ‘정적’인 데이터 임. 이에 그치지 않고 RL 을 통해 상호작용하며 다양하게 수집한 데이터(Online Collected Data)를 경험삼아 학습에 사용하면 더욱 좋을 것이라는 것
- “로보틱스 분야에서도 RL 을 활용하여 유사한 이점(test-time scaling benefit)을 얻을 수 있을 것인가?”
Contribution
- pretrained VLA 모델을 online RL 으로 개선하는 프레임워크, VLA-RL 제안
- robitic trajectory 를 multi-modal multi-turn conversation 의 형태로 모델링하는 방법 제안
- sparse reward 문제를 해결하기 위해 robotic process reward model 을 구현함
Related work
- Robotic Foundation Models
- OpenVLA-7B: 다양한 테스크에 걸쳐 높은 일반화 성능을 보이나, 전문가의 행동을 imitation learning 하였다는 점에서 OOD 문제에서 자유롭지 못함
- Reinforcement Learning for Robotics Models.
- RL 모델을 처음부터 구현하는 것은 정교한 보상과 트레이닝 방법론을 요구했음. 이러한 점 때문에 pretrained 모델의 사용을 적극 고려해왔음. 이 또한 오프라인 데이터셋을 필요로 함
- VLA-RL은 풍부한 표현 지식이 탐색 공간을 크게 줄이고 모델이 복잡한 움직임 패턴을 학습할 수 있게 함. 또한 일반적인 태스크 및 환경에서의 훈련을 가능하게 하는 trajectory-level RL을 사용하여 대규모 로봇 파운데이션 모델에서 파인튜닝 방법을 탐구함
- Reinforcement Learning for Large Models
- 강화학습은 LLM 의 Reasoning 능력을 크게 높여왔음
- GRPO가 대표적. 강화학습을 통해 순차적 의사 결정과 특히 관련된 체계적인 문제 해결 능력을 강화함. 이러한 방법론에는 Process Reward Model 과 Conversation-based training method 를 포함함.
- 최근에 제안된 RL 기술들은 다양한 구현 상의 세부 사항이 언어 모델의 추론 스케일링을 향상시킨다고 함
- VRA-RL 은 Trajectory-level 의 최적화를 Multi-modal, Multi-turn conversation 으로 공식화하여 로보틱스 분야에서도 언어 모델에서 입증된 RL 프레임워크의 이점을 얻을 수 있도록 하는 것이 목표
Overall-Pipeline
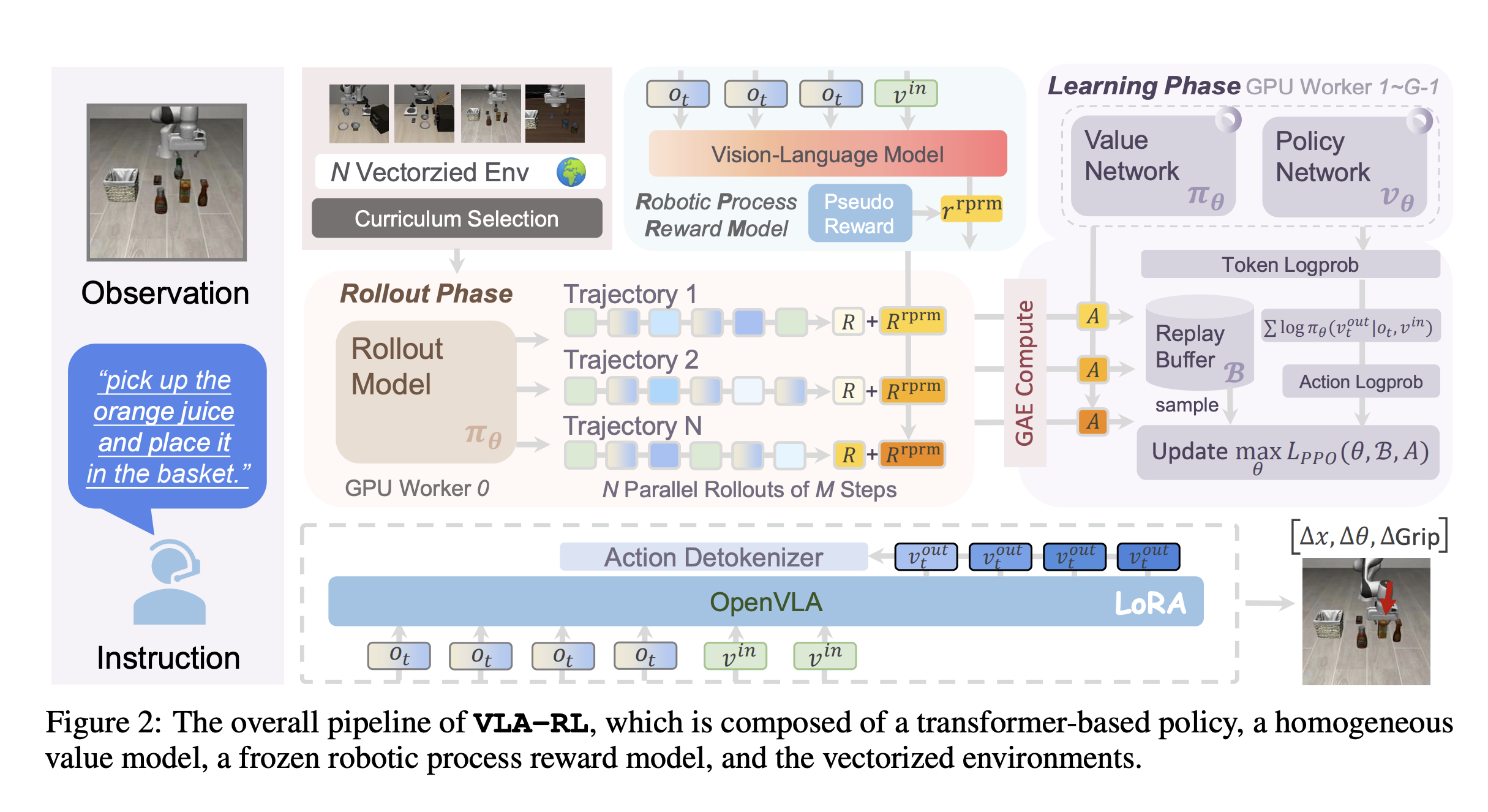
- Actor-Critic(PPO) + frozen robotic process reward model 의 세 가지 모델로 구성됨
- 알고리즘 수준에서, auto-regressive VLA-RL 트레이닝을 multi-modal multi-turn conversation 형태로 formulation 함
- 트레이닝 안정성을 위해 “GPU-balanced vectorized environment, batch decoding, curriculum selection strategy, and critic warmup” 등을 도입함
Notations
- : 가능한 입력 텍스트 시퀀스 공간
- : 가능한 출력 텍스트 시퀀스 공간
- : 입력 이미지 공간
- : state space
- : Policy
- : RPRM의 파라미터
- : RPRM이 예측한 다음 토큰 의 확률
General Robotic Manipulation as Multi-turn Conversation
- PPO 알고리즘을 적용하여 discounted sum of reward 를 극대화하는 방향으로 policy 업데이트
- 두 페이즈로 구성
- Rollout Phase
LoRA 가중치를 체크포인트에 반영 + Inference Engine 에도 반영하여 Agent도 이에 따르도록 함
Transaction 을 수집함
OpenVLA의 Action space 의 크기가 이므로, 한 번에 7개의 token 을 생성해야 함. 를 취하여 summation 으로 표현할 수 있음
- Learning Phase
PPO Clipping 알고리즘으로 적용하여 업데이트 + Genearalized Advantage Estimation(GAE) 적용함
Robotic Process Reward Model(RPRM)
- Reward Modeling 은 (1) sparse 한 피드백이 주어지는 환경에서 dense 한 리워드를 주기 위해, 또는 (2) reward hacking, 즉 의도치 않은 방향으로 학습이 이뤄지는 경우를 방지하기 위해 사용됨
- 로보틱스 또한 sparse reward 문제를 자주 겪음(task를 완료해야만 긍정적인 피드백)
- VLA 를 강화학습으로 업데이트하기 위해서는 reward modeling 을 next-token prediction 문제로 재구성해야 할 필요가 있음
- RPRM은 Trajectory 가 주어졌을 때, 성공적인 action sequence 의 likelihood 를 예측하는 데에 사용함
- RPRM 의 업데이트 objective function 은 다음과 같음
Autonomous Pseudo Reward Label Generation
- 사람의 레이블링 없이 RPRM 을 트레이닝하기 위해 자율적인 생성 파이프라인을 도입함
- Milestone Segmentation
- 전문가와 과거 모델의 실행으로부터 다양한 성공적인 trajectory 들을 수집함
- gripper 의 열림에 따라 subtask 로 분할함 - gripper 의 열림은 기능적 단계의 완료를 나타내는 경우가 많음
- Progress Labeling
- subtask 중에서 end effector(로봇팔의 끝부분)의 움직임이 0에 가까워지는 순간의 키프레임을 파악함
- 이 순간은 전체 문제를 해결하는 데 있어 부분적인 달성이 있는 지점으로 볼 수 있음
- 이러한 키 프레임으로 이어지는 Action Sequence 에 Positive Pseudo-reward 를 할당함
- 부분적인 달성이 이뤄지는 데에 사용된 Action 들에 긍정적인 보상을 주는 것임
- 이렇게 수집한 데이터로 RPRM 을 학습시키게 됨
- subtask 중에서 end effector(로봇팔의 끝부분)의 움직임이 0에 가까워지는 순간의 키프레임을 파악함
- Final Reward
- 환경으로부터 얻는 Sparse Reward + RPRM의 Predicted Reward
some tricks
- Curriculum Selection Strategy
- adaptive curriculum, 즉 현재 agent 의 능력에 기반하여 적절한 task 를 선택함
- 는 task 에 대한 성공률을 뜻함. 즉 성공 확률이 50% 이상인 작업을 우선 학습할 수 있도록 하겠다는 것 → 샘플 효율을 높이는 방법
- adaptive curriculum, 즉 현재 agent 의 능력에 기반하여 적절한 task 를 선택함
- Critic Warmup
- 학습 초기 Critic network 의 부정확성 문제를 줄이기 위해 Policy 를 업데이트하기 전에 Critic 만 먼저 업데이트함
- GPU-balanced Vectorized Environment
- 각 GPU worker 에 상호작용할 환경 셋을 제공함. 이는 벡터화 환경 수 증가에 따른 GPU 메모리 소비 문제를 해결하기 위함.
- Infrastructure
- OpenRLHF, open-instruct 등에서 했던 것처럼 vLLM 가속을 사용하여 추론용으로 1개의 GPU 를, 나머지 GPU 는 모두 Ray + PyTorch FSDP 를 활용하여 학습에 사용함.
- 추론용 서버에서는 롤아웃을 진행하여 transaction 을 수집하고, 학습용에서는 이렇게 수집된 transaction 들을 활용하여 모델을 업데이트하는 것
- PyTorch FSDP 는 모델의 파라미터를 여러 개의 GPU 에 샤딩하고, 이를 학습 및 관리해줌.
- 여러 개의 학습용 GPU 에서는 자신들이 가지고 있는 부분적인 모델 파라미터의 LoRA 가중치를 업데이트 함
- Phase 가 종료되면 이를 Inference System 에 병합함.
Experiment
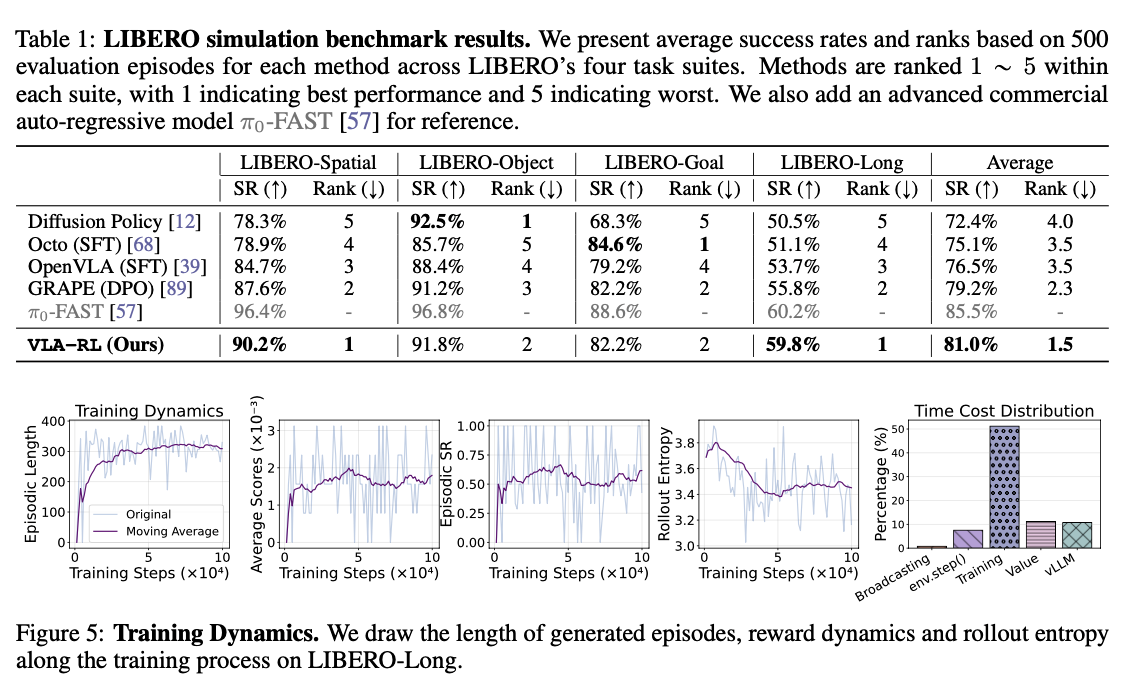
- Major Experiments
- LIBERO benchmark 의 네 가지 task suites 를 환경으로 사용
- Diffusion Policy, Octo(SFT), OpenVLA(SFT), GRAPE(DPO), 그리고 상용 모델인 -FAST 를 비교 모델로 사용
- Training Dynamics
- 트레이닝이 진행됨에 따라 Episode 의 길이가 점차 감소함 → 효율적인 액션 선택
- 트레이닝이 진행됨에 따라 Reward 또한 일관된 증가를 보여줌 → RPRM 이 효율적으로 동작하는 것으로 짐작할 수 있는 부분
- Rollout Entropy: Action 선택에 있어 적절한 수준의 Entropy 를 유지함
- Timing Analysis: 많은 시간을 Training 에서 사용하고 있음. GPU 를 균형 있게 사용하고, vLLM 을 도입한 결과로 효율적인 시간 사용을 달성함
- Ablation study
- LIBERO-Spatial 에서 다양한 제거 실험을 진행함
- RPRM 제거 시 -4.4%
- reward modeling 을 통해 dense 한 보상을 제공하는 것이 도움이 됨
- Curriculum Selection Strategy 제거 시 -2.2%
- 현재 어려운 테스크에 집중하여 Catastrophic forgetting 을 줄이고, 일반화 성능을 높임.
- Temperature 축소 시 -4.4%
- 적절한 탐색은 필수적
- Critic Warmup 제거 시 -10.2%
- 초기 노이즈가 학습에 부정적인 영향을 미침을 확인
- Learning rate 변경 시 -90%
- 학습률을 조금만 높여도 학습 자체가 되지 않을 수 있음.
감상
- 재미있는 프레임워크. VLA 를 강화학습으로 업데이트 하는 방법론을 제시함.
- RPRM 과 같이 Sparse reward 문제를 해결할 수 있는 방법도 흥미로움. 하지만 “그리퍼의 열림 정도”에 따라 subtask 를 분할하는 점 등은 확장 가능성이 있어 보이지는 않음. 더 일반적이고, 명확한 방법이 있지 않을까 정도.
- OpenVLA 를 학습할 때와 유사한 테스크기에 가능한 것 아닌가? degree of freedom 이 7이 아닌 로봇팔의 경우 어떻게 할 것인가 / 로봇팔이 아니면 어떻게 할 것인가? - 논문에서 보이고자 하는 것은 ‘강화학습을 적용하여 VLA 업데이트하기’ 이므로 논문의 스코프는 아니긴 함
- Adaptive Curriculum learning 도 흥미로웠음
- GRPO, RoLA 논문 읽어보기
- LIBERO Benchmark 찾아보기
[Paper] The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
- 필요한 부분만 정리
4.6. RL in Embodied Agents
- 일반적으로 Instruction-driven embodied scenario 에서 RL 을 적용할 때에는 post-training 을 사용함
- pretrained VLA 를 teacher-forcing supervision 으로 imitation learning 을 실시함
- 이후 Interactive Agent 에 적용하여 환경과 상호작용하며 reward 를 수집하도록 함
- embodied agent 는 크게 navigation agent 와 manipulation agent 두 가지로 나누어 볼 수 있음
- navigation agent
- Navigation 문제에서는 planning 능력이 중요함
- RL 은 VLA 가 future action sequence 를 예측하고, 최적화하는 것을 도울 수 있음
- VLN-R1 : 예측 가능한 플래닝을 위해 GRPO 로 트레이닝
- OctoNav-R1: GRPO + promoting a thinking-before-acting paradigm
- S2E: navigation foundation model 을 통합하는 RL 프레임워크 제안
- manipulation agent
- 로봇팔과 같이 정교하게 정해진 테스크를 수행하는 것을 목적으로 함
- 여기서 RL 은 주로 VLA 가 주어진 지시를 잘 따르고(instruction-following), trajectory 를 잘 예측하도록 만들기 위해 적용됨
- real-world 환경에서 강화학습을 위한 대규모 훈련을 하는 것은 어려움이 많음. 시뮬레이션만 사용하는 것은 sim-to-real gap 이 존재함. 이러한 gap 을 메우는 것이 중요한 토픽 중 하나임.
- RLVLA, VLA-RL: pre-trained VLA 를 평가자로 사용, 이들의 feedback 을 VLA policy 업데이트에 사용
- TGRPO: rule-based reward functions + GRPO 로 일반화 성능을 높임
- VIKI-R: multi-agent embodied cooperation 을 위한 2 stage framework 제안, CoT 파인튜닝 + multi-level RL
[Paper] CoA-VLA: Improving Vision-Language-Action Models via Visual-Textual Chain-of-Affordance
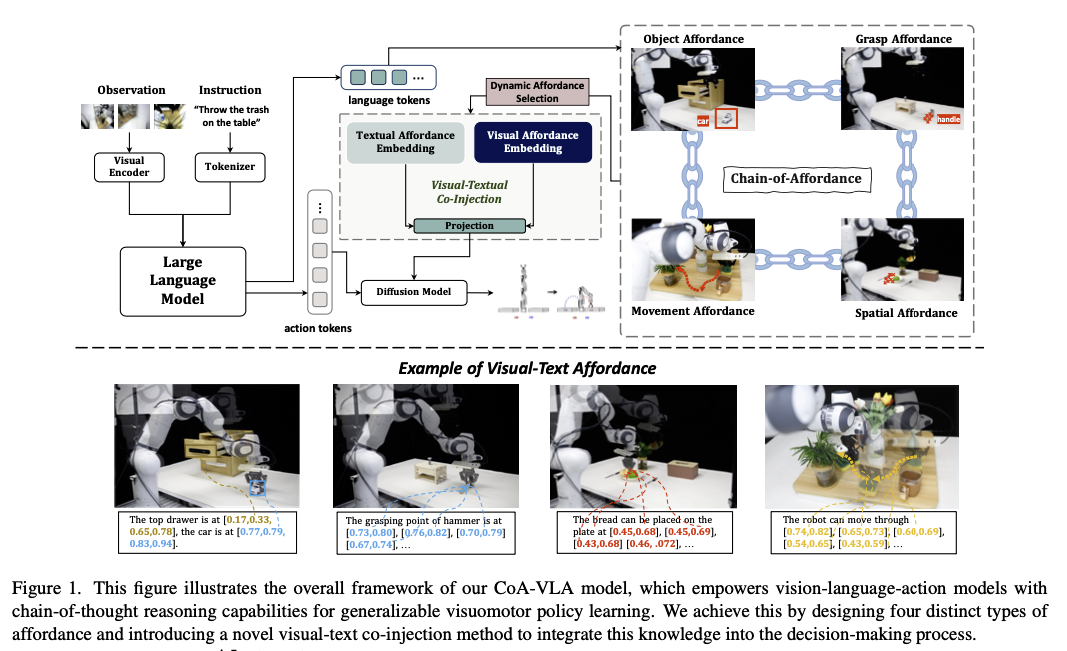
Objective
- 과거의 관찰들과 action 에 도움이 되는 추론을 통해 로봇이 복잡한 환경 속에서 다양한 테스크를 수행하는 것을 도울 수 있는지 확인하는 것이 논문의 목표
- 이를 위해 테스크 수행에 도움이 되는 연속적인 robot affordance 를 추론할 수 있는 CoA(Chain of Affordance) 를 도입함
- object, grasp, spatial, movement 네 종류의 Affordance 를 필요에 따라 동적으로 선택하여 visual affordance, textual affordance 두 가지로 구성된 프롬프트를 생성하고, 이를 vision-language co-injection module 에 입력으로 전달하여 Action 을 결정하도록 함
Method
- expert demonstration 과 그것에 대한 task description 이 쌍으로 존재한다고 가정하면,
- demonstration 은 일련의 observation 으로,
- task description 은 복수의 sub-task 로 나타낼 수 있을 것
- 를 어떤 task 에 대한 자연어로 된 affordance-based reasoning 이라고 한다면, 이는 네 가지 component 로 나누어 볼 수 있음: object, grasp, spatial, and movement affordances
- 우리의 목표는 Observation 과 Task 를 자연어로 된 로 만드는 것에 있음
- 가 low-level action 를 생성하는 데에 도움이 될 것임:
Affordances
- Object affordance
- 테스크를 수행하기 위해서는 어떤 object 와 상호 작용을 해야하고, 그 object 는 어디에 있는지 등을 알 수 있는 정보
- query/instruction 이 모호한 경우에 이를 명확하게 해주는 것으로, 논문의 프레임워크에서는 다음 두 가지를 주로 다룸
- Semantic identification: free-form text input 으로부터 대생 객체를 명확히하는 것
- Spatial grounding: 시각 이해를 통해 해당 객체의 위치를 예측하는 것
- Grasp affordance
- 객체를 조작할 수 있는 가능한 기능이나 방법에 대한 정보
- 시각과 행동을 연결하는 역할
- Spatial affordance
- 3D 환경에 대한 이해와 추론을 진행하는 어포던스
- collision free region 을 찾아내는 데에 도움이 됨
- 실현 가능한 상호작용 영역을 나타내는 2D 좌표로 작동함
- Movement Affordance
- 작업 중 따를 수 있는 Trajectory 를 정의하는 어포던스
- 환경 변화에 동적으로 대응하여 작업을 완료하는 데에 도움을 줌
- 모든 affordance 가 항상 동일하게 필요하지는 않음.
- 현재 상황 또는 진척에 따라 중요한 affordance 가 변할 수 있음, 또한 매번 모든 affordance 를 사용하는 것은 연산적으로도 비효율적임
- 이를 위해 상황에 따라 동적으로 affordance 를 선택하여 프롬프트를 구성하도록 함
- 현재 로봇의 상태에 대한 정보를 전달하고 필요한 어포던스를 고르도록 llm 을 학습하여 이를 활용함
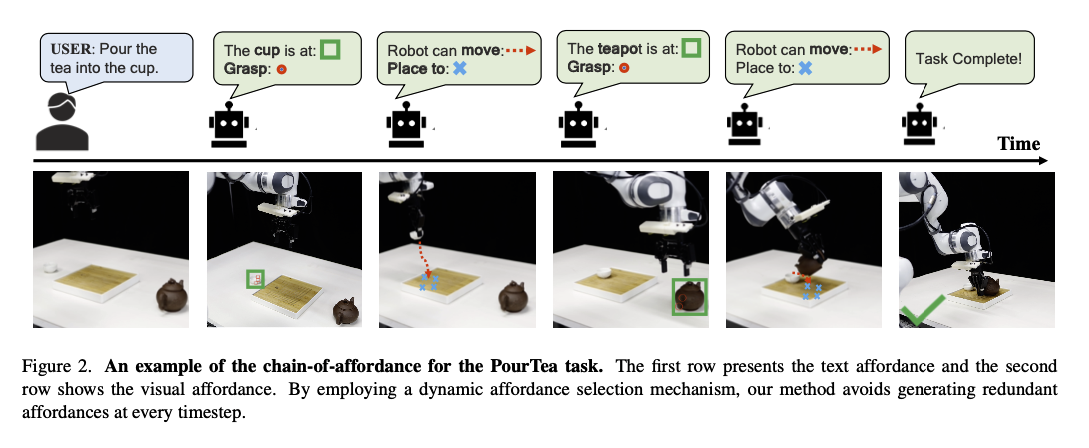
- 각 affordance 는 text, vision 두 타입을 가짐. 위의 그림을 보면 두 타입의 관계를 보다 명확히 확인 가능
- Textual affordance는 semantic reasoning 을 담당함
- Visual affordance 는 시각적으로 모호한 부분에 대한 설명 담당함
- Text Affordance 의 경우, 고정된 언어 템플릿으로 인한 편향을 막기 위해 ChatGPT 를 활용하여 다양한 구조와 어휘를 가진 텍스트로 변환
- Text, Vision Affordance 의 통합
- 두 타입의 Affordance 를 diffusion policy 의 입력으로 적절히 넣어줄 수 있는 프레임워크 제안
- Text Affordance: VLM 의 마지막 임베딩에 MLP 를 붙여서 토큰화
- Vision Affordance: ViT-small 을 활용하여 토큰화
- 두 토큰들을 Transformer 에 입력으로 전달, 이때 MT-ACT 에서 영감을 받은 FiLM 레이어 사용
Chain of Affordance Data 생성
- 일반화 성능을 높이기 위해서는 다양한 affordance 들을 수집해야 함.
- 사람이 하기에는 비싸니 자동화를 함
- flow 는 다음과 같음
- GPT-4o 를 활용하여 이미지에 대한 설명과 관련 객체 정보 추출
- Grounding DINOv2, SAM 을 활용하여 식별된 객체의 위치를 알려주는 바운딩 박스 추출
- 두 알고리즘의 IoU 를 취하여 다듬게 됨
- RoboPoint 를 활용하여 그리퍼의 행동 가능한 범위에 대한 정보를 추출함
- RoboPoint 는 이미지 내에서 free space 를 찾아주는 등의 작업을 수행할 수 있는 spatial affordance 예측 프로그램
- CoTracker 를 활용하여 로봇 그리퍼의 경로를 추적하고 장면을 통한 움직임을 기록하며 필수 trajectories 데이터를 수집함
- 이렇게 수집된 데이터들을 활용하여 Affordance annotation set 을 생성함
Experiment
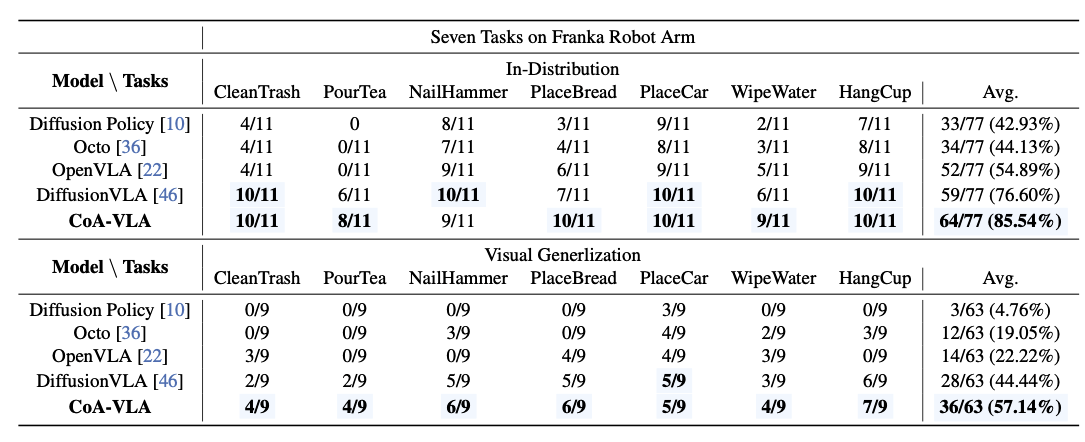
- 실제 로봇에서의 평가
- 6 DoF 를 가지는 Franka 로봇팔 활용
- 2 개의 3인칭 카메라 + 손목의 1인칭 카메라
- 차 따르기, 테이블 청소하기 등의 7가지 작업, 단기 및 장기 작업 모두 포함
- Droid 데이터셋의 39000개의 trajectory 를 활용하여 pre-training + 7가지 작업에 대한 692개의 trajectory 로 post-training
- Diffusion Policy, Octo, OpenVLA, DiffusionVLA 등과 비교해 볼 때 높은 성능을 보여줌
- 특히 조명, 방해물, 배경 등을 바꾸어 실험(Visual Generalization)할 때, 조건이 복잡해질 수록 다른 모델들과 성능 격차가 커짐
- 6 DoF 를 가지는 Franka 로봇팔 활용
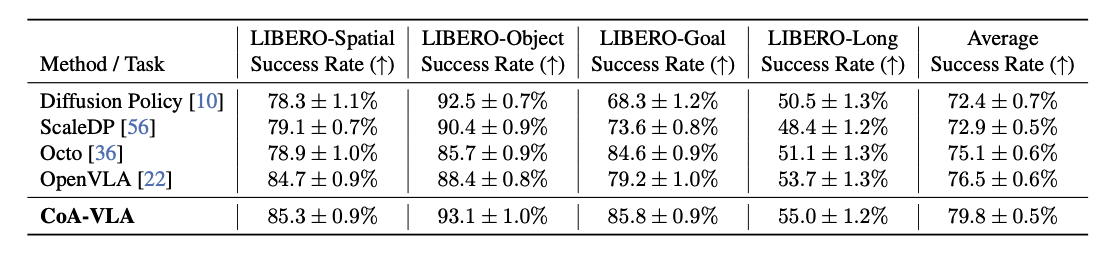
- 시뮬레이션에서의 평가
- LIBERO는 130개 이상의 언어 조건 조작 작업을 포함하는 로봇 학습 벤치마크임
- LIBERO-Spatial, LIBERO-Goal, LIBERO-Object, LIBERO-Long의 네 가지 작업 스위트에서 평가
- Diffusion Policy, ScaleDP, Octo, OpenVLA 등과 비교해 높은 성능을 보여줌

- 추가 실험
- 특정 위치에 빵을 내려놓는 테스크와 장애물을 회피하는 테스크에서 Spatial Affordance 가 도움이 되는 것을 확인함