- Published on
This Week I learned 3
Summary
1. [Dev] API 인증 방식
- Basic 과 Bearer 가 대표적
- Basic 은
USER:PASSWORD를 base64 로 단순 인코딩 - Bearer는 Token 기반 인증으로, 무기명 채권(Bearer bond)에서 유래
- 토큰 단위로 유효기간 설정, blacklist 처리가 가능해 Bearer 가 더 안전
2. [Dev] Redis 가 빠른 이유
- In memory, simple key-value 구조(), 싱글 스레드
- 싱글 스레드의 경우 동시성 처리에 따른 비용과 단순한 구조의 이점이 있음
3. [Paper] A Survey on Large Language Model based Autonomous Agents
- Autonomous Agent 를 구성하는 네 가지 요소: Profiling, Memory, Planning, Action
- Memory 는 Short-term(in-context) 과 Long-term(external storage) 으로 나누어짐
- Planning 은 외부 피드백의 적용 여부, Reasoning Tree 의 구조 등으로 나누어짐
4. [Paper] VOYAGER: An Open-Ended Embodied Agent with Large Language Models
- Minecraft 에서 자율적으로 세계를 탐색하고 스스로 발전하는 embodied agent
- Automatic Curriculum: 다양한 작업을 시도하는 방향으로 프롬프팅(Novelty Search)
- Skill Library: Agent 의 행동 저장소. Description 을 GPT-3.5 로 임베딩하여 관련있는 Action 을 검색. embedding 이 key, 실행 가능한 code 가 value
- Iterative Prompting Mechanism: 환경 피드백, 실행 오류 및 반복적인 자가 검증으로 적절하고 안전한 Skill 구성
- VLM, VLA 를 사용하지 않음
5. [Paper] ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
- Minecraft 에서 VLA 를 사용하여 다양한 테스크를 수행하는 방법에 대해 다룸
- 두 가지 프레임워크: End-to-End와 Hierarchical, Hierarchical 은 communication protocol 에 따라 분류 가능
- Visual-Temporal Context Prompting: Hierarchical 프레임워크에서 사용 가능한 새로운 communication protocol 제안
- RGB 이미지와 대상 객체를 하이라이트하는 Segmentation map 을 함께 이미지 입력으로 활용
- Segmentation Map 을 생성하기 위해 Molmo와 SAM-2 를 사용함
6. [Paper] JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse
- Minecraft 에서 VLA 를 사용하여 다양한 테스크를 수행하는 방법에 대해 다룸
- ActVLP: Trajectory 로 파인튜닝 하는 것을 넘어 world 에 대한 이해를 높이기 위해 추가적인 post-training 제안
- World와 관련된 QA, VQA, spatial grounding 데이터셋으로 먼저 학습(VLM 모델을 학습시킬 때와 동일한 데이터 포맷)하고 Action 을 결정하도록 파인튜닝
[Dev] API 인증 방식
Basic 인증
- HTTP Header:
Authorization: Basic <base64-encoded-credential> - 여기서 credential 은
USER:PASSWORD를 base64 로 단순 인코딩한 것(취약함) - 매 요청마다 자격증명을 함께 전송하는 구조
Bearer 인증
- HTTP Header:
Authorization: Bearer <token> - 토큰 기반 인증(JWT, OAuth Access token 등)
- 토큰에 만료 시간, 권한 정보들이 포함될 수 있음
- Bearer 란 무기명 채권(Bearer bond)에서 온 표현, 즉 토큰을 가지고 있는 사람에게 권리를 부여한다는 의미
Bearer 가 Basic 보다 안전하다고 할 수 있는 이유
- 비밀번호는 포함되지 않아, 탈취되어도 토큰만 무효화시키면 됨(블랙리스트 처리)
- 유효기간을 설정할 수 있음
- 토큰 별로 권한을 설정할 수 있음
기본적인 플로우
- 로그인을 통한 자격 증명(클라이언트 → 서버)
- 토큰 발급(서버 → 클라이언트)
- 향후 API 요청 시 토큰과 함께 요청(클라이언트 → 서버)
토큰 인증 방식
- JWT(JSON Web Token)
- 토큰을 세 부분으로 분리: header, payload, signature
- signature 검증(서버의 비밀 키와 비교)
- 만료 시간 및 클레임 검증(payload)
- Opaque Token
- 토큰을 DB, Cache 에서 조회
- 토큰 유효성 확인(존재 여부, 만료 시간)
- 연결된 사용자 정보 및 권한 조회
토큰 저장 방식
- web:
localStorage.setItem()orsessionStorage.setItem()을 주로 사용
보안상 고려사항
- HTTPS 사용하기
- 토큰 만료 시간 설정
- Refresh Token 별도 관리
- XSS, CSRF 공격 방어
[Dev] Redis 가 빠른 이유
- In-memory 데이터 저장소
- 모든 데이터를 RAM 에 저장하기 때문에 Disk 기반 데이터베이스보다 빠르게 동작할 수 있음
- 단순한 Key-Value 데이터 구조
- 스키마 없이 해시 테이블 key-value 구조로 되어 있음
- 대부분의 연산을 O(1) 로 처리할 수 있음
- 싱글 스레드 아키텍쳐
- 메인 이벤트 루프에서 싱글 스레드로 동작
- 덕분에 Lock 을 비롯한 동기화 오버해드, 컨텍스트 스위칭 비용이 없고, CPU 캐시 효율성이 높음
- 자원이 부족하면 멀티 프로세스로 처리함(클러스터링)
- 이벤트 기반 I/O
- epoll(linux), kqueue(BSD) 같은 고성는 I/O 멀티 플렉싱을 사용함
- 이를 통해 수천 개의 클라이언트 연결을 효율적으로 처리함
싱글 쓰레드 아키텍쳐
- 장점
- 동시성 문제 해결: lock, mutex 가 필요하지 않음. 모든 연산이 atomic 하게 처리되어 데이터 일관성이 높아짐
- 높은 CPU 효율: 컨텍스트 스위치 오버헤드가 없고 CPU 캐시 히트율이 높아짐
- 단순성: 멀티 쓰레드 개발보다 코드가 단순하고 디버깅 및 프로파일링이 쉬움
- 단점
- CPU의 멀티 코어 활용이 제한적 → Scale up 이 제한적
- 블로킹 문제: 하나의 무거운 연산이 전체 시스템을 블로킹할 수 있음
- 처리량 한계: 동시 연결이 매우 많은 경우 멀티 쓰레드보다 성능이 낮을 수 밖에 없음
- Redis의 대응
- 백그라운드 작업 분리: 스냅샷, AOF 재작성 등의 작업은 별도의 프로세스로 처리, 키 만료, 메모리 정리 등은 점진적으로 실행
- 클러스터링: 인스턴스 수평 확장 - 각 노드는 독립적이므로 이론적으로는 무한 확장 가능
- 비동기 I/O: 네트워크 IO는 이벤트 기반으로 비동기 처리
멀티 쓰레드 + 멀티 코어 CPU
- 멀티 쓰레드를 사용하면 복수의 CPU 코어에서 여러 개의 쓰레드를 병렬 처리할 수 있음
- 물론 쓰레드의 갯수 만큼 선형적으로 속도가 증가하지는 않음
- 오버헤드 요소: 쓰레드 생성 및 관리, 컨텍스트 스위칭, 메모리 대역폭 경합 등
- 동기화 비용: lock 대기, 메모리 베리어 오버헤드
- 파이썬에서는 GIL 때문에 멀티 쓰레딩이 제한적이다.
- CPU 집약적인 작업은 한 쓰레드가 처리 중이면 다른 쓰레드가 처리되지 못한다 → 오히려 더 느림
- IO 중일 때엔 다른 쓰레드의 작업이 처리될 수 있다 → 더 빠를 수 있음
- 따라서 다음과 같이 처리하는 것이 좋다
- Threading: IO 집약적 작업, 간단한 동시성 확보
- Multiprocessing: CPU 집약적 작업, 메모리 오버헤드를 감수하더라도 성능이 필요한 경우
- Asyncio: (비동기 단일 쓰레드 - 이벤트 루프) 많은 수의 IO 작업을 동시에 처리
현대 프로세스와 쓰레드의 역할
- 프로세스 = 컨테이너 역할
- 메모리 공간, 파일 디스크립터, 환경 변수, PID
- 프로세스는 실행되지 않는다, 단지 자원을 소유할 뿐이다.
- 쓰레드 = 실행 단위
- CPU 레지스터 상태, 스택 포인터, 프로그램 카운터, 실행 컨텍스트
- 실제 CPU 에서 실행되는 단위
- 운영체제 스케쥴러는 프로세스가 아니라 쓰레드를 단위로 하드웨어 코어에 매핑하는 역할을 수행한다. 즉 쓰레드가 스케쥴링의 기본 단위이다.
- 스케쥴링 알고리즘(Round Robin, CFS, Priority-based,etc)은 모두 쓰레드를 어떤 코어에 얼마나 할당할까를 결정하는 문제를 다룬다.
[Paper] A Survey on Large Language Model based Autonomous Agents
3 key aspects:
- Construction
- How to design the agent architecture to better leverage LLMs
- Hardware fundamentals
- unified agent framework
- How to inspire and enhance the agent capability to complete different tasks
- Software resources
- commonly-used strategies for agents’ capability acquisition
- How to design the agent architecture to better leverage LLMs
- Application
- Application of LLM-based autonomous agents in social science, natural science, and engineering
- Evaluation
- strategies for evaluating LLM-based autonomous agents
Contruction
Agent Architecture Design
- LLM 은 다양한 문제들을 QA(Question-Answering) form 으로 치환함으로써 해결해왔음
- 하지만 환경으로부터 자동으로 배우고 발전해나가지는 못함(gap between traditional LLM and autonomous agent)
- 이러한 gap 을 메우기 위해 다양한 시도들이 있어왔고, 여기서는 다음 네 가지 모듈로 나누어 살펴보려 함
- Autonomous Agent 를 구성하는 4가지 모듈
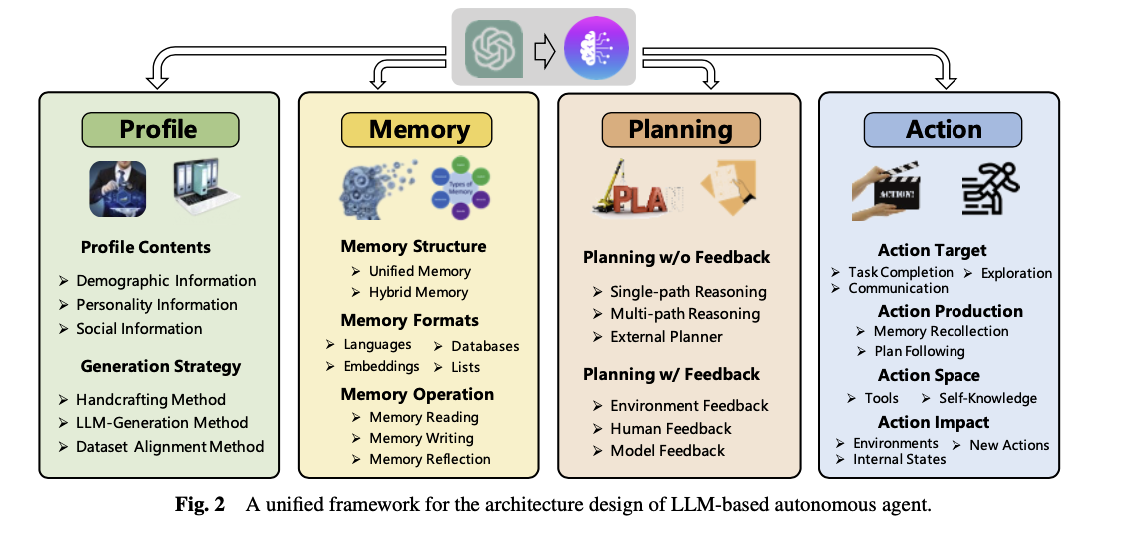
Profiling Module
- autonomous agent 는 특정한 role 의 profile 을 가지고 있고, 이에 따라 작업을 수행한다고 가정함
- Profiling 모듈은 이러한 profile 에 맞게 LLM이 행동하도록 만드는 데에 관심이 있음
- 이를 달성하는 데에는 크게 세 가지 방법이 있음
- 한 가지 방법만을 사용하는 것이 아니라, 다양한 방법을 함께 사용하는 것도 도움이 될 것으로 보임
Handcrafting Method
- 메뉴얼하게 프로파일을 작성하는 방법
- e.g."you are an outgoing person", "you are an introverted person”
- 쉽고 유연하게 적용할 수 있다는 장점이 있으나, 사람이 직접 해야한다는 점에서 많은 agent 에 적용하기에는 어려움이 있음
- Related Works
- Generative Agents
- MetaGPT
- ChatDev
- Self-collaboration
- PTLLM
- IPIP-NEO
- BFI
LLM Generation Method
- LLM 이 프로파일을 생성하도록 하는 방법
- Related Works
- RecAgent
- 사람의 손을 덜 탄다는 장점이 있지만, 에이전트 간의 세밀한 프로파일 제어가 어렵다는 것이 주요 단점
Dataset Alignment Method
- 데이터셋에 있는 특정 인물로 프로파일을 설정하면, 그에 대한 정보를 데이터셋에서 찾아와 프로파일로 사용하는 방법
- 실존하는 인물의 다양한 프로파일을 사용함으로써 더욱 현실적인 행동을 유도할 수 있음
Memory Module
- 외부 환경으로부터 얻은 정보들을 기록해두고, 미래 Action 을 결정하는 데에 활용하는 방법
Memory structure
- 사람은 감각적인 입력을 short-term memory 와 long-term memory 의 형태로 기억함
- LLM 연구 또한 이러한 방향으로 이뤄짐
- Short-Term Memory → input information within the context window
- Long-Term Memory → external vector storage
- Unified Memory
- Short-Term memory, 즉 prompt 만 사용하는 방법(in-context learning)
- Related Works
- RLP
- SayPlan
- CALYPSO
- DEPS
- 단순하고, 직관적이라는 장점이 있으나, 제한적인 context window 가 문제시 될 수 있다.
- Hybrid Memory
- Short-Term Memory 와 Long-Term Memory 를 함께 사용하는 방법
- Short-Term Memory 는 최근에 얻은 정보들을 다룸, Agent 가 현재 겪고 있는 상황에 대한 정보도 포함됨
- Long-Term Memory 는 중요하여 오랫동안 기억할만한 정보들을 다룸, Agent 의 과거 행동이나 생각들을 포함함. Agent 가 현재 처한 상황에 따라 검색하여 가져오게 됨
- Related Works
- AgentSims
- GITM
- Reflexion
- SCM
- SimplyRetrieve
- MemorySandbox
- Short-Term Memory 와 Long-Term Memory 를 함께 사용하는 방법
- Long-Term Memory 만 사용하는 경우는 거의 없음. Agent 가 현재 처해있는 상황에 대해 알 수 있는 Short-Term Memory 가 매우 중요하기 때문으로 보임.
Memory Format
- Application 의 특성에 맞게 적절한 Memory 구조를 사용하는 것이 중요함
- Natural Language
- 자연어 형태로 메모리를 관리하는 방법
- Related Works: Reflexion, Voyager
- Embeddings
- 인코딩한 vector 형태로 관리하는 방법
- 검색과 읽기에 있어 효율적일 수 있음
- Related Works: MemoryBank
- Databases
- 메모리를 Database 형태로 관리하는 방법
- Related Works: ChatDB
- Structured List
- 다양한 자료구조(tree) 형태로 관리하는 방법
- Related Works: GITM, RET-LLM
- 여러 방법을 복합적으로 사용하기도 한다.
- e.g. Key 는 Embedding, Value 는 자연어로 하는 방법
Memory Operations
- 메모리 모듈은 Reading, Writing, Reflection 의 세 가지 오퍼레이션을 수행함
- Memory Reading
- 에이전트의 액션을 향상시키기 위해 의미 있는 정보를 메모리로부터 추출해내는 것
- historic actions 들 중에서 가치있는 정보를 어떻게 추출할 것인가가 핵심
- commonly used criteria: Recency, Relevance, Importance → 아래 식의 score functions
- Memory Writing
- 환경으로부터 얻은 정보를 저장하는 것
- 유용한 정보를 잘 선별하여 저장하는 것은 효율성을 높이는 데에 중요하게 작용할 것
- 두 가지 문제
- [Memory Duplicated] How to store information that is similar to existing memories. 메모리 간의 중복을 어떻게 없앨 것인가
- [Memory Overflow] How to remove information when the memory reaches its storage limit. 메모리 오버플로우를 어떻게 해결할 것인가
- Related Works
- Augmented LLM
- ChatDB
- RET-LLM
- Memory Reflecting
- 주어진 메모리를 요약하고, 복잡한 정보들을 추론해내는 방법에 관한 것
- Related Works
- Generative Agent
- GITM
- ExpeL
Planning Module
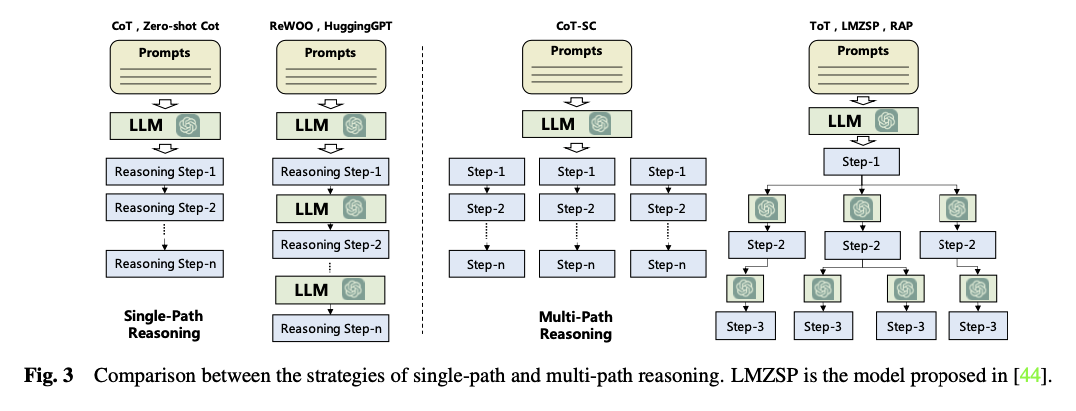
- 크고 복잡한 문제를 여러 개의 subtasks 로 쪼개어 해결하는 능력을 Agent 가 갖추도록 하는 방법
- Planning 에 있어 환경으로부터 받은 Feedback 을 사용하느냐, 그렇지 않느냐에 따라 나누어 볼 수 있음
Planning without Feedback
- 액션을 수행하여 얻은 피드백을 플래닝에 사용하지 않는 방법
- Reasoning Path 를 생성하는 과정에서 외부의 피드백을 사용하지 않는 것이 핵심
- Single-path Reasoning
- Reasoning Path 가 하나로만 구성되어 있어, 이후 step 이 하나로 고정되어 있는 방법
- LLM이 추론하는 횟수에 따라 구분할 수 있음
- 한 번의 LLM 추론으로 미리 계획된 추론 계획을 사슬처럼 생성해내는 방법(One-Shot manner): CoT, Zero-shot-CoT
- 미리 계획된 추론 계획에 따라 매 스텝마다 LLM 추론을 진행하는 방법: ReWOO, HuggingGPT
- Related Works
- CoT
- Zero-shot-CoT
- RePrompting
- ReWOO
- HuggingGPT
- SWIFTSTAGE
- Multi-path Reasoning
- Reasoning Path 를 tree 구조로 구성하는 방법, 매 Reasoning Step 은 복수의 후속 Reasoning Steps 를 가질 수 있음
- Next Reasoning Step 을 어떻게 생성하고, 각 Path 의 추론 결과를 어떻게 취합하여 최종 결과를 도출해낼 것인지가 핵심
- Related Works
- CoT-SC(Self-consistent CoT)
- ToT(Tree of Thoughts)
- RecMind
- GoT
- AoT
- External Planner
- 일반화 성능이 좋은 최신 LLM 의 경우에도 domain-specific 한 문제를 해결하는 것은 어려워함
- 특정 도메인에 특화되어 있으면서 외부 데이터에 접근 가능한 External Planner 가 플래닝하도록 하여 이러한 문제를 해결하는 방법
- Related Works
- LLM+P: 문제를 먼저 PDDL(Planning Domain Definition Languages) 로 변형 → External Planner 가 플래닝
- LLM-DP
- CO-LLM: LLM은 High-level planning 은 잘하지만 Low-level control 을 잘 못함 → 휴리스틱하게 해결
Planning with Feedback
- 환경으로부터 중간 중간에 받는 Feedback 을 Planning 에 적극 반영하는 방법, 사람도 외부의 피드백에 대응하여 계획을 바꿈
- 처음부터 완벽한 계획을 수립하는 것은 매우 어려움 + 계획의 실행 과정에서 전체 계획이 실행 불가능해질 수 있음
- Environmental Feedback
- 외부 환경의 피드백을 Reasoning Step 을 생성하는 데에 활용하는 방법
- Related Works
- ReAct: thought-act-observation triple 도입
- Voyager
- Ghost
- SayPlan
- DEPS
- LLM-Planner
- Inner Monologue
- Human Feedback
- 사람과의 interaction 을 플래닝에 활용하는 방법
- 사람의 주관적인 피드백이 포함되기 때문에 특정인의 가치와 선호에 따르는 결과에 도달할 수 있음
- 할루시네이션 문제를 해결하는 데에도 도움이 됨
- Related Works
- Inner Monologue
- Model Feedback
- Agent 의 자기 개선(self-refine) 매커니즘을 활용하는 방법
- Ouput-Feedback-Refinement 의 반복 수행
- Related Works
- SelfCheck
- InterAct
- ChatCoT
- Reflexion
- 외부 환경이나 인간의 피드백 없이 자체적으로 개선할 수 있는 가능성을 보여줌
Action Module
- 네 가지 관점에서 액션 모듈을 살펴볼 것
- Action goal: 액션의 의도된 결과물은 무엇인가
- Action production: 액션은 어떻게 생성되는가
- Action space: 선택 가능한 액션은 무엇인가
- Action impact: 액션의 결과는 무엇인가
- Action Goal
- 에이전트는 다양한 목표를 가지고 액션을 수행함. 가능한 목표로는 다음과 같은 것들이 있음
- Task Completion: 특정 작업을 달성하는 것을 목표로 하는 액션, 명확하게 정의된 목표가 있음
- Communication: 인간과 정보를 공유하고 협력하는 것을 목표로 하는 액션
- Environment Exploration: 익숙하지 않은 환경을 탐색하고 발견하는 것을 목표로 하는 액션
- Related Works
- ChatDev
- Inner Monologue
- Action Production
- LLM 과 달리 에이전트는 다양한 전략과 소스를 통해 액션을 취할 수 있음
- Action via Memory Recollection: 에이전트의 기억에서 정보를 추출하여 적절한 액션 생성
- Action via Plan Following: 미리 생성된 계획에 따라 액션 수행
- Related Works
- Generative Agents
- GITM
- ChatDev
- MetaGPT
- DEPS
- Action Space
- 선택 가능한 액션들의 종류
- External Tools
- 외부 도구를 활용하는 방법
- API, Database, External Models
- Related Works
- HuggingGPT
- WebGPT
- Gorilla
- ToolFormer
- ChatDB
- MRKL
- OpenAGI
- ViperGPT
- ChemCrow
- Internal Knowledge of the LLMs
- LLM 이 가지고 있는 지식을 적극적으로 활용하는 방법
- Planning Capacity, Conversation Capacity, Common Sense Understanding Capacity 등과 같은 LLM 의 능력을 활용함
- Related Works
- DEPS
- GITM
- Voyager
- ChatDev
- RLP
- Generative Agents
- RecAgent
- Action Impact
- 에이전트 행동의 결과로 발생할 수 있는 일들에 대해 정리
- Changing Environment, Altering Internal States, Triggering New Actions
LLM-based Autonomous Agent Application
TBD
LLM Agent Autonomous Agent Evaluation
- 평가하는 것 또한 어려운 문제임. 주관적인 방법과 객관적인 방법 두 가지로 나누어 볼 수 있음
Subjective Evaluation
- 사람의 판단을 기준으로 평가하는 방법
- 평가를 위한 데이터셋이 없거나, 양적인 평가 방법을 만들기 어려운 경우에 주로 사용
- Human Annotation
- 에이전트에 의해 만들어진 결과물을 사람이 직접 점수 또는 순위를 매기는 방법(scoring or ranking)
- Turing Text
- 동일한 task 에 대해 에이전트의 결과물과 사람의 결과물을 사람이 구별할 수 있는지 확인하는 방법
- 에이전트가 충분히 사람과 유사하게 동작하는지를 알아볼 수 있음
- 많은 에이전트들이 직접 사람을 대상으로 동작하는 것을 목표로 하는 만큼, 사람이 어떻게 느끼는지가 매우 중요함
- 하지만 높은 비용과 그로 인한 비효율성, 평가자의 대표성(population bias) 의 문제가 있음 → subjective method 의 구조는 그대로 사용하되, 사람이 아닌 다른 LLM 이 평가하도록 하는 방법도 있음
- Related Works
- ChemCrow
- ChatEval
- Related Works
Objective Evaluation
- 정량적인 메트릭을 사용하여 평가하는 방법
- Objective Evaluation 을 수행하는 데에는 세 가지 중요한 요소들이 있음
- Metrics
- 이상적인 평가 지표는 “에이전트의 품질(quality of the agents)”과 “실제로 가능한 상황에서(in real-world scenarios)” “사람이 느끼는 감정(align with the human feelings)”을 잘 수치화 할 수 있어야 함
- 세 가지 카테고리
- Task success: 주어진 테스크에 대한 달성 여부로 평가(e.g. success rate, reward/score, coverage, accuracy/error rate)
- Human similarity: 인간의 특성을 가지는지 여부로 평가(e.g. coherent, fluent, dialogue similarities, human acceptance rate)
- Efficiency: 얼마나 효율적으로 에이전트를 개발했는지 평가(e.g. cost associated with development, training efficiency)
- Protocol
- 자주 사용되는 Evaluation Protocol 로는 다음 네 가지가 대표적
- Real-world simulation: 시뮬레이션 속에서 에이전트가 자율적으로 테스크를 수행할 수 있는지 여부를 평가
- Social evaluation: simulated societies 와의 상호작용을 통해 사회적 지능을 평가
- Multi-task evaluation: 다양한 테스크 혹은 open-domain 환경에서 에이전트의 성능을 평가
- Software testing: test code, debugging code 등 코드를 작성하도록 하고, 그 결과를 평가
- 자주 사용되는 Evaluation Protocol 로는 다음 네 가지가 대표적
- Benchmarks
- 다양한 Benchmark 가 존재함
Challenges
- Role-playing Capability
- 에이전트가 롤 플레이를 해야하는 경우들이 있는데, 잘 하지 못하는 모습을 보임
- 학습할 때 웹에서 수집한 데이터를 주로 사용하였기 때문에 웹에서 등장 빈도가 낮은 역할에 대해서는 잘 하지 못함
- 인간의 인지 심리학적 특성을 잘 모델링하지 못하며, 특히 대화 시나리오에서 자기 인지 능력이 떨어짐
- Generalized Human Alignment
- 에이전트가 시뮬레이션의 목적으로 활용될 때 인간과 얼마나 유사하게 행동하느냐의 문제
- 지금까지의 LLM 들은 일반적인 인간 행동이 아닌 “올바른 인간 모습(correct human values)” 에 맞추어 행동하도록 학습됨
- 그러나, 현실 세계를 정확히 시뮬레이션 하기 위해서는 인간 행동의 부정적인 모습도 표현할 수 있어야 함
- 적절한 프롬프트 전략을 설계하여 이러한 모델들을 '재정렬(realign)'하는 방법을 찾아보자
- Prompt Robustness
- 프롬프트가 약간만 변화해도 에이전트 전체의 결과가 크게 바뀌기도 함
- 통일되고 탄력적인 프롬프트 프레임워크 개발이 필요 / LLM 을 통한 자동 생성도 고려해보아야
- Hallucination
- LLM 은 종종 false information 을 생성해냄
- Knowledge Boundary
- LLM 은 그 어떤 개인보다도 방대한 지식을 가지고 있음. 이는 어떤 테스크에 있어서는 장점이 되기도 하지만, 인간 행동을 모방하는 것과 같은 테스크에서는 문제가 될 수 있음
- LLM 이 사용자가 알지 못하는 지식을 활용하는 것을 어떻게 제한할 것인가
- Efficiency
- LLM 은 기본적으로 추론 속도가 느림
- 에이전트는 한 번의 추론에 다양한 Action 을 수행해야 하고, LLM 추론 또한 여러 번 이뤄질 수 있음
[Paper] VOYAGER: An Open-Ended Embodied Agent with Large Language Models
- 마인크래프트에서 사람의 개입 없이 세계를 탐색하고 다양한 스킬을 획득하며 스스로 발전하는 embodied lifelong learning aget 구현
- low-level motor command 대신 코드를 action space 로 설정함
- 시간적으로 확장되고 구성 가능한 행동을 자연스럽게 표현할 수 있음
- long-horizon task 가 많은 마인크래프트의 특성을 반영함
환경으로서 Minecraft
- 사전에 정의된 end goal 이나 정해진 스토리 라인이 없음
- 무한한 가능성을 가진 플레이그라운드를 가지고 있음
- 플레이어는 광활한 3D 지형을 탐색하고 자원을 확보하며 테크 트리를 해제해야 함
- lifelong agent 가 마인 크래프트를 잘 해결하기 위해서는 사람이 학습하는 것과 유사한 과정을 거치도록 하는 것이 좋음
- 현재의 스킬 레벨과 환경 상태에 기초해 적절한 작업을 제안함
- 피드백에 따라 스킬을 정보를 정제하고, 기억하여 미래에 비슷한 상황에서 사용할 수 있게 함
- 자기 능동적으로 세계를 지속적으로 탐색하고 새로운 작업을 찾아냄
세 가지 주요 컴포넌트
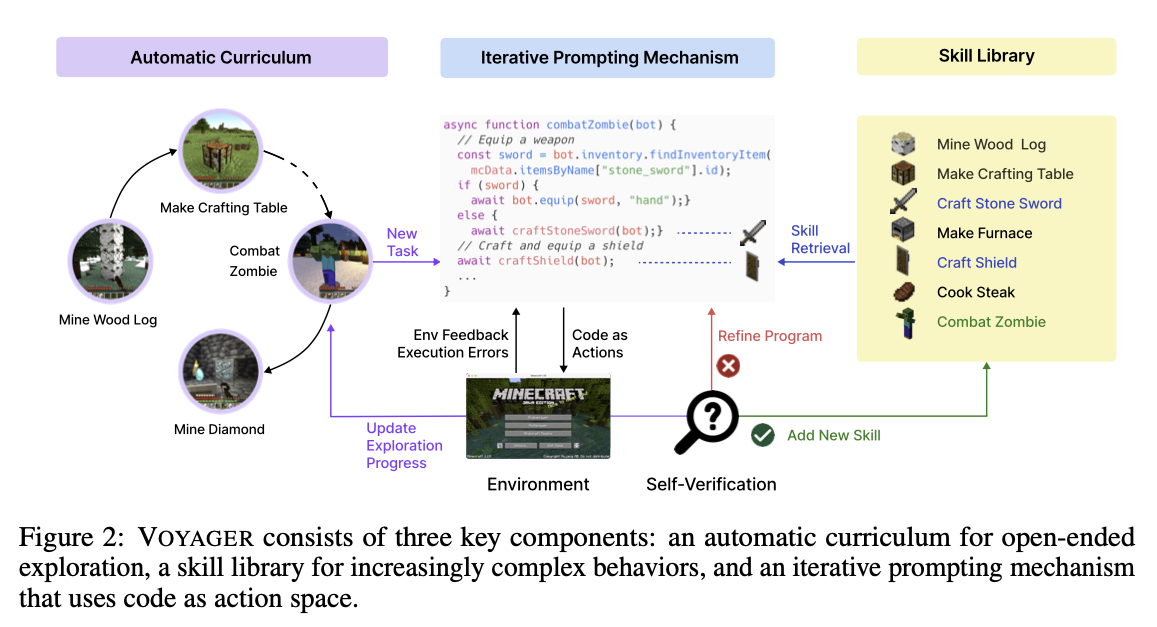
Automatic Curriculum
- 다양한 작업들을 시도해 볼 수 있도록 유도하는 프롬프트를 함께 입력으로 주어 GPT-4 가 다음 Task 를 정하도록 함
- “… My ultimate goal is to discover as many diverse things as possible, accomplish as many diverse tasks as possible and become the best Minecraft player in the world. …”
- Novelty Search 에서 영감을 받음
- 이외에 프롬프트에는 에이전트의 현재 상태, 과거에 완료했거나 실패했던 작업들, CoT 프롬프트 등이 포함됨
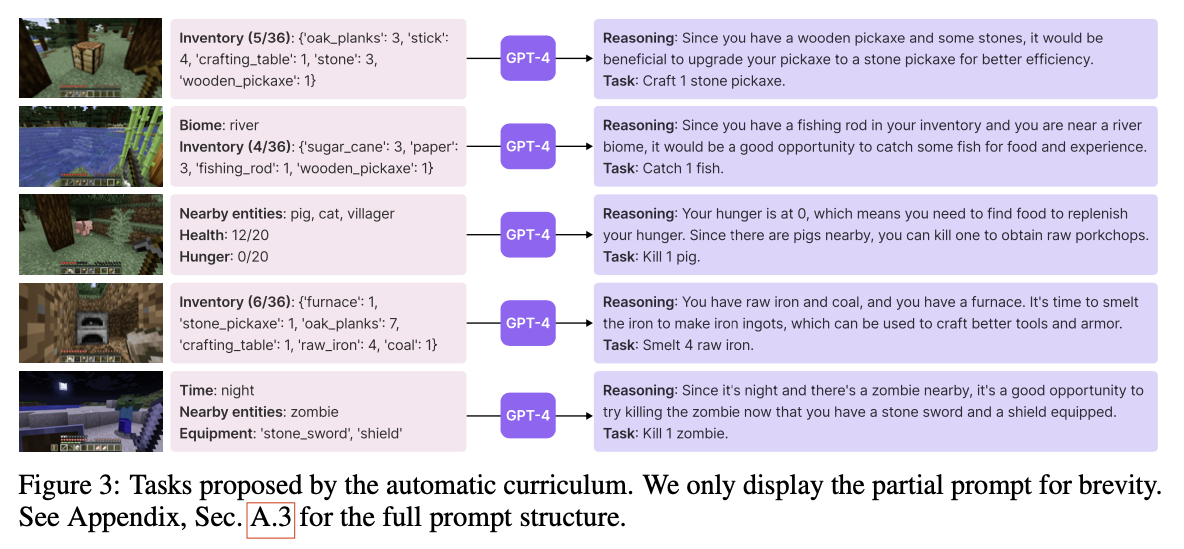
- 이를 통해 단순한 테스크에서 시작하여 점점 복잡한 테스크를 제안할 수 있게 됨
Skill Library
복잡한 행동을 저장하고 검색하기 위한, 끊임없이 성장하는 실행 가능한 코드 기술 라이브러리
Description 을 임베딩화하고 유사한 상황에서 검색할 수 있도록 함
복잡한 기술은 더욱 간단한 프로그램의 조합으로 합성함 - 이는 catestrophic forgetting 완화에 도움
Adding a new skill
- GPT-4 가 task 를 수행하는 데에 필요한 코드 생성
- GPT-3.5 가 생성된 코드에 대한 설명과 그 임베딩을 생성함
- 임베딩을 키로, 코드를 밸류로 하여 스킬 라이브러리에 새 값 추가
Skill retrieval
- Automatic curriculum 가 task 를 생성함
- task 를 GPT-3.5 에 입력으로 주고, 이를 달성하기 위한 일반적인 제안들을 생성함
- 제안들과 현재 환경 정보를 결합하여 query context 를 생성함
- query context 로 skill library 에서 검색
- 유사도가 가장 높은 5개의 테스크를 뽑아냄
Iterative Prompt Mechanism
- 환경 피드백, 실행 오류, 자가 검증을 통합하는 새로운 반복 프롬프트 매커니즘
- 환경 피드백: 환경으로부터 예상되는 피드백, 특정 테스크를 현재 수행하지 못하는 이유 등에 대한 설명
- 실행 오류: 잘못된 명령어, 문법 오류 등을 포함해 코드를 실제 실행하며 발생하는 에러에 관한 내용
- 자가 검증: GPT-4를 사용한 자가 검증, 현재 상태와 테스크를 주고 코드와 같이 행동하는 경우 잘 문제 없이 동작할 지 검증하는 것
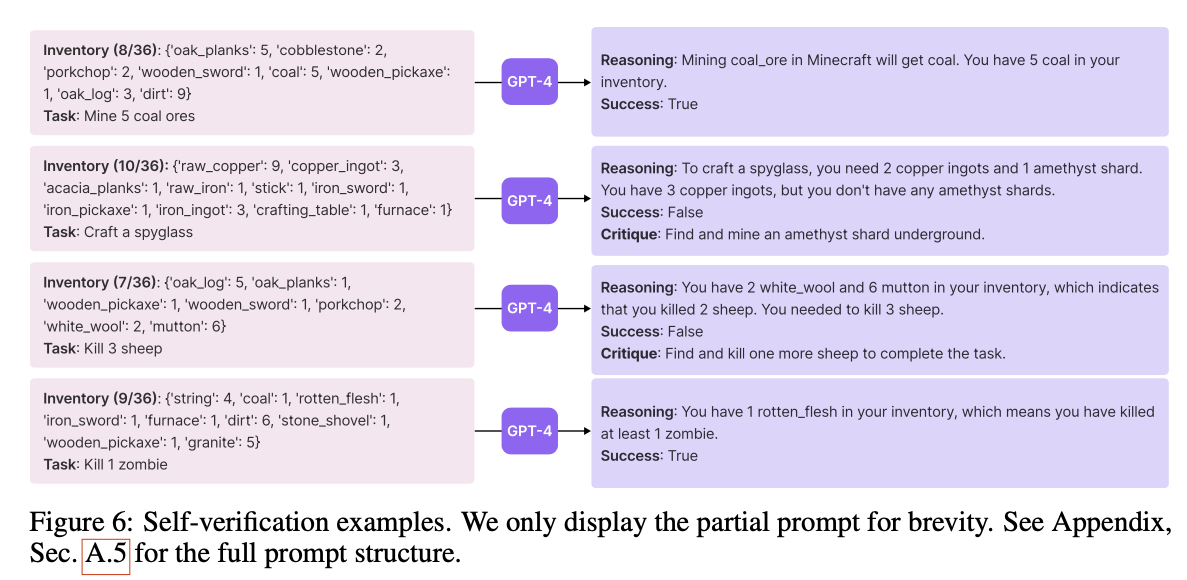
- LLM은 한 번에 올바른 행동 코드를 일관되게 생성하는 데 어려움을 겪음 → 반복적인 프롬프트 매커니즘으로 해결 (이 문제가 무엇인지 좀 더 확인 필요)
- 반복적인 프롬프트 매커니즘이란,
- 생성된 프로그램을 실행하고, 마인크래프트 시뮬레이션을 관찰하여 오류 추적
- 피드백을 GPT-4의 프롬프트에 통합, 코드 개선 작업 수행
- 자가 검증 모듈이 작업을 완료할 때까지 반복 수행
- 반복 수행하여 검증이 완료된 후에야 skill library 에 새로운 skill 로 추가됨
Experiments
경험적으로 , VOYAGER 는 강력한 in-context lifelong learning 성능을 보여줌
- 비교 대상 모델: ReAct, Reflexion, AutoGPT
Multimodal Feedback from Humans
- visual perception 을 사용하지 않음
fine-tuning 없이 GPT-4, GPT-3.5 API 를 사용하여 해결함
[Paper] ROCKET-1: Mastering Open-World Interaction with Visual-Temporal Context Prompting
- 마인크래프트에서 VLA 를 사용하여 다양한 테스크를 수행하는 방법에 관해 다룸
Main contributions
- Visual temporal context prompting: hierarchical agent 에서 high-level reasoner 가 low-level policy 에 정보를 전달하는 새로운 communication protocol 제시
- ROCKET-1: segmentation 정보를 활용하는 policy 학습
- Backward trajectory relabeling: 수집된 trajectory 에서 대상 물체를 연속적으로 인식하도록 하여 segmentation 정보를 포함하는 데이터셋 수집
Existing approaches for embodied decision making in open-world environment
- 크게 end-to-end 와 hierarchical 로 나누어 볼 수 있음
End-to-end Approach
- VLA가 환경의 observation 과 text instruction 을 입력받아 Action 을 직접 결정하는 방법
- 학습하기 위해서는 annotated trajectory data 대량으로 필요함 - 수집이 어려움
- RT-2, Octo, LEO, OpenVLA
Hierarchical Approach
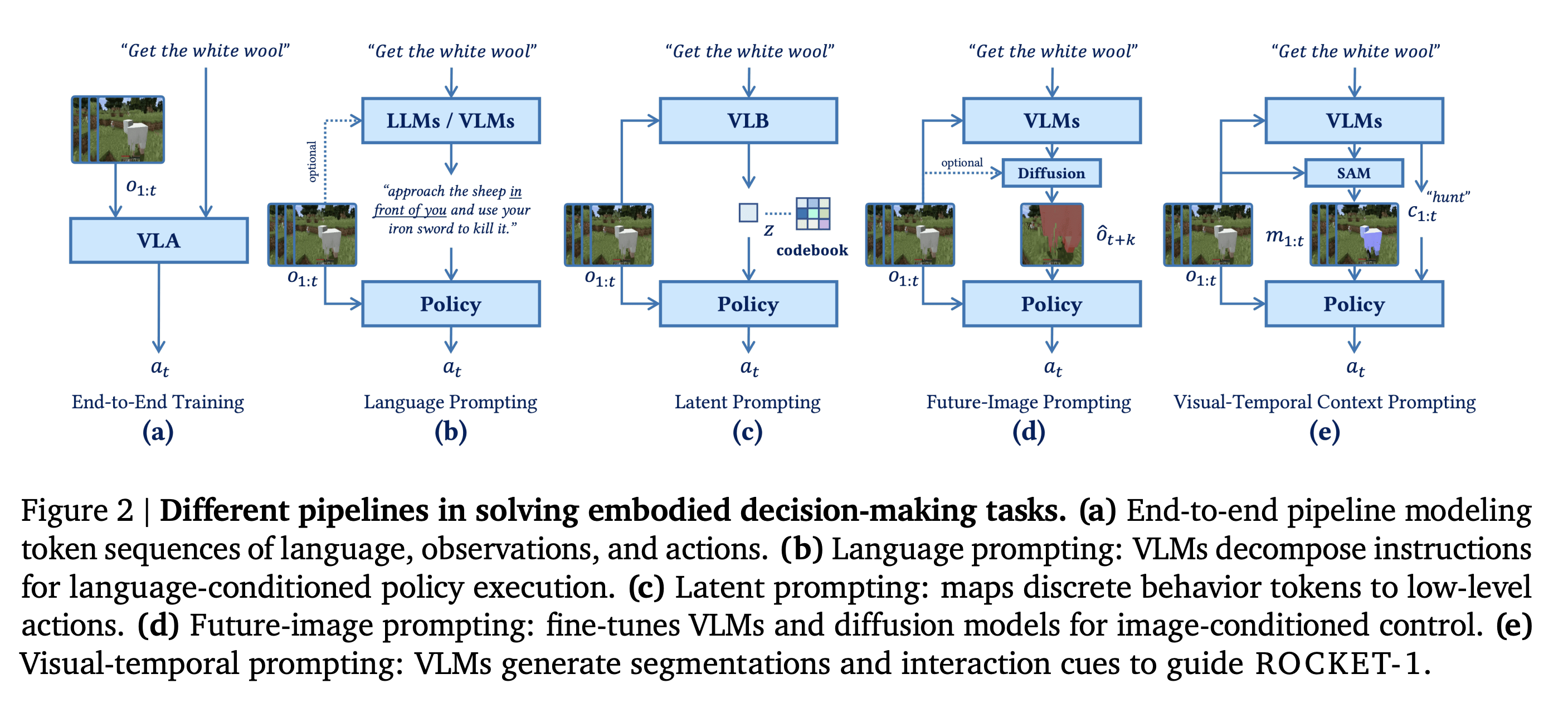
- high-level reasoner 와 low-level policy 가 분리되어 있고, 계층적으로 동작하도록 하는 방법
- 두 컴포넌트들은 서로 독립적으로 학습될 수 있음
- 두 컴포넌트 간의 communication protocol 을 어떻게 설정하느냐에 따라 모델의 능력이 달라짐
- Communication protocol 에 따른 Hierarchical Approach 의 분류
- Language Prompting
- High-level reasoner 가 Low-level policy 에게 language-based sub-tasks 로 전달하는 방식
- spacial information 을 다루는 데에 한계가 있음
- Latent Prompting
- High-level reasoner 가 Low-level policy 에게 discrete 한 behavior token 으로 인코딩하여 전달하는 방식
- Future-Image Prompting
- High-level reasoner 가 Low-level policy 에게 vision-based interface 로 정보를 전달하는 방식 중 하나로, instruction 이 수행되었을 때 보여기는 시각 정보의 형태를 Diffusion 모델로 생성하여 전달하게 됨
- 텍스트 만으로는 공간 정보를 다루기 어려워한다는 문제를 극복하기 위함
- future observation 을 생성하는 것 자체가 world 에 대한 강력한 이해를 필요로 하기 때문에 어려움
- Visual-Temporal Context Prompting
- 논문에서 제안하는 communication protocol. 논문에서는 최근에 수집한 일련의 visual observations 과 객체 인식에 따른 하이라이트를 활용함
- 여기서 temporal 은 시간적 연속성을 보여주는 과거 정보들을 의미함
- 어떤 작업을 수행할 때, 사람은 그 테스크를 수행하는 상황을 상상하지 않음. 그것보다는 대상 객체 또는 달성하기 위해 필요한 과거 기억에 집중함
- 논문에서 제안하는 communication protocol. 논문에서는 최근에 수집한 일련의 visual observations 과 객체 인식에 따른 하이라이트를 활용함
- Language Prompting
ROCKET-1 Model Architecture
- 논문에서 제안하는 Low-level Policy Architecture
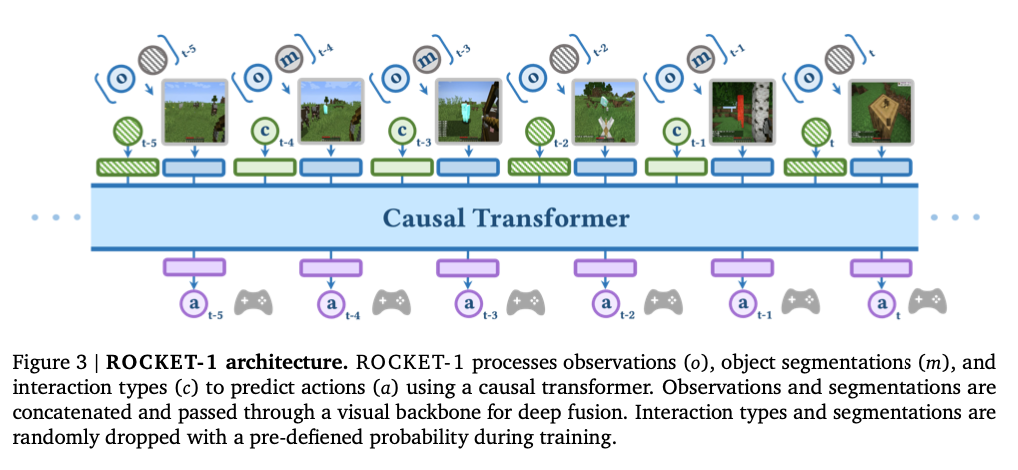
- Observation 와 highlight segmentation 정보를 담고 있는 을 concat 하여 Backbone 과 AttentionPooling layer 를 차례대로 통과시킴. 이렇게 확보한 는 action 을 결정하는 데에 필요한 시각 정보들을 담고 있음
- 는 interaction type 정보인 와 함께 Transformer 모델의 입력으로 전달되어 Action 를 결정하는 데에 사용됨
- interaction type 를 이미지 정보를 추출할 때에는 사용하지 않고, 이후 이미지 인코딩이 완료된 후에 같이 Transformer 에 전달하도록 하고 있음
- 이는 interaction type 의 imbalance 문제가 이미지 추출에 영향을 주지 않도록 하기 위함임
Notation:
- Policy:
- Trajectory:
- Observation:
- Segmentation:
를 생성하는 데에 와 가 과도하게 영향을 줄 가능성을 배제하기 위해 를 도입하여, 확률적으로 몇몇 시점에는 과 없이 Observation 만 가지고 action 을 결정하도록 함
Backward Trajectory Relabeling
- 관심 대상의 segmentation 정보가 포함된 Trajectory 데이터셋을 만드는 방법
- 다음과 같은 순서로 진행
- 에이전트와 대상 간의 상호작용이 발생하는 프레임 식별
- Open-Vocabulary Grounding 모델(Molmo)로 상호작용 대상이 되는 객체의 위치를 식별함
- SAM-2 를 활용하여 상호작용 프레임 뿐만 아니라 과거 시점의 프레임에서도 동일한 객체를 식별하고, 이들의 segmentation map 을 생성함
- OpenAI 의 contractor data 의 1.6billion 프레임을 이와 같은 방식으로 relabeling 함 - OpenAI VPT
Overall Architecture
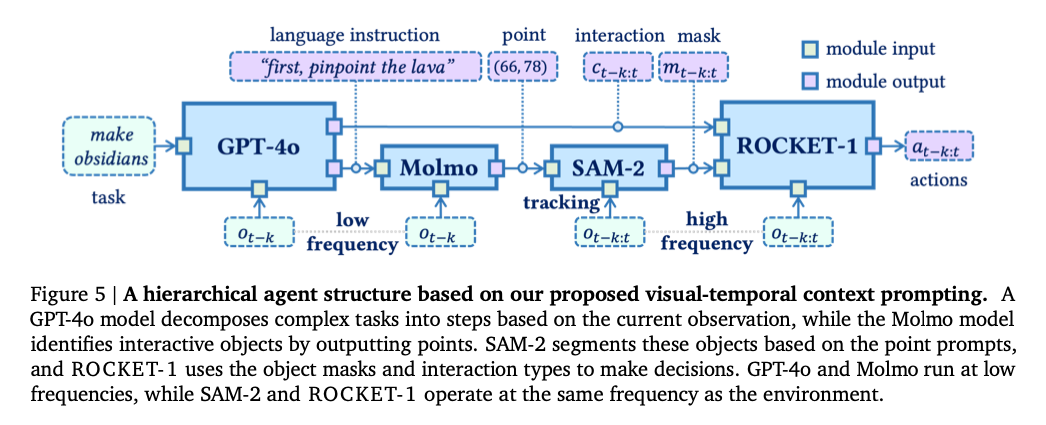
- High-level reasoner: GPT-4o
- Open-Vocabulary Grounding(coordination): Molmo
- Segmentation + Tracking: SAM-2
- Low-level policy: ROCKET-1
Experiments
- 6개의 카테고리 12개의 테스크로 구성된 Minecraft benchmark 제안
- Baseline Models: VPT, STEVE, GROOT
- ROCKET-1 Masters Minecraft Interactions
- ROCKET-1 Supports Long-Horizon Tasks
Minecraft 를 환경으로 선택한 이유
- 복잡한 테스크와 자유로운 탐색이 가능한 개방형 환경
- 모델의 적응력과 long-term planning 능력을 확인하기에 좋음
- real-world 에 적용하기 전 사용할 만한 테스트베드
[Paper] JARVIS-VLA: Post-Training Large-Scale Vision Language Models to Play Visual Games with Keyboards and Mouse
Contributions
- Minecraft 와 같은 Open World 에서 동작할 수 있는 JARVIS-VLA 모델 제안
- Vision Language Post-Training(ActVLP) 제안
- Scaling laws of VLA model 확인
JARVIS-VLA Model Architecture
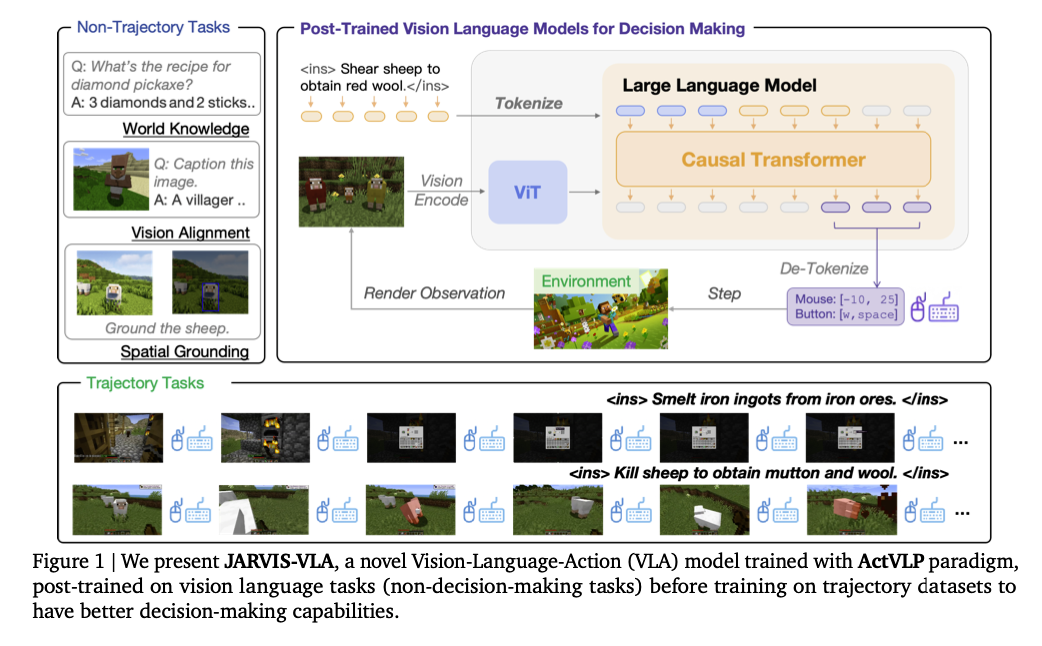
- LLaVA 와 유사한 구조
- Vision Transformer
- Image Projection Module
- Language Model Transformers
- OpenVLA 와 달리, partially observable 한 환경을 가정함
- partially observable: 현재 시점의 시야 만으로는 환경 전체의 상태를 파악할 수 없음 → Markov property 를 만족하지 못하는 상태를 말함
- JARVIS-VLA의 Non-Markovian architecture: 현재 관찰 뿐만 아니라 과거 관찰까지 고려하여 의사결정을 내림 - 여러 시점의 이미지를 함께 모델에 제공하는 방식으로 구현.
- 다중 이미지 추론에 강력한 성능을 보이는 VLM 모델 사용: Llava-Next, Qwen-2-VL
- Continuous Action Space 와 Discrete Action Space 모두에 대응할 수 있는 Action Decoder 도입
- discrete: 관련성이 높은 Action 들을 하나의 범주로 만들고, 각 범주를 토큰화함
- continuous: action space 를 bin 으로 쪼개어 토큰화함
- 가장 사용 빈도가 낮은 51개의 토큰을 Action 토큰으로 대체하는 방식 사용(VLA 의 가장 기본적인 방식)
- 22 토큰 → 마우스 컨트롤에 사용, VPT 에서 사용한 방식 적용 - Video PreTraining (VPT)
- 29 토큰 → 키보드 입력에 사용
Training Pipeline
- 전통적인 VLA 적용 방법: VLM 를 large-scale trajectory data 로 파인튜닝(imitation-learning)
- 이 방법은 internet-scale 데이터로 학습된 VLM 이 강력한 일반화 성능과 이해력을 가지고 있다는 것을 가정함
- 하지만, action-labeled trajectory 만으로 world 에 대해 충분히 이해하는 것은 어려움 (ref. VPT)
- trajectory data 를 충분히 수집하는 것도 어려움
- ActVLP
- 이러한 문제를 극복하기 위해 3 stage 로 구성된 structured post-training process 도입

- Stage 1: Post-Training Language Model
- Downstream env 에 대한 VLM 의 언어 모델의 이해를 높이는 단계
- ViT, Vision adaptor 모듈은 Frozen
- Objective Function: Next Token prediction
- Stage 2: Post-Training Vision Encoder and Language Models
- Vision Encoder 와 Language Model 을 VQA(visual question-answering)와 Spatial grounding dataset 으로 추가 학습
- Frozen 되는 모듈 없이 모든 모듈이 업데이트됨
- Objective Function: Next Token prediction task (1과 동일)
- Stage3: Imitation Learning on Trajectories
- expert action 을 mimic 하는 trajectory data 로 학습
- vision과 관련된 모듈은 frozen. language model 만 action token 을 적절히 생성해낼 수 있도록 파인튜닝(full-parameter fine-tuning)
- action chuck 를 생성하도록 하고 있음 - Diffusion Policy
- 쉽게 말해 Imitation learning 만 하면 성능이 좋지 않으니, action 을 결정할 world 에 대한 지식을 먼저 습득시킨 후에 action 을 결정할 수 있도록 training 하겠다는 것
- 세 가지 단계에 쓸 데이터를 각각 생성함: trajectory dataset 과 함께 non-trajectory task dataset(knowledge-based question answering, vision language alignment, spatial grounding)
- spatial grounding: 시각 정보 내에서 객체의 정확한 위치와 그 맥락을 이해하는 능력