- Published on
This Week I learned 4
Summary
1. [Paper] ProAgent: Building Proactive Cooperative Agents with Large Language Models
- LLM을 Cooperatvie Multi-Agent 환경(Overcooked Game)에 적용하는 프레임워크를 제안함
- 비언어적이고, 그리드와 같은 구조화던 데이터를 잘 처리할 수 있도록 게임 보드의 상태와 그것을 설명해주는 자연어를 함께 프롬프트 입력으로 넣어줌으로써 LLM 의 환경에 대한 이해도를 높임
- CoT 는 필수적, 어떻게 잘 활용할 것인가가 문제임
2. [Paper] LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
- Classic Planner 를 LLM 이 잘 활용하도록 만드는 프레임워크를 제안함
- 특정 도메인에 대한 적절한 Solver 가 존재하고, 그 Solver 가 일정한 구조의 입력을 받도록 되어 있다면 유용한 방법이 될 것
3. [Paper] STEPWISER: STEPWISE GENERATIVE JUDGES FOR WISER REASONING
- CoT 를 적용하여 여러 Reasoning Step 을 거쳐 최종 결과를 생성할 때, 어떤 Reasoning Step 이 최종 결과에 얼마나 좋은 영향을 미쳤는지 판별하는 judge 를 생성하는 법을 제안함
- Root 부터 Leaf 에 도달하는 과정 중간의 Reasoning Step 에 대해 적절히 평가하기 위해서는 각 Step 이 단일성을 갖고, 중단 없는 논리적인 흐름을 구성해야 함. 이러한 질 좋은 Chunks-of-Thought 를 생성하기 위해 자체 분할 능력을 갖는 모델을 파인튜닝함
- 잘 쪼개어진 Reasoning Step 별로 롤아웃(16회) 하여 최종 출력을 수집하고, 정답률에 따라 해당 Reasoning Step 이 얼마나 도움을 주었는지 계산할 수 있음. 이를 Annotation 삼아 강화학습(GRPO)을 통해 judge model 을 트레이닝함.
4. [Paper] CoELA: BUILDING COOPERATIVE EMBODIED AGENTS MODULARLY WITH LARGE LANGUAGE MODELS
- 실내 시뮬레이션 환경에서 Multi-Agent cooperation problem 을 해결하는 CoELA 프레임워크 제안
- 효율적인 의사소통을 위해 메시지를 작성하는 Communication Module 과, 완성된 메시지를 보낼 것인지 여부를 포함하여 Action 을 결정하는 Planning Module 을 분리함
- RGB-D 정보를 활용하여 3D point cloud 를 Perception Module 에서 구축하고, 여기서 추출된 정보를 Memory Module 에 저장하여 사용함
[Paper] ProAgent: Building Proactive Cooperative Agents with Large Language Models
contributions
- LLM 을 cooperative multi-agent 환경에 적용함
- 현재 Scene 을 분석하여 팀메이트의 의도를 추론하고, 그에 맞는 행동을 동적으로 선택 가능하게 함
- 학습 때 마주치지 못한 새로운 팀메이트에 대해서도 협력적인 능력을 갖춤
Related Works
- Reasoning and Planning with Large Language Models
- open-ended long-term planning: Fan et al. 2022, Wang et al. 2023b,c
- centralized LLM-based planner for both 2 players: Li et al. 2023a
- ProAgent 는 player 마다 개별적인 planner 를 둔다는 점에서 차이
- decentralized planning with facilitating cooperation through explicit communication: Zhang et al. 2023
- observation 을 통해 팀 메이트의 의도를 추론한다는 점에서 차이
- Multi-agent Coordination
- 기존 연구들은 고정적인 task 를 대상으로 주로 이뤄짐, 다양한 task 또는 모르는 시나리오에 대해서는 잘 하지 못함
- multi-task 를 학습시키는 방법에 대한 연구도 있었으나, 여전히 unseen scenario 에 대해서는 어려움
- zero-shot coordination(ZSC) 연구도 있었음
- Population based Training(PBT): Strouse et al. 2021; Zhao et al. 2023; Lupu et al. 2021; Lucas and Allen 2022; Li et al. 2023b, 2024
- Theory of Mind(ToM): ToM; Hu et al. 2021a; Wu et al. 2021; Wang et al. 2021
- 데이터 수집과 모델 최적화를 위해 상당한 양의 계산 자원이 요구됨, 해석 가능성이 낮음
5 stages of Inference pipeline
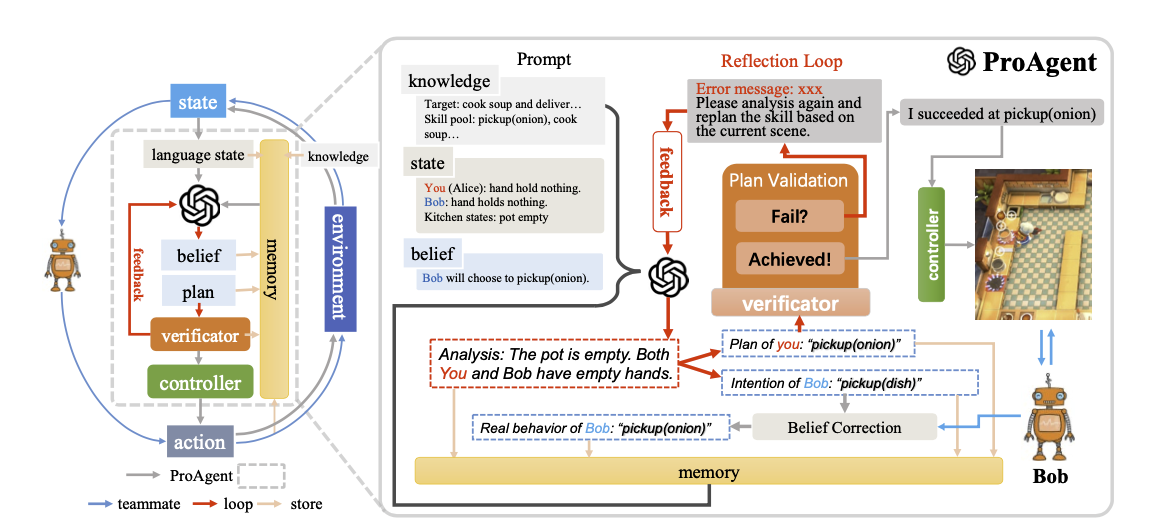
- Knowledge Library and State grounding
- High-level Skill Planning
- Belief Correction
- Skill Validation and Action Execution
- Memory Storage
Prompt Contruction
- Knowledge Library
- Planning 능력을 얻기 위해서는 LLM 의 시작 입력으로 관련 프롬프트를 넣어주는 것이 중요함
- 마찬가지로, Cooperation task 에서도 관련 정보들을 시작 프롬프트에서 잘 넣어주는 것이 중요함
- Knowledge Library 는 Task, Rules, Demos 로 구성되어 있음
- Task: LLM 이 작업의 목표와 다른 협력 에이전트에 대한 정보에 대한 이해
- Rules: 허용되는 스킬과 그렇지 않은 스킬을 규정하고, CoT와 유사한 방법으로 응답의 형식을 강제함
- Demos: 실제 사례를 통해 기억력을 강화하고, 규칙을 따르도록 돕는 역할. 장면 설명, 분석, 그리고 원하는 행동(선택된 스킬)으로 구성. 옵셔널
- Grounding tensor state to language-based state
- LLM 이 현재 state 를 정확히 이해할 수 있도록 하기 위해서는 환경으로부터 얻은 symbolic state 를 language-based state 로 잘 변환하는 것이 중요함
- 게임 상태는 비언어적이고, 구조화된 데이터(기호 그리드)인 경우가 많은데, LLM 은 이를 잘 처리하지 못함
- Overcooked 게임의 특정 시점의 게임 보드 상태와 그것을 설명하는 자연어를 프롬프트로 함께 넣어주어 게임의 현재 상태에 대한 이해도를 높이겠다는 것임

Cooperative Reasoning and Planning
- 팀메이트가 수집한 정보를 처리하는 방식으로는 explicit communication 과 implicit modeling 두 가지가 연구되어옴
- 명시적 통신은 다른 에이전트로부터 직접 메시지를 받아 계획이나 상태를 알아내는 것으로, LLM 의 일반화 능력을 저해할 수 있다는 단점을 가짐
- 암묵적 모델링은 팀메이트의 행동을 관찰하고 모델링하여 그들의 미래 행동을 예측하는 것으로, 팀 메이트의 전략 변화에 불안정하다는 단점
- ProAgent 에서는 다음 세 가지 모듈을 도입하여 두 가지 단점을 줄이는 방향 제시
- Memory 모듈: 테스크에 대한 과거 경험과 지식을 저장함
- Knowledge Library: 작업의 레이아웃, 규칙, 데모 등 변화하지 않는 영구적인 정보 저장
- Trajectory: 일시적인 상호작용을 기록함, FIFO 로 일정한 길이를 가지는 메모리, 최근의 맥락을 이해할 수 있도록 하는 것이 목적. 최신 "언어 기반 상태", 상황 "분석", 팀원 의도에 대한 "신념", 사용된 "스킬” 등이 포함
- Planner 모듈: CoT 를 적용하여 단계별 사고를 거친 후 최종 결정을 할 수 있도록 유도
- 입력으로 들어온 정보를 분석하고, 다음 행동을 예측한 후, 가장 합리적이고 효과적인 스킬을 선택하도록 하는 것이 목적
- Verification 모듈: LLM 이 생성한 계획 중에서 비합리적이거나 결함이 있는 부분을 조사하고 식별하는 역할
- multi-round prompt 를 통해 작동함
- Preconditions Check, Double-check, and Error Conclusion 등과 같은 프롬프트가 있음
- Preconditions Check: 현재 계획이 실행 가능한지 확인하는 단계. 현재 장면과 실패한 기술을 입력으로 사용하여 프롬프트 생성. CoT 도 적용될 수 있음(”Analysis of why I cannot execute this skill in the current scene step by step”). 각 Skill 은 자연어 또는 의사 코드로 표현 가능함.
- Belief Correction
- 팀원의 행동 예측을 기록해두고, 실제 행동과 다른 경우 다음에는 보다 정확히 예측할 수 있도록 하는 과정을 말함
- 두 가지 전략
- Replacement Method: 잘못된 예측 의도를 실제 행동으로 교체함
- Annotation Method: 원래 예측은 그대로 두되, 예측이 틀렸음을 기록해둠
- 반복적인 개선을 통해 팀메이트의 미래 행동에 대한 예측 가능성을 지속적으로 높혀나가도록 함
- Controller 모듈
- 계획의 대상은 high level skill 들로, 실제 환경의 action space 와는 차이가 있음. 이를 low level action 으로 변환하는 과정이 필요한데, controller 모듈이 담당함
- 스킬을 여러 단계의 저수준 행동으로 분해하고 행동이 완전히 실행되면 추론 구성 요소에 피드백 신호를 제공할 수 있는 고정된 규칙을 설정함
- 규칙 기반 경로 탐색 알고리즘 또는 언어 기반 강화 학습(language-grounded reinforcement learning) 방법을 사용할 수 있을 것
- 논문에서 주로 다루고자 하는 내용이 아니므로, BFS 기반의 Overcooked-AI 환경에 내장된 컨트롤러를 선택함
- Memory 모듈: 테스크에 대한 과거 경험과 지식을 저장함
감상
- 편하게 읽히지 않는 논문. 3개의 주요 모듈에 대해 언급하면서 4개의 모듈을 제시하는 등, 혼란스러운 부분이 있음
- 메모리, env to language form 로 프롬프트를 잘 구성하고 CoT 를 활용하여 reasoning 성능을 높이면 Cooperative Agent 를 만드는 데에 도움이 된다
[Paper] LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
- LLM 은 long-horizon robot planning problem 잘 해결하지 못함. 반면 Classic planner 는 최적에 가까운 솔루션을 찾아냄. 이러한 장점을 조합하여 LLM 이 Classic planner 를 활용하여 정답을 찾아내는 방법을 제시함
- 로봇의 액션 생성을 위해 제안된 방법
Intuition
- LLM 은 planning 또는 long-horizon reasoning 을 잘 수행하지 못함
- 반면 어떤 대상을 묘사하거나 번역하는 것은 잘함
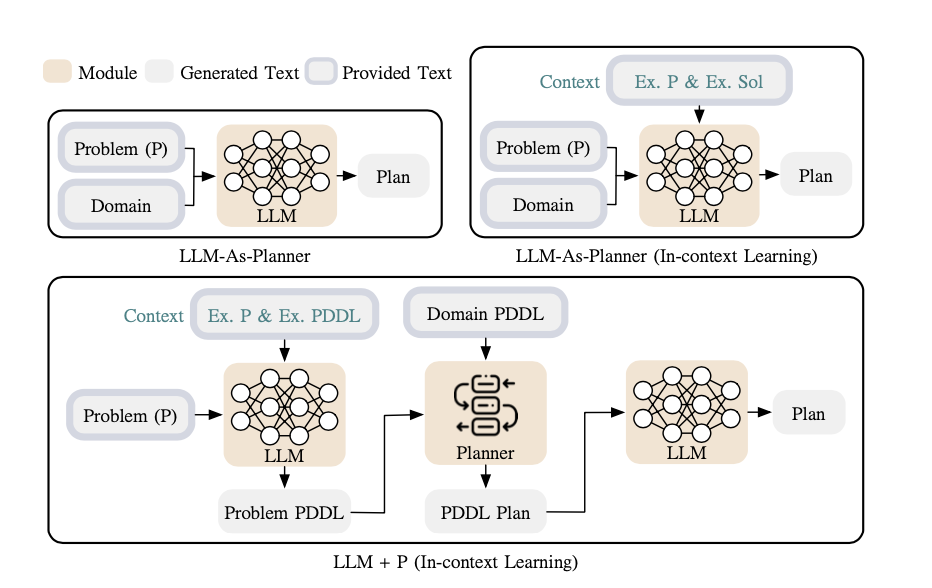
- 그렇다면 자연어로 된 Task 를 PDDL(Problem Domain Definition Language) 로 번역하여 해결한 뒤, 그 결과를 자연어로 다시 번역하면 되지 않을까.
Method
- LLM을 PDDL Writer 로 쓴다 + In context learning 을 적용한다
- PDDL 은 다음 두 가지로 구성, domain PDDL 을 어떻게 생성할 것인지는 또 다른 문제임. 논문에서는 존재하는 것으로 가정하고, 이 부분은 다루지 않음
- domain PDDL: task 의 환경과 규칙 등 world 에 대한 설명 - 로봇이 선택할 수 있는 action 의 종류 등
- problem PDDL: 구체적인 문제 상황에 대한 설명
- 순서
- [문제에 대한 설명 + In Context(example)] 등을 입력으로 하여 LLM 을 통해 현재 task 를 표현하는 problem PDDL 을 생성함
- 생성된 problem PDDL 을 domain PDDL 과 함께 classic planner 에 입력으로 전달하여 그 결과를 받음
- classic planner 의 출력을 다시 LLM 을 활용하여 자연어로 표현함

감상
- 특정 domain 에 LLM 을 적용하여 복잡한 문제를 해결하는 데에 도움이 될 수 있을 것으로 보임
- LLM 의 강점과 약점을 잘 분석하여, 적절히 활용하는 방법으로 보임
[Paper] STEPWISER - STEPWISE GENERATIVE JUDGES FOR WISER REASONING
- 복잡한 문제를 푸는 데에 multi-step reasoning 을 적용할 수 있으나, reasoning step 중간에 논리적으로 적절치 않은 부분이 생기면 좋은 결과에 도달하기 어려움. 이러한 문제를 해결하기 위해 reward model 을 도입하려는 시도가 있었으나, (1) 설명을 제공하지 않거나 (2) 일반화가 어렵다는 한게를 가짐. 여기서는 classifier 가 아닌, reasoning step 자체에 대해 추론하는 “generative judge” 를 도입하여 이러한 문제를 해결하려 함
Improving the Reliability of Multi-Step Reasoning in LLMs
- 두 가지 방법
- ORMs(Outcome Reward Models): 최종 정답에 대해서만 평가하는 방법
- PRMs(Process Reward Models): 중간 step 들에 대해서도 평가하는 방법
- human annotation 된 작은 데에터 셋에 대해서는 PRMs 이 ORMs 보다 성능이 좋았음
- 최근에는 annotation process 를 자동화하는 것에 관심을 보이는 연구들이 있었음
- multi-step reasoning 의 각 단계의 품질을 자동으로 평가하고 그 주석을 생성하는 것
- Monte Carlo(MC) rollout 을 사용하여 각 step 의 Q value 를 추정하는 연구 - Wang et al(2023)
- [MATH-SHEPHERD] VERIFY AND REINFORCE LLMS STEP-BY-STEP WITHOUT HUMAN ANNOTATIONS https://arxiv.org/pdf/2312.08935
- chunk of thought(중간 단계의 아웃풋)가 최종 결과에 얼마나 긍정적으로 영향을 미쳤는지에 대한 연구
- 잘못된 step 를 효율적으로 찾기 위해 binary search method 를 사용하는 연구 - Luo et al(2024)
- 중간 step 과 최종 출력 간의 이론적인 연결성에 관심을 갖는 연구도 있음
- KL-regularized Markov Decision Process - Zhong et al(2024), Rafailov et at(2024)
- 논문의 핵심 질문: 몬테카를로 샘플링에서 얻은 풍부하고 명시적인 단계별 신호가 RL 기반 보상 훈련에 기존의 방식보다 더 효과적인 학습 신호로 작용하는지 여부
- 최종 검증된 답변에 기반한 단계별 라벨을 사용하여 판단 모델을 훈련하는 데 중점
- He et al. (2025) 의 연구와는 차이점이 있음
Judge architecture
- 두 가지 판단 모델
- Discriminative PRMs
- 가장 직접적인 방식, classification 문제로 바라보는 관점
- 언어모델의 최종 레이어만 linear head 로 교체하고, binary label 을 출력하도록 cross-entropy 학습하는 것이 대표적인 방법
- 판단 결과만 제공하고 그에 대한 설명(justification)을 제공하지 못한다는 한계
- Generative judges with CoT reasoning
- 최신 페러다임으로, 평가 자체를 하나의 reasoning task 로 바라보는 관점
- preference learning 과 ORMs 연구에 주로 사용되어 왔으나, 최근에는 stepwide judges 의 맥락에서도 연구가 이뤄짐
- 본 연구도 이와 유사하나, 알고리즘 설계에서 큰 차이를 보임
- offline rejection sampling fine-tuning을 사용하는 Zhao et al. (2025), Khalifa et al. (2025)의 연구는 초기 몇 스텝 이후에는 성능 저하 문제를 보이나, 본 연구는 온라인 강화학습 트레이닝에 집중함
- Zha et al. (2025)의 연구도 RL을 사용하지만, sparse, trajectory-level supervision 한 수준에 그침. 반면 본 연구는 rollouts 를 통한 dense, stepwise supervision 에 기반함.
- Discriminative PRMs
Method
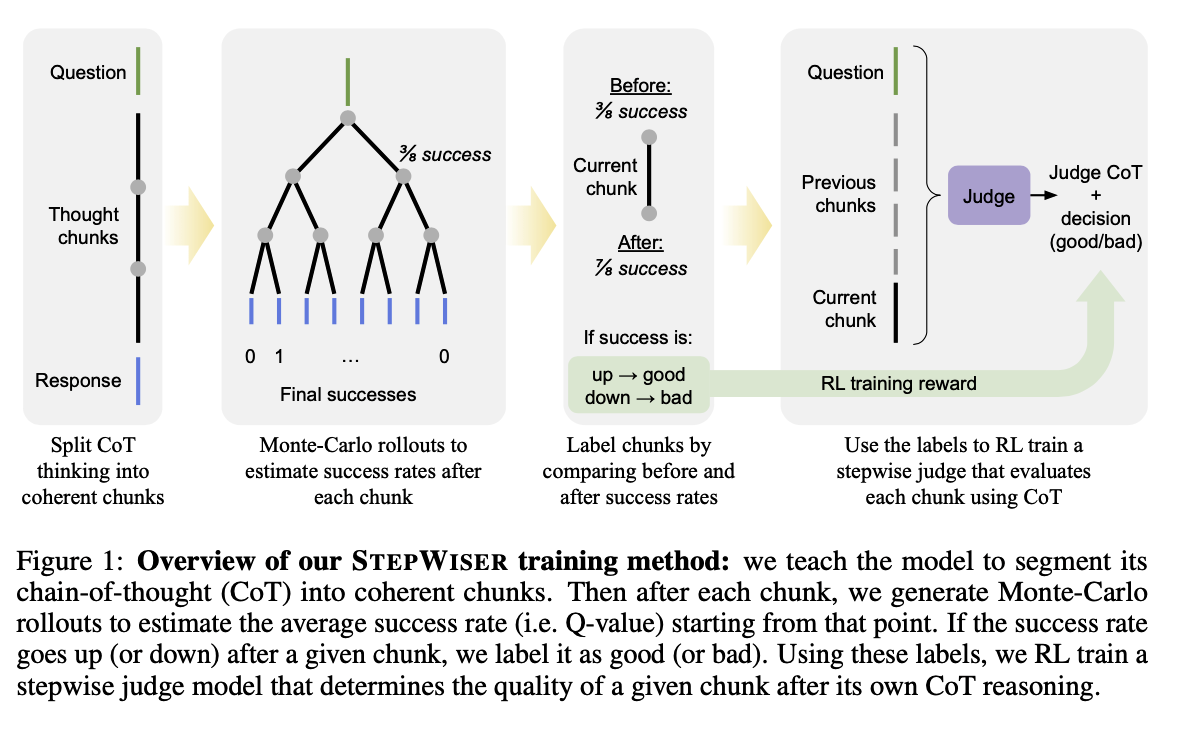
- 기본 정책 모델에 CoT를 일관성 있고 유익한 추론 덩어리(reasoning chunks)로 자체 분할(self-segment)하는 능력을 부여함 → 어떻게 segment 하는지 확인해보자
- 이 분할된 사고 덩어리를 Chunks-of-Thought 라고 부름
- 기본 정책 모델(base policy model) 은 CoT를 생성해내는 기본 언어 모델을 말함
- Chunks-of-Thought 에 주석을 달아 binary target labels 를 포함하는 훈련 데이터를 생성함
- 주어진 Chunk 와 함께 여러 번 롤아웃 하여 얻은 최종 결과물을 평가하여 해당 Chunk 가 긍정적인 영향을 미치는지, 그렇지 않은지(q-value)를 알 수 있음
- GRPO 알고리즘으로 온라인 강화학습을 통해 모델을 업데이트함.
Chunks-of-Thought(COT GENERATION WITH SELF-SEGMENTATION)
- step 단위로 reasoning step 을 평가한다고 할 때 가장 중요한 것 중 하나는 “Step” 을 어떻게 정의할 것인가 임
- 가장 많이 사용되는 방법 중 하나는 pre-defined token 을 사용하는 것임(”Step1, … Step2, ….” or double line breaks)
- 이러한 휴리스틱한 방법은 논리적으로 완전치 않거나, 독립적이지 않은 세그먼트를 생성할 가능성이 높음

- 모델이 자체적으로 더 의미있는 수준의 step 으로 분할하여 생성하도록 가르치는 방법 제안
- high-quality reasoning step 을 어떻게 정의할 것인가? - 다음 세 가지 기준 제시
- 단일 목적: 하나의 chunk 는 명확하고 단일한 목적을 수행해야 함
- 논리적 응집성: chunk 내의 모든 라인은 연속적이고 또 중단 없는 논리적인 흐름을 형성해야 함, 추론의 초점이나 목적이 바뀌는 즉시 새로운 chunk 를 시작하여야 함
- 명백한 전환: 문제 해결의 새로운 페이즈로 진입할 때에는 항상 새로운 chunk로 시작되어야 함
- 자체 분할 능력이 중요한 이유
- 논리적으로 완전한 step 을 생성함으로써, judge model 에 더욱 나은 맥락을 제공하고 평가 정확도를 향상시킬 수 있음
- Trajectory 당 step 의 수를 줄이고, 이를 통해 annotation 의 숫자도 줄어들게 되어 효율성을 높일 수 있음
- high-quality reasoning step 을 어떻게 정의할 것인가? - 다음 세 가지 기준 제시

Stepwise data annotation
- 각 step 에 대한 평가를 사람이 하는 방법도 있지만, Monte-Carlo Estimation 과 같은 방법으로 자동화하기도 함. 여기서는 이 방법을 사용하여 Q-Value 를 측정할 것임
- Q-Value 계산은 다음 수식과 같이 estimate 할 수 있음
- 는 다음과 같이 binary label 로 처리함, 정답을 도출하는 데에 도움이 되면 +, 그렇지 않다면 -
- Wang et al(2023), Xiong et al(2024b) 에서 제안된 것으로, 여기서는 “Absolute Q value thresholding(Abs-Q)”이라고 부를 것
- Abs-Q 의 단점 중 하나는 binary 하기 때문에, success probability 에 미치는 영향을 정확히 보여주지 못한다는 점임(the dynamics of the reasoning process 에 둔감함)
- 10% → 50% 인 경우와 60% → 55% 인 경우에 Abs-Q 는 차이가 없음
- 이러한 단점을 보완하기 위해 Setlur et al(2024) 에서는 advantage function 을 도입한 effective reward 를 고려함
- 이를 반영하면 다음과 같이 annotation 을 변경할 수 있음, 여기서는 Relative Effective Reward Thresholding(Rel-Effective) 라고 부를 것
- 비슷하게 다음과 같은 방법도 고려함. 이는
Rel-Ration라고 부를 것
- 이러한 annotation 방법을 통해 우리는 각 step 마다 그것이 도움되었는지, 그렇지 않은지를 나타내는 label 를 확보할 수 있게 됨
Training the Judge via RL

- reasoning step 별로 적절히 쪼개어진 step 과, 각 step 마다 얼마나 추론에 도움이 되는지 평가한 label 이 확보된 상태 → 이제 어떻게 학습시킬 것인가의 문제
- Classifier 를 만드는 것보다, 자체 CoT 분석을 생성하도록 하는 것이 더욱 효과적이라는 최근 연구
- 강화학습을 통해 judge model 을 트레이닝하고, policy model 의 매 추론 단계마다 추론을 실시함. 이때 judge model 은 분석 근거를 생성한 다음 최종 판단을 내리므로, 평가 과정, 이유가 제공됨.
- Task formulation and prompt dataset balancing
- 먼저 전체 trajectory 를 step 단위의 training prompt 로 쪼갬
- model 은 다음 세 가지를 제공 받음
- original problem
- reasoning history
- new reasoning chunk
- 모델은 자체 CoT 를 생성하며 new reasoning chunk 가 얼마나 옳은지 판단하도록 프롬프팅됨
- stepwide judge training 에서 자주 간과되는 부분 중 하나는 stepwide label 간의 imbalance 문제
- 긍정적이라고 annotation 된 reasoning step 이 부정적이라고 되어 있는 것보다 많음
- 이렇게 되면 모델 입장에서는 긍정적이라고만 평가하더라도 일정 수준 이상의 점수를 확보할 수 있게 됨(degeneration)
- 따라서 프롬프트 데이터셋에서 긍정/부정 샘플의 갯수가 서로 동일하도록 만들어줌
- Reward and RL training
- 각 에서, judge 의 판단이 annoation 과 동일하면 1, 그렇지 않으면 0 의 reward
- GRPO 알고리즘을 사용함
감상
- CoT 의 reasoning step 을 segmentation 하는 방법과, 그것을 judge 하는 모델을 만들기 위해 RL 을 사용하였다는 점에서 흥미로웠음
- GRPO 를 활용할 수 있는 분야가 많을 수 있겠다 - 쉽게 생각한 것은 RAG 의 Retriever? → 찾아보니 있음ㅋㅋㅋ
추가로 읽어보기
- GRPO - Deepseekmath: Pushing the limits of mathematical reasoning in open language models.
[Paper] BUILDING COOPERATIVE EMBODIED AGENTS MODULARLY WITH LARGE LANGUAGE MODELS
- ICRL 2024
- Multi-Agent cooperation problem 을 다룸
- decentralized control, raw sensory observation, costly communication, multi objective tasks, embodied agent
- 많은 연구가 비용 없는 통신, 공유된 관찰을 통한 중앙 집중식 제어에 의존했음
- CoELA(Cooperative Embodied Language Agent) 를 통해, 다른 에이전트와 협력하여 장기적인 작업 수행 능력을 높일 수 있도록 함
- CoELA 는 Perception, Memory, Communication, Planning, Execution 의 5가지 모듈로 이뤄져 있음
- LLAMA-2 를 데이터셋으로 파인튜닝하여 높은 성능을 달성할 수 있도록 함
- 자연어로 통신하도록 하였으며, 이를 통해 인간-에이전트 상호작용에서 더욱 효과적으로 협력 가능함을 보임
Contributions
- LLM 을 embodied agent 에 적용해보려는 연구가 다수 있었음
- 하지만 decentralized setting + costly communication 의 조건에서 사람 또는 다른 에이전트와 협력적으로 동작하는 embodied agent 에 대한 연구는 부족했음
- 현실 세계는 costly communication. 실제 통신에는 시간이 소요되므로, 에이전트들이 단순히 계속 소통할 수는 없음
- 구체적인 컨트리뷰션은 다음과 같음
- Decentralized control, Complex partial observation, costly communication, long-horizon multi-objective tasks + multi-agent embodied cooperation problem 을 공식화함
- LLM 의 계획 및 커뮤니케이션 능력을 활용하여 새로운 cognitive-inspired modular framework 를 제안함
- 신뢰할 수 있는 인간-에이전트 상호작용을 평가하기 위해 user study 를 수행함
Related works
- Multi-Agent cooperation and Communication
- cooperative agent 와 관련하여 다양한 연구가 있어 왔음
- 하지만 서로 간에 의사 소통이 없거나, continuous vector 와 같이 해석 불가능하거나, 제한적인 갯수의 심볼로만 통신 하는 경우가 많았음
- 본 연구는 사람처럼 분산 에이전트 간에 자연어로 효율적인 의사소통을 하는 경우를 다룸
- Language Agents
- LLM 의 연속적인 의사 결정 능력을 embodied environment 에 적용하려는 다양한 연구가 있어 왔음
- 본 연구는 multi agent cooperation problem, costly communication, long-horizon multi-objective tasks 를 다룬다는 점에서 더욱 어려운 문제임
DEC-POMDP-COM
- DECentralized Partial Observation Markov Decision Process
- : 에이전트의 수
- : 유한한 State 집합
- : 에이전트 의 Action 집합
- : World Action 들의 유한 집합
- : Message 를 전송하는 Communication Action
- : 에이전트 의 Observation 집합
- : 에이전트가 센서를 통해 받는 World Observation
- : 팀원들로부터 받을 수 있는 가능한 Message 집합
- : 상태 에서 결합 행동 을 취한 후 새로운 상태 가 달성될 확률을 뜻하는 joint transition model
- : 에이전트들이 완료해야 할 여러 하위 목표가 있는 과제
- : 팀에 대한 보상 함수
- : 행동 에 대한 비용
- : 하위 목표 가 세계 상태 에서 만족되는지 확인하는 지시 함수
- : discount rate
- : planning horizon
Problem definition
- 2 decentralized intelligent embodied agent(including human)
- long-horizon rearrangement task
- 여러 개의 방이 있는 실내 환경
- Action Space = Navigation Action + Interaction Action + Communication Action
Framework
- CoELA: a Cooperative Embodied Language Agent - 5가지 모듈로 구성됨
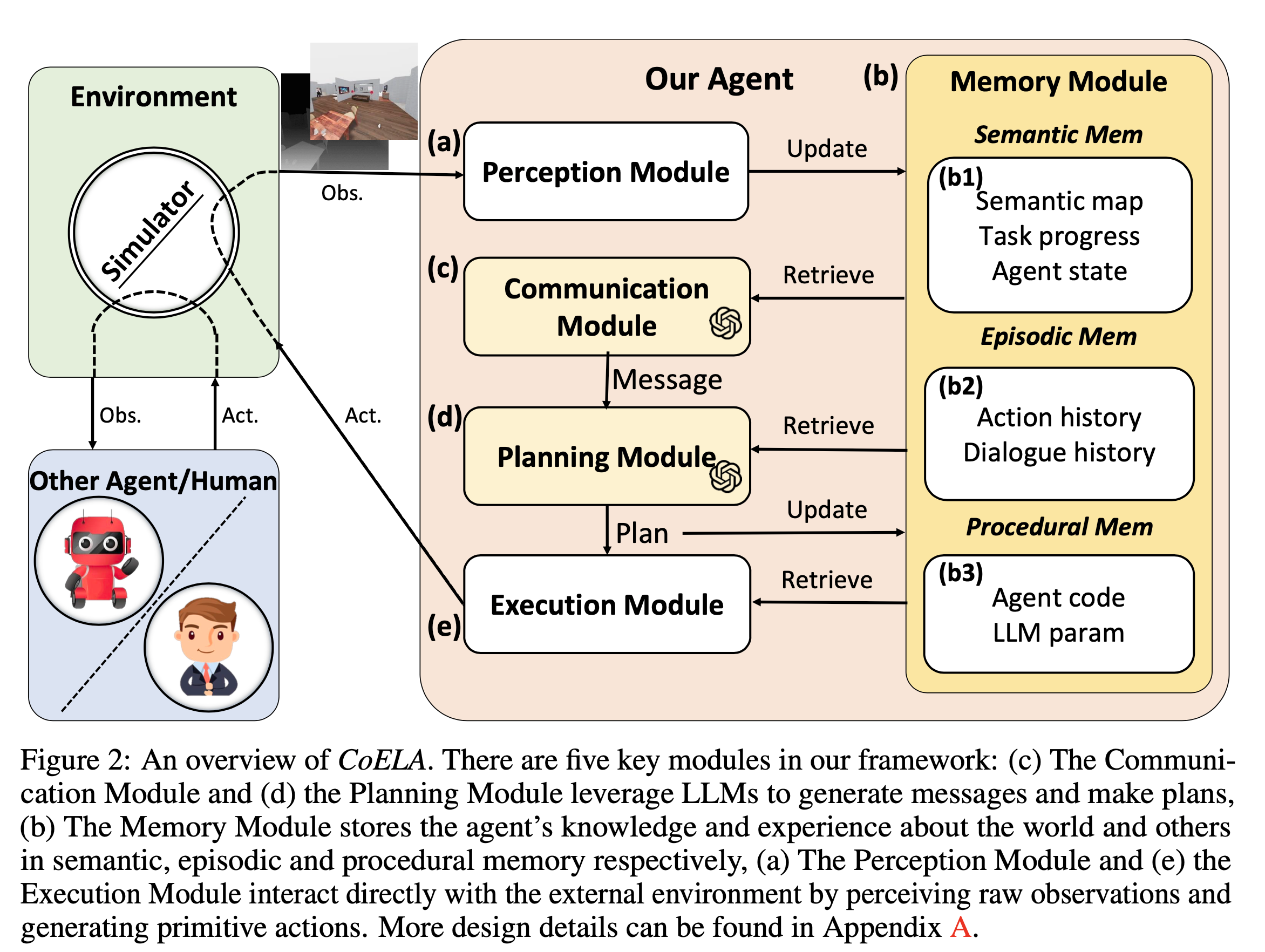
- 가장 먼저 Perception module 에서 수용한 환경에 대한 sensory observation 으로 Memory Module 을 업데이트 함
- 효율적인 의사소통을 위해 2 step method 를 사용함
- 무엇을 보낼 것인지 먼저 결정하고, Memory module에서 관련 정보를 검색한 뒤, LLM 을 활용하여 보낼 최적의 메시지를 결정함
- 결정된 메시지를 보낼 것인지, 다른 계획을 선택할 것인지 결정함. Planning Module 활용하여 Memory module 의 검색 결과와 현재 상태에 대해 제안되는 다양한 Action 을 고려하여 어떤 계획을 취할 것인지 결정
- 이렇게 생성된 계획은 Episodic Memory 를 업데이트하는 데에 사용됨
- Execution Module 은 Procedural Knowledge 를 검색하여 high-level plan 을 primitive actions 로 변환하는 역할 수행
Perception Module

- Raw Observation 을 잘 처리하여 이후 고수준 추론에 유용한 형태로 만드는 것이 필요함
- Mask-RCNN 을 사용하여 RGB 이미지에서 segmentation mask 를 생성함 + RGB-D 이미지를 사용하여 3D point clouds 를 구축함
- RGB-D = RGB + Depth , 각 픽셀이 카메라로부터 해당 지점까지 얼마나 떨어져있는지를 나타내는 이미지
- Depth 를 어떻게 구할까? - 우선 여기서는 시뮬레이션 환경을 사용하다보니 확보 가능한 것 같음
- 현실에서 Depth 를 구하기 위해서는 특수한 카메라를 사용하는 것 같음: Stereo carmera, ToF(Time-of-Flight), LiDAR
- 3D point clouds: 3차원 공간상의 점들의 집합
- RGB-D = RGB + Depth , 각 픽셀이 카메라로부터 해당 지점까지 얼마나 떨어져있는지를 나타내는 이미지
- 여기서 states of the key objects 와 같은 고수준 정보를 추출하고, local semantic map 을 구축함
Memory Module

- 인간의 long-term memory 에서 영감을 받아 메모리 모듈 설게함
- 세 가지 기억 유형
- Semantic Memory
- world 에 대한 지식을 저장
- Semantic map: Perception Module 에서 인식한 local map 을 기반으로 구축 및 업데이트. 목표 객체, 목적지, 에이전트 및 탐색/점유 영역을 나타냄
- Task Progress: 작업의 진행 상황, 초기에는 0으로 셋팅
- 자신의 상태: 자기가 어디에 있는지, 무엇을 들고 있는 지 등
- 다른 에이전트의 상태: 다른 에이전트가 관찰될 때마다 업데이트
- 다른 에이전트에 의해 환경이 변화할 수 있음 → 이를 고려할 수 있도록 하는 것이 중요할 것
- Episodic Memory
- 과거 경험들을 저장함
- action history: 에이전트가 수행한 action 들의 기록
- dialogue history: 에이전트 간에 주고받은 메시지들에 대한 기록
- 효율성을 위해 FIFO 로 관리
- Procedural Memory
- 실제 환경에서 high-level plan 을 수행하는 방법에 대한 지식
Communication Module
- 에이전트가 무엇을 보낼 것인가를 결정하는 데 사용
- LLM 의 강력한 free-form 언어 생성 능력을 활용함
- 다음 과정을 따라 생성함
- 관련 정보 검색 - semantic map, task progress, 자신 / 다른 에이전트의 상태, history 등
- 텍스트 설명 변환: 검색된 정보를 텍스트로 변환
- LLM 프롬프트 구성: Instruction Head, Goal desc, State desc, Action history, Dialogue history 등을 연결하여 프롬프트를 구성함
- 메시지 생성 제약 추가 - 간결하고 협력적인 메시지 생성을 위해 제약 조건 추가
- e.g. “Note: The generated message should be accurate, helpful, and brief. Do not generate repetitive messages.”
Planning Module
- 협력에 있어 효율성을 최대화할 수 있는 행동을 결정하도록 함 - Agent 가 어떠한 행동을 취할지 결정하는 데에 중점
- 다음과 같은 순서로 진행
- 관련 정보 검색 및 텍스트 변환 - communication module 의 그것과 유사
- Action List 컴파일: 현재 상태와 Procedural Memory 에 저장된 지식을 활용하여 LLM 이 선택할 수 있는 Action List 를 생성함
- e.g. 방으로 이동, 현재 방 탐색, 컨테이느 잡기, 들고 있는 컨테이너 내려 놓기 등
- LLM 프롬프트 구성
- Zero-shot CoT 적용하여 더 나은 Planning 생성
Execution Module
- 실행 가능한 primitive actions으로 변환하는 역할
- 다음과 같은 순서로 진행
- procedural memory 검색
- primitive action 생성
- 재배치 작업의 경우, A-star planner 를 활용하여 내비게이션을 위한 최단 경로를 찾도록 함
- Execution Module 을 제거하고 Planning Module 이 저수준 제어를 직접 하도록 시도했을 때, 추론 과정이 매우 느려지고 어떤 작업도 완료하기 어려워지는 것을 확인함 → Execution Module의 중요성 입증
Experiment Setting
- 두 가지 시뮬레이션 환경에서 수행
- TDW-MAT - ThreeDWorld Multi-Agent Transport
- ThreeDWorld Transport Challenge 를 확장한 다중 에이전트 물리 작업 환경
- target objects 를 container 를 활용하여 목표 지점으로 최대한 많이 운반하는 임무(container 사용 시 3개, container 가 없다면 2개씩 운반 가능)
- target objects:
- 음식(사과, 바나나 등 6종) + 그에 맞는 3가지 유형의 컨테이너 → 부엌에 위치
- 물건(계산기, 마우스 등 6종) + 그에 맞는 3가지 유형의 컨테이너 → 사무실에 위치
- observation space: 1인칭 512x512 RGB-D 이미지
- action space: 총 6가지 action, 커뮤니케이션에도 프레임을 소모하도록 되어 있음
- Move forward: 0.5m 앞으로 이동.
- Turn left/right: 15도 왼쪽/오른쪽으로 회전.
- Grasp: 객체를 잡는 행동 (객체에 가까이 있을 때만 가능).
- Put In: 들고 있는 객체를 컨테이너에 넣는 행동 (한 손에 객체, 다른 손에 컨테이너를 들고 있을 때만 가능).
- Drop: 들고 있는 객체를 떨어뜨리는 행동.
- Send message: 다른 에이전트에게 메시지를 보내는 행동 (프레임당 최대 500자).
- Metric: 운반율
- ThreeDWorld Transport Challenge 를 확장한 다중 에이전트 물리 작업 환경
- C-WAH - Communicative Watch-And-Help
- 에이전트 간의 메시지 전송을 가능하게 함
- 메시지 전송은 다른 행동들과 마찬가지로 한 타임스텝을 소모하며 메시지 길이에 상한선이 있음
- Task Types: 총 5가지 유형의 가사 활동으로 정의
- 오후 차 준비 (Prepare afternoon tea), 설거지 (Wash dishes), 식사 준비 (Prepare a meal), 식료품 정리 (Put groceries), 식탁 차리기 (Set up a dinner table)
- Observation Space
- symbolic observation: Watch-And-Help 챌린지 설정과 동일하게, 에이전트는 자신이 있는 방의 모든 객체 정보를 받을 수 있음
- visual observation: 1인칭 시점의 256x512 RGB 이미지 및 깊이 이미지를 받음
- Auxiliary Observations: 에이전트의 시뮬레이션 세계 내 위치 및 다른 에이전트들이 보낸 메시지 등이 포함됨
- Action Space: Watch-And-Help Challenge와 유사하되, send message action 이 추가됨
- Walk towards: 에이전트가 있는 방의 객체 또는 방으로 이동.
- Turn left/right: 30도 왼쪽/오른쪽으로 회전.
- Grasp: 객체를 잡는 행동.
- Open/Close: 닫힌/열린 컨테이너를 열거나 닫는 행동.
- Put: 들고 있는 객체를 열린 컨테이너에 넣거나 표면 위에 놓는 행동.
- Send message: 다른 에이전트에게 메시지를 보내는 행동 (한 번에 최대 500자).
- Metric: 작업을 완료하는 데에 걸린 평균 스텝 수
- Baseline models
- MCTS-based Hierarchical Planner(MHP)
- MCTS(Monte Carlo Tree Search) 기반의 상위 수준 플래너와 회귀 계획(regression planning) 기반의 하위 수준 플래너를 사용함
- Rule-based Hierarchical Planner(RHP)
- 휴리스틱 규칙 기반의 상위 수준 플래너를 통해 탐색, 객체 줍기, 컨테이너 줍기, 배치 등의 계획을 선택함, Frontier Exploration Strategy 를 사용함
- Multi-Agent Transformer(MAT)
- centralized decision transformer 로 공유된 관찰로부터 행동을 생성하는 Multi-Agent Reinforcement Learning (MARL) 모델
- MCTS-based Hierarchical Planner(MHP)
Experiment Results
- 다른 Agent 와의 협력
- CoELA 는 Baseline Agent 와 더욱 잘 협력함
- CoELA 에서 LLAMA-2 를 파인튜닝하여 사용하면 GPT-4 와 비슷한 성능을 보여줌
- CoELA 는 효율적인 의사소통과 효과적인 cooperative action 을 보여줌
- 사람과의 협력
- 인간이 조종하는 Agent 와 MHP, CoELA, CoELA without communication 을 비교함
- CoELA 가 MHP 보다 높은 성능을 보임
- 단 커뮤니케이션이 없는 모델은 성능 저하를 보임
- 특히 자연어로 의사소통하는 CoELA 를 더욱 신뢰하고 효율적으로 협력함
Analysis
- 강력한 LLM 의 필요성 - GPT-4 대신 GPT-3.5 로 수행한 경우 작업 완료를 위해 더욱 많은 스텝을 필요로 함
- 의사 소통의 효과성 - 자연어로 의사소통하는 것이 인간과의 협력에 유리함
- Memory/Execution module 의 효과성 - Memory Module 을 제거할 경우 작업 완료를 위한 스텝이 거의 2배로 늘어남. Execution module 또한 제거시 효율성이 떨어짐
- 한계: 3D 공간 정보 활용 제한, 저수준 행동에 대한 효과적인 추론 부족, 복잡한 추론의 불완전한 성능
아이디어
- Cooperative Multi-Agent 문제를 MDP 로 표현하는 방법에 대해 알게되어 흥미로움
- VLM/VLA 을 사용하지 않고 있음. VLM/VLA 을 사용하면 framework 를 단순화할 수 있지 않을까
- Memory 를 관리하는 방법, Planning 을 수행하는 방법, Communication Message 를 작성하는 방법, Execution code 를 생성하는 방법 등에 관해 참고해 볼 만한 논문
- 사용된 환경에 대해서도 확인해 볼 필요가 있어 보임