- Published on
This Week I learned 2
Summary
1. [Paper] Rt-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
- 이미지와 텍스트를 입력으로 받아, Transformer 로 처리하여 Robotics Action 을 결정하도록 하는 방법
- EfficientNet 으로 이미지 임베딩으로 추출하는 단계에서부터 FiLM 을 적용, 텍스트의 의미를 고려한 추출이 이뤄지도록 함
- 연속적인 Robitics Action 공간을 256 개의 bin 으로 쪼개어 tokenize 하는 방법 제안
2. [Paper] Rt-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 강력한 일반화 성능을 보이는 VLM 을 적용하여 Robot의 Action 을 결정하는, VLA 방법론 제안
- Low-level control, 즉 robot 이 취해야하는 실제 Action 을 결정하는 모델
- 파인튜닝 시 Co-Fine-Tuning, 즉 새로 수집한 Robot Action 데이터만 사용하는 것보다 VLM 모델을 프리 트레이닝 할 때 사용한 데이터를 함께 섞어서 하는 것이 더욱 잘 됨
3. [Docs] Building Effective Agents
- Workflow 와 Agent 의 구분:
- Workflows: 사전에 정의된 순서대로 LLM과 tool이 실행되는 시스템
- Agents: LLM 이 task 를 수행하기 위해 동적으로 tool 을 사용하는 시스템
- 문제의 복잡성과 비용 간의 트레이드 오프: Agent 는 보통 비싸고 느리다. 따라서 필요할 때만 쓰는 것이 좋다
4. [Paper] LLaVA: Visual Instruction Tuning
- Large Multimodal Model 제안
- Image embedding 을 2개의 Fully Connected 로 구성된 Projection Layer 를 사용하여 Word Embedding Space 로 사영
- Image + Text 의 환경에서 사용할 수 있는 Instruction Tuning Dataset 확보
[Paper] Rt-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE
Objective
- 다양한 로봇 데이터를 흡수할 수 있는 고용량 아키텍처와 Open-Ended Task-Agnostic Training 방법
Task-Agnostic: 학습 방법에 관한 것. 특정 테스크에 얽매이지 않고 다양한 테스크에 대해 학습시키겠다.Open-Ended: 모델의 능력에 관한 것. 새로운 작업에 대해서도 유연하게 대처할 수 있게 하겠다.High capacity Architecture: 다양하고 대규모의 로봇 데이터를 처리할 수 있는 모델 구조를 사용하겠다(Transformer).- 정리하면 다음 두 가지 목적:
- 다양한 종류의 로봇 작업으로 구성된 데이터로 단일의 다규모 다중 작업 백본 모델(single, capable, large multi-task backbone model)을 학습시키는 것
- 모델의 일반화 성능, 제로샷 성능을 확인해보는 것
2 Difficulties
- 데이터셋의 확보와 큐레이션
- 일반화 성능을 확보하는 것이 목표이므로, 그에 맞는 데이터셋 구성 필요
- 다양한 셋팅과 테스크를 포함하는 데이터(scale and breadth) + 테스크 간에 구조적으로 유사한 패턴을 발견할 수 있도록 작업 간에 연결성 필요
- Real-Time Inference
- high-capacity 를 가진 모델 구조로는 Transformer 가 좋아 보이나, 이를 real-time 추론을 요구하는 로보틱스에 적용하는 것은 도전적임
- 로봇 필드에서 사용할 수 있도록 하기 위해서는 Feasible 한 모델 구조에 대한 연구 필요
Data Collection
- Everyday robots 사의 mobile manipulators 를 사용함
- 7자유도(degree-of-freedom, DoF) 팔(x, y, z position, roll, pitch, yaw rotation, opening of the gripper), 두 개의 손가락으로 된 그리퍼, 그리고 이동 가능한 베이스
- roll: 팔뚝을 축으로 회전하는 움직임
- pitch: 팔꿈치를 굽히고 펴는 움직임과 유사하게, 상하로 회전하는 움직임
- yaw: 팔꿈치를 중심으로 좌우로 회전하는 움직임과 유사하게 수평면에서 회전하는 움직임
- 7자유도(degree-of-freedom, DoF) 팔(x, y, z position, roll, pitch, yaw rotation, opening of the gripper), 두 개의 손가락으로 된 그리퍼, 그리고 이동 가능한 베이스
- 3 kitchen-based environment 에서 데이터를 수집함
- real kitchen 을 본떠 만든 training environment 에서 훈련용 데이터 수집
- 2 real office kitchen 을 평가에 사용함
- 학습 환경과 평가 환경 간에는 조명, 배경, 전체 주방의 구조 등에서 차이가 있을 수 있음 → 일반화 성능 검증에 활용
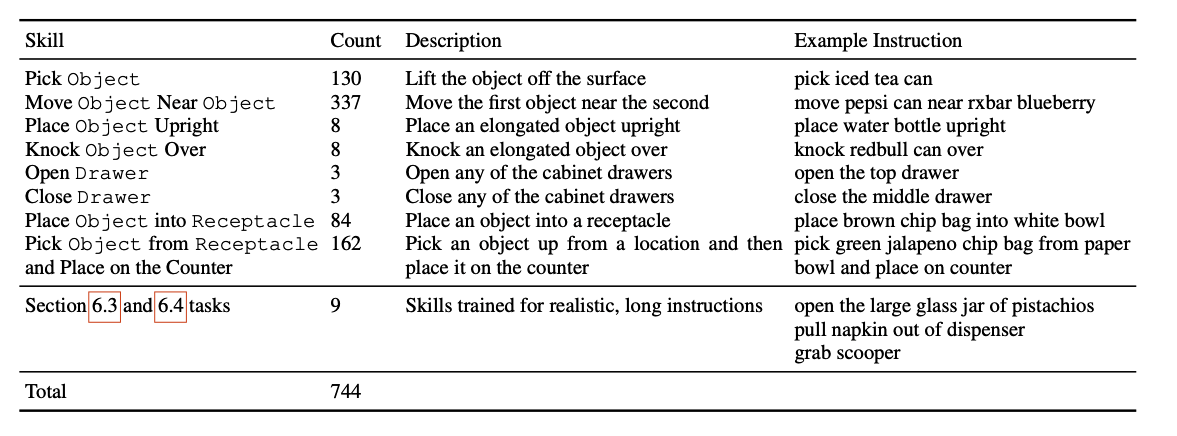
- Annotation
- 각 Episode 별로 동사와 한 개 이상의 명사를 포함하는 텍스트 설명 추가
- 130k 개의 개별적인 시연을 포함하여 700개 이상의 고유한 작업 지침 확보
Model Architecture
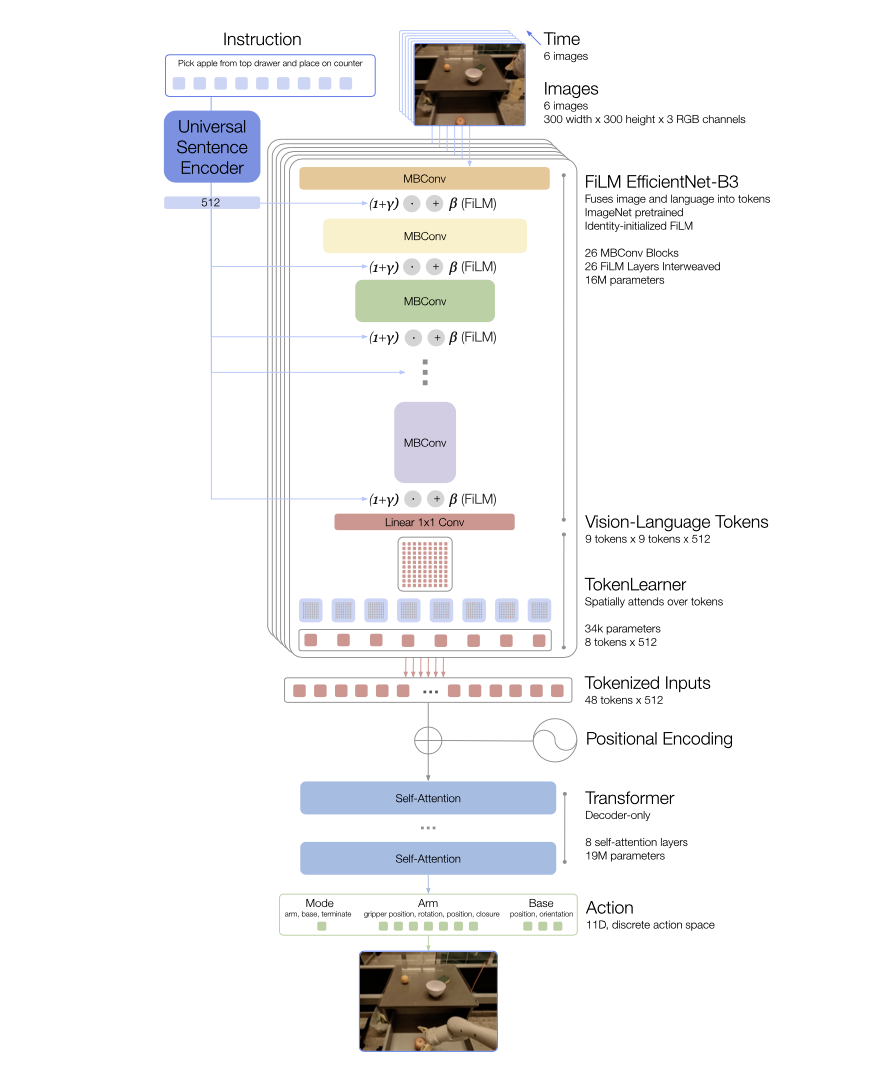
- Text Token
- Universal Sentence Encoder (USE) 를 사용하여 텍스트를 인코딩
- Image Tokenization
- 6 개의 historic image 를 입력으로 받음
- 각 이미지는 EfficientNet-3B 로 feature extraction 함: 300x300 → 9x9x512
- EfficientNet 레이어 사이사이에 추가된 FiLM Layer 에서 Text Token 과 조건부로 결합(early fusion)
- 이미지에서 특징을 추출할 때부터 텍스트의 입력을 조건화하여, 작업과 관련된 이미지 특징이 더욱 잘 추출될 수 있도록 함
- FiLM Layer 가 중간에 추가되기 때문에, EfficientNet 의 Pretrained parameter 는 잘 동작하지 않게 됨
- 이러한 문제를 해결하기 위해 FiLM affine transformation 을 생성하는 dense layer 의 가중치를 0으로 초기화함(identity 초기화)
- 다른 트렌스포머 모델에서는 이미지를 패치로 나누고 토큰화하는 방법을 사용하나, 여기서는 flatten 하여 입력으로 전달
- 이미지 당 총 81 개의 토큰 생성
- TokenLearner
- 생성된 81 개의 토큰을 8개로 압축
- 다수의 토큰을 훨씬 더 적은 수의 토큰으로 매핑해주는 element-wise attention module
- soft-select 하여 중요한 토큰만을 남기는 것
- 생성된 81 개의 토큰을 8개로 압축
- Transformer Layer
- 각 이미지 별로 8개의 토큰이 전달되어 총 48개의 토큰이 트렌스포머 레이어로 전달됨
- 8개의 self attention layers
- Action tokenization
- 연속적인 action 공간을 256개의 bin 으로 쪼개어 tokenizing 함
[Paper] Rt-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Objective
- 웹의 대규모 vision language data 로 pretraining 된 모델(VLM)의 이점을 살려 로봇의 observation 을 Action 으로 매핑하는 방법을 학습하는 것
- 특히 High-level planning 에 대해서는 VLM 을 활용하는 연구가 있어 왔지만, Low-level 에서는 부족했다. Low-level 에서도 시도해보자.
- 논문의 주된 질문: large pretrained vision-language models 를 저수준 로봇 제어에 직접 통합하여 일반화를 촉진하고 새로운 의미론적 추론을 가능하게 만들 수 있는가?
Advantage of using VLM
- 정확히는 High-capacity models pretrained on broad web-scale datasets 의 장점으로, 강력한 추론능력과 더불어 높은 일반화 성능을이 필요하기 때문임
- VLM은 Open Vocabulary Visual Recognition 뿐만 아니라 이미지 내 객체와 에이전트 간의 상호작용에 관한 복잡한 추론도 수행할 수 있음
- 이러한 의미론적 추론, 문제 해결 능력, 시각적 해석 능력은 real-world 환경에서 다양한 작업을 수행해야하는 로봇에게 유용할 것
- 로봇을 통해 직접 상호작용하여 데이터를 수집하는 것은 쉽지 않기 때문에 이러한 모델들을 사용하는 것이 더욱 중요함
High-level Planning vs Low-Level Actions
- High-level Planning
- 의미론적 추론, 문제 해결, 시각적 해석과 관련
- 명령을 해석하고 이를 개별 동작으로 만드는 역할
- e.g. "딸기를 올바른 그릇에 넣어라” 와 같은 명령을 해석하는 능력
- Low-Level Actions
- 기본적이고 직접적인 로봇의 물리적인 움직임(e.g. Cartesian end-effector commands)
- e.g. 6-자유도(DoF) 위치 및 회전 변위, 그리퍼 확장 수준
- 지금까지의 연구들은 모두 High-level 수준의 플래닝에만 사용하고, 저수준의 작업들은 여전히 low-level controller 가 수행하는 방향으로 주로 이뤄짐
Robot Control: Closed-loop vs Open-loop
- 로봇 컨트롤과 관련된 두 가지 모드
- Closed-Loop Control: 로봇의 상태를 지속적으로 모니터링하고, 이를 바탕으로 로봇의 출력을 제어하는 방법
- Open-Loop Control: 로봇의 상태를 확인하지 않고, 발행된 명령을 계속 수행하는 방법
Model Architecture
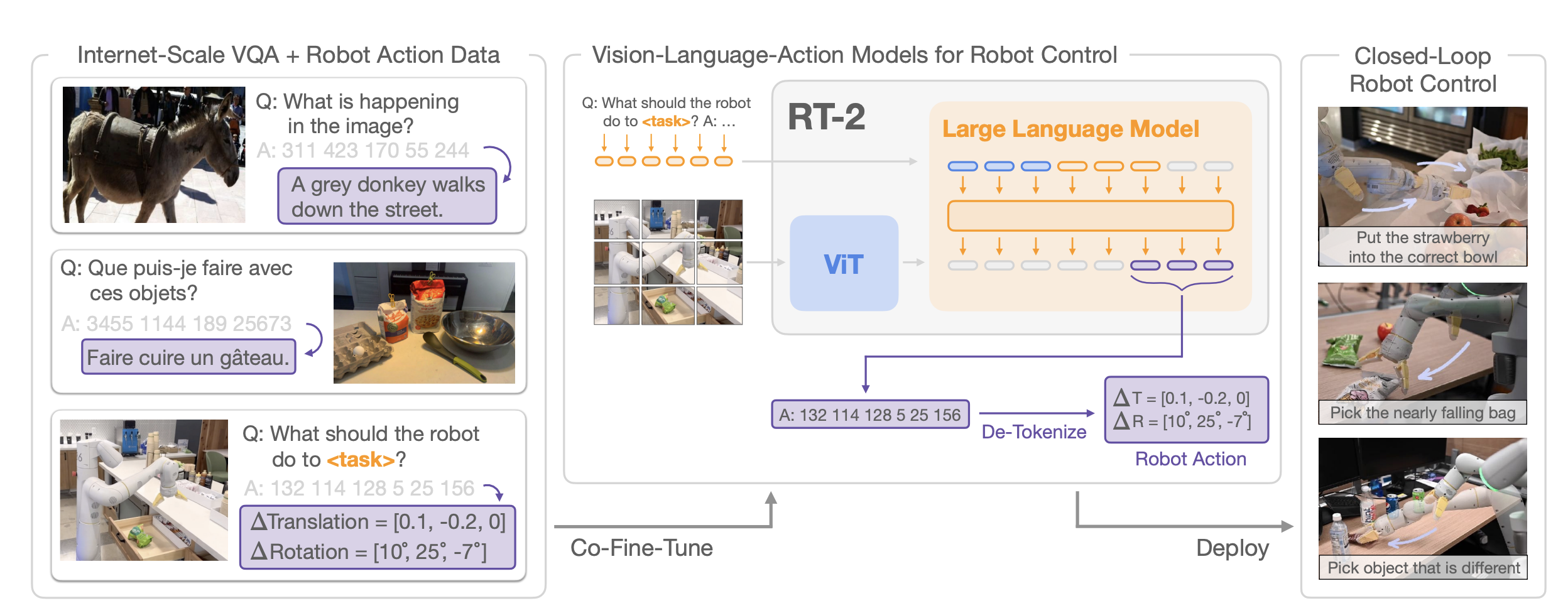
- Pre-Trained Vision-Language Models
- VLM 은 하나 이상의 이미지를 입력으로 받아들이고, 자연어 텍스트를 나타내는 토큰 시퀀스를 생성함
- 논문에서는 다음 두 가지 모델을 사용함: PaLI-X, PaLM-E
Model Training
- Robot-Action Fine-Tuning
- VLM 이 로봇을 직접 제어할 수 있도록 하려면 Action 을 출력해야 함
- RT-1 에서 제안한 이산화(discretization) 방법을 사용함
- 연속적인 차원을 256개의 균일한 bin 으로 이산화함 ⇒ 로봇 행동을 정수 숫자로 표현 가능함
- 이러한 이산화된 토큰을 생성하기 위해서는 모델에서 사용되고 있던 256 개의 토큰을 Action 토큰으로 할당해야 함
- Symbol Tuning 의 한 형태
- PaLI-X: 1000 까지의 정수가 고유의 토큰을 이미 가지고 있음 → 연결
- PaLM-E: 가장 적게 사용되는 256 개의 토큰을 Action 토큰으로 덮어씀
- 입력: 카메라 이미지 + 텍스트 작업 설명
- 출력: 로봇의 Action 을 나타내는 숫자/최소 사용 토큰 문자열 → de-tokenize 를 하면 robot action 이 됨
- Output detail
- 입력 텍스트: VQA 형식에 기반함
- "Q: what action should the robot take to [task instruction]? A:"
- 출력: 8개의 토큰 -
- 로봇 동작 공간의 구성 때문에 8개임
- 6-DoF 위치 및 회전 변위: 로봇 말단 장치(end-effector)의 3축 위치(Δpos𝑥, Δpos𝑦, Δpos𝑧)와 3축 회전(Δrot𝑥, Δrot𝑦, Δrot𝑧)을 나타냄, 연속적인 값이므로 256개의 빈으로 쪼개어 나타냄
- 그리퍼의 열림 정도(gripper_extension): 연속적인 값이므로 256개의 빈으로 쪼개어 나타냄
- 에피소드 종료를 위한 이산 명령(terminate): 작업 완료를 알리는 데에 사용됨 → 0 or 1
- RT-2 는 실제 로봇을 실행하기 위해 필요한 유효 행동 토큰을 생성한다는 점에서 기존 다른 VLA와 다름
- robot-action task 로 프롬프팅되는 경우: robot action 으로 유효한 토큰만 생성
- 일반적인vision-language task 로 프롬프팅되는 경우: 전체 자연어 토큰 생성
- RT-2 는 VLM 의 기본 능력을 유지하면서도, 로봇 제어라는 특정 목적에 맞게 출력 형식을 전환하여 유효한 로봇 행동을 생성할 수 있도록 하고 있음
- 입력 텍스트: VQA 형식에 기반함
- Co-Fine-Tuning
- 파인튜닝할 때 로봇 데이터만 쓰는 것보다 original web data 를 함께 섞어서 하는 것이 성능이 더 좋았음
Real-time Infernece
- 연구에서 training 한 가장 큰 모델은 55B 사이즈를 가짐
- 로봇 내장 GPU 를 사용하여 추론하는 것은 현실적으로 불가능함
- 실시간으로 사용 가능하도록 프레임워크를 제안함
- 55B의 경우 1~3Hz 로 실행 가능
- 5B의 경우 5Hz 로 실행 가능
Experiment
- 학습 모델: RT-2-PaLI-X(55B), RT-2-PaLM-E(5B)
- 비교 모델: RT-1, VC-1, R3M, MOO
- RT-2는 기존 작업에서 어떻게 수행되며, 더 중요하게는 새로운 객체, 배경, 환경에 대해 어떻게 일반화하는가?
- RT-1 실험에서 사용된 200개 이상의 작업 포함 다양한 테스크에 대한 실험
- 일반화 성능 비교를 위해 Unseen Objects, Unseen Backgrounds, Unseen Environments 에 대한 실험을 진행함
- RT-2 는 일반화 비교 실험에서 다른 Baseline Models 보다 높은 성능을 보임 → VLM 의 효과성 입증
- RT-2의 새로운 출현 능력을 관찰하고 측정할 수 있는가?
- 로봇 데이터에는 없던 새로운 기능을 VLM 이 가지고 있는 능력으로 확보할 수 있는지
- RT-2가 장면의 맥락에서 의미론적 이해와 기본적인 추론 측면에서 새로운 능력을 상속받는 것을 발견함
- "테이블에서 떨어지려 하는 봉투를 집어라"와 같은 작업에서는 RT-2가 두 봉투를 구별하고 위태롭게 놓인 객체를 인식하기 위한 물리적 이해를 보여줌
- Symbol understanding, Reasoning, Human recognition 의 영역에서 RT-1, VC-1 등을 능가함
- 매개변수 수와 다른 설계 결정에 따라 일반화가 어떻게 달라지는가?
- from-scratch, fine-tuning, co-fine-tuning 세 가지로 나누어 실험
- from-scratch: VLM 가중치를 전혀 사용하지 않고 처음부터 학습
- fine-tuning: 로봇 데이터셋을 활용하여 파인 튜닝
- co-fine-tuning: 연구의 주요 방법, VLM 을 학습할 때 사용한 데이터셋과 로봇 데이터셋을 함께 사용하여 파인튜닝
- 비교 결과
- 모델의 크기가 크면 클수록 일반화 성능이 좋았음
- 모델 크기와 무관하게 co-fine-tuning 이 fine-tuning 보다 성능이 좋았음
- from-scratch, fine-tuning, co-fine-tuning 세 가지로 나누어 실험
- RT-2가 비전-언어 모델과 유사하게 사고의 연쇄 추론 능력을 보일 수 있는가?
- CoT에 영감 → 자연어로 된 Plan 을 중간에 생성하도록 함
- Instruction: I’m hungry. Plan: pick rxbar chocolate. Action: 1 128 124 136 121 158 111 255.”
- 중간에 생성하는 ‘Plan’ 이 별게 아니라 high-level plan 임
- 자연어를 통한 행동 계획으로 더 정교한 명령에 응답할 수 있음을 정성적으로 관측함
- CoT에 영감 → 자연어로 된 Plan 을 중간에 생성하도록 함
Limitation
- 로봇이 새로운 물리적인 동작을 자체적으로 습득하지는 못함
- 모델의 물리적인 기술은 여전히 로봇 훈련 데이터에서 학습된 기술 분포에 제한됨
- 높은 연산 비용
- 제한적인 사용 가능한 VLM 모델 수
- 파인튜닝을 해야하는데 공개된 VLM 은 제한적이다.
[Docs] Building Effective Agents
- Anthropic 에서 제안하는 Agent 를 효율적으로 사용하는 방법
- Building Effective Agents
Agent
- Agent 의 정의는 매우 다양함. Antropic 에서는 Workflow 와의 비교를 통해 설명하고 있음
- Workflows: 사전에 정의된 순서대로 LLM과 tool이 실행되는 시스템
- Agents: LLM 이 task 를 수행하기 위해 동적으로 tool 을 사용하는 시스템
- Agent 는 보통 비싸고 느리다. 따라서 필요할 때만 쓰는 것이 좋다(문제의 복잡성과 비용 간의 트레이드 오프)
- agents are the better option when flexibility and model-driven decision-making are needed at scale.
- 하지만 많은 문제에 있어, 단순한 LLM + RAG 시스템으로도 충분히 효과적으로 해결할 수 있다.
Building blocks, workflows, and agents
- Agentic system 에는 다양한 패턴이 있으며, 풀고자하는 문제의 복잡성에 따라 적절한 패턴을 사용하는 것이 중요함
- Building blocks, workflows, Agents 등으로 나누어 볼 수 있음
Building block(LLM augmented):
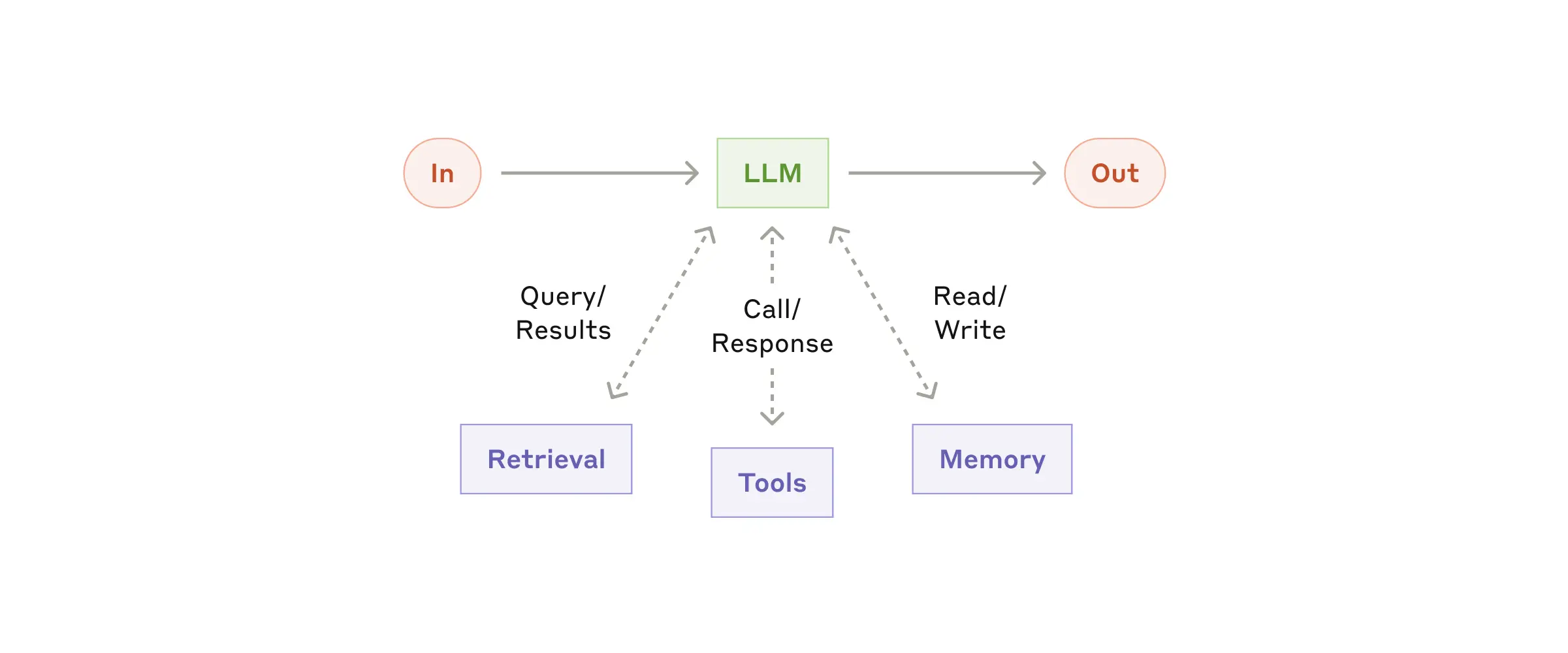
- retrieval, tools, memory 가 augmented 된 LLM
- 적절한 search query 생성, 적절한 tool 선택, 필요한 정보를 memory 에서 가져오는 기능이 필요하다.
- 구현에 있어 고려해 볼 두 가지 요소
- 기능들을 특정 사용 사례에 맞게 조정하기: 실제 문제 해결에 각 기능들이 사용될 수 있도록 최적화해야 한다.
- LLM에 쉽고 잘 문서화된 인터페이스 제공하기: 추가된 기능들을 LLM 이 잘 이해하고 사용할 수 있도록 만들어야 한다
- 이러한 문제를 해결하는 도구 중 하나가 MCP(Model Context Protocol) -> tool 을 만드는 방식을 표준화한 것
Workflow: Prompt chaining
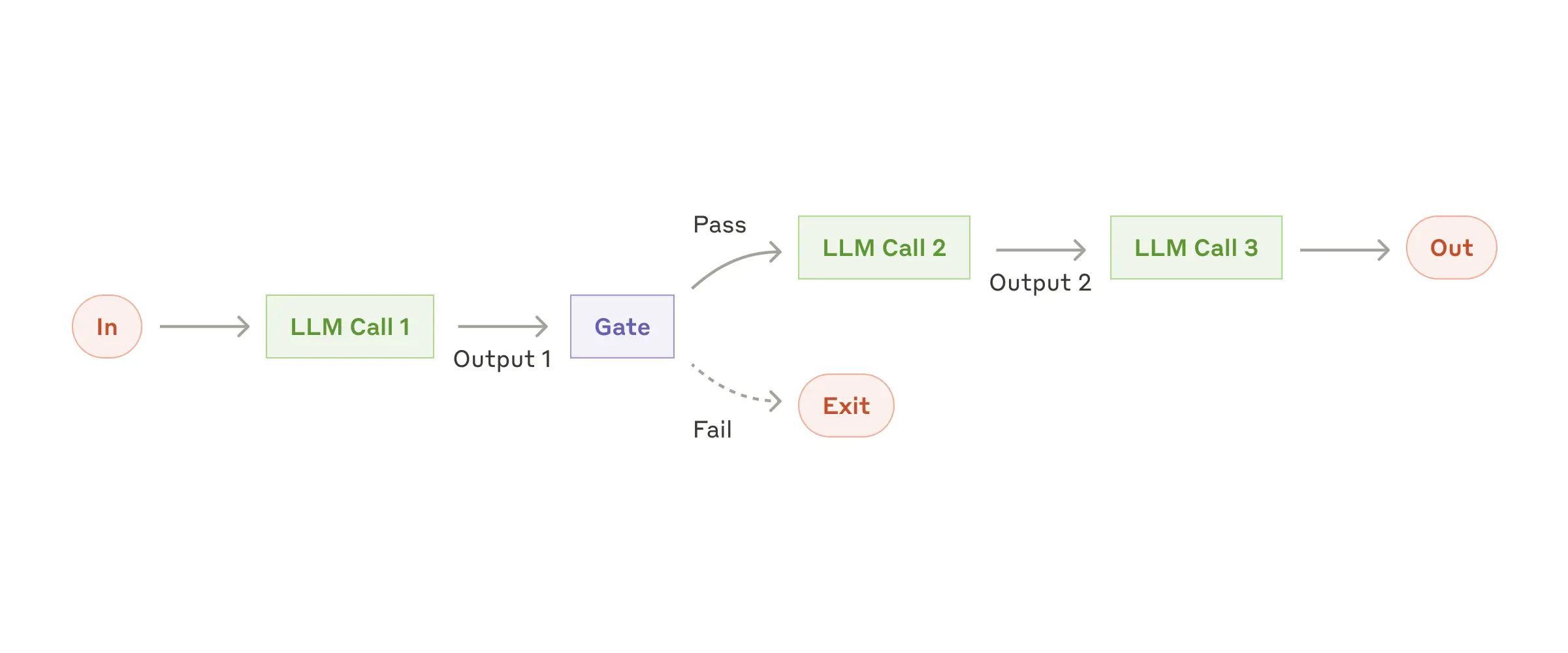
- 여러 개의 분기된 seqeunce 가 있고, task 의 유형에 따라 거치는 step 이 달라지는 구조
- 중간 중간에 Programmatic checks(Gate)가 있어서 분기 처리를 해 줌
- Task 의 유형이 고정적이고, 각 유형에 따라 처리하는 방식이 고정적인 경우에 활용
- 쉽게 해결할 수 있는 Task 는 LLM 을 적게 호출하므로 효율적임
Workflow: Routing
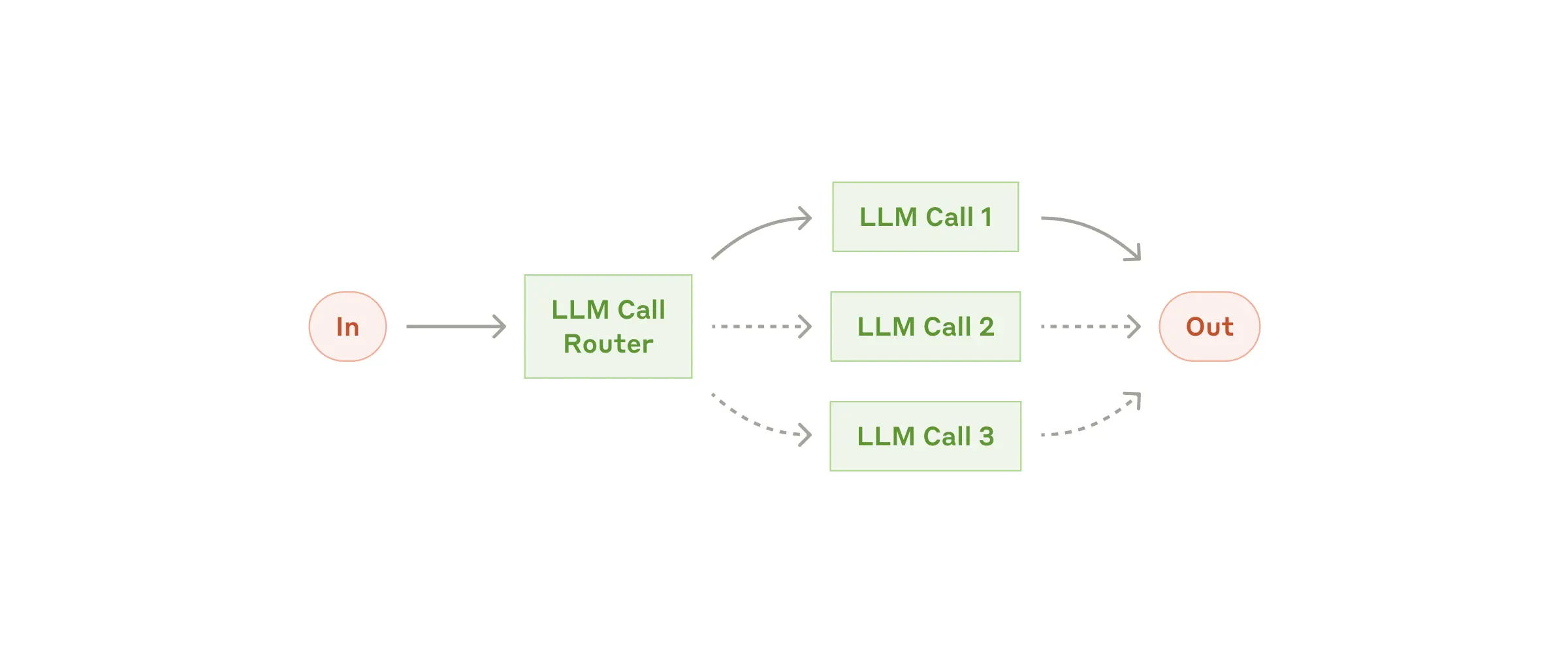
- Task 의 유형에 따라 specialized 된 방식으로 처리할 수 있도록 하는 구조
- 복잡하지만, 카테고리화가 명확한 문제에 효율적인 구조
Workflow: Parallelization
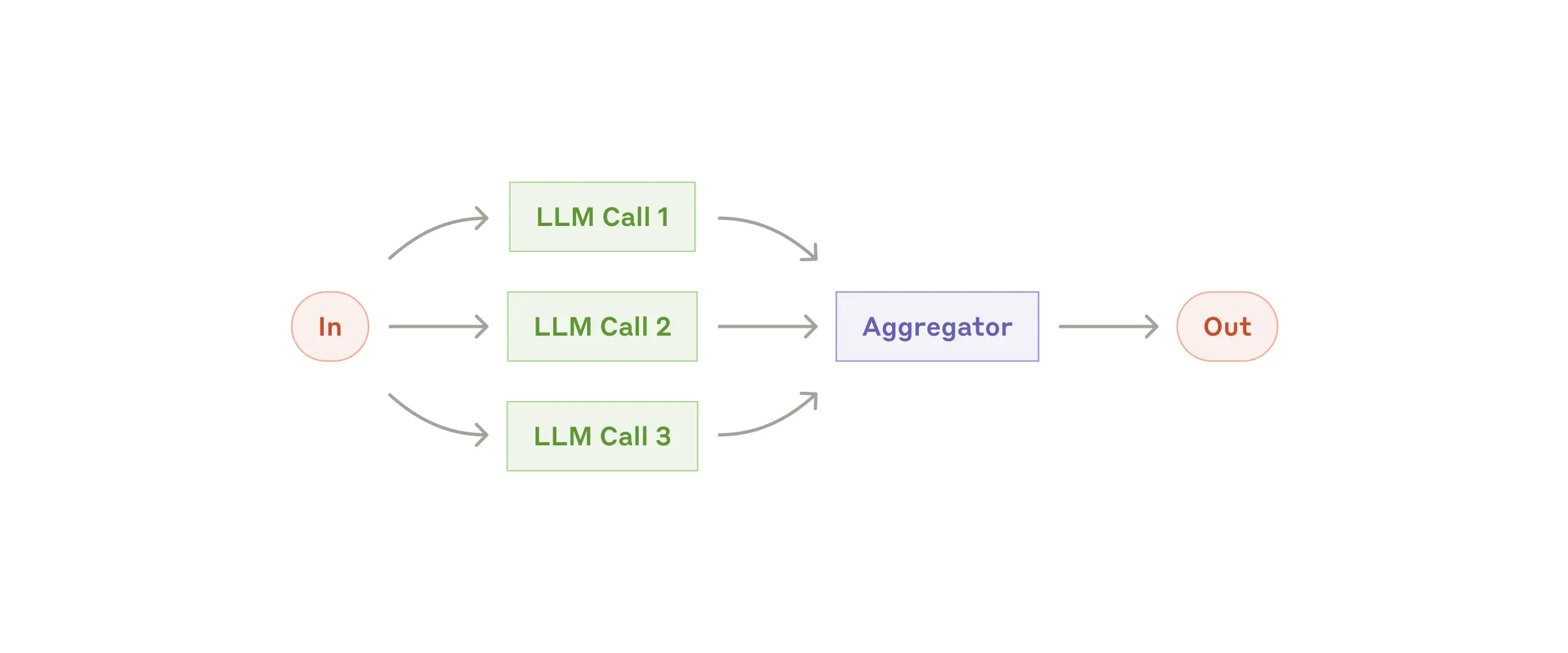
- 동시에 여러 방식을 수행한 후, 모든 결과를 최종 결과물을 만들어내는 데에 함께 사용하는 구조
- Selection, Voting 등이 사용될 수 있음
- 고려사항이 다양한 문제를 푸는 경우
Workflow: Orchestrator-workers
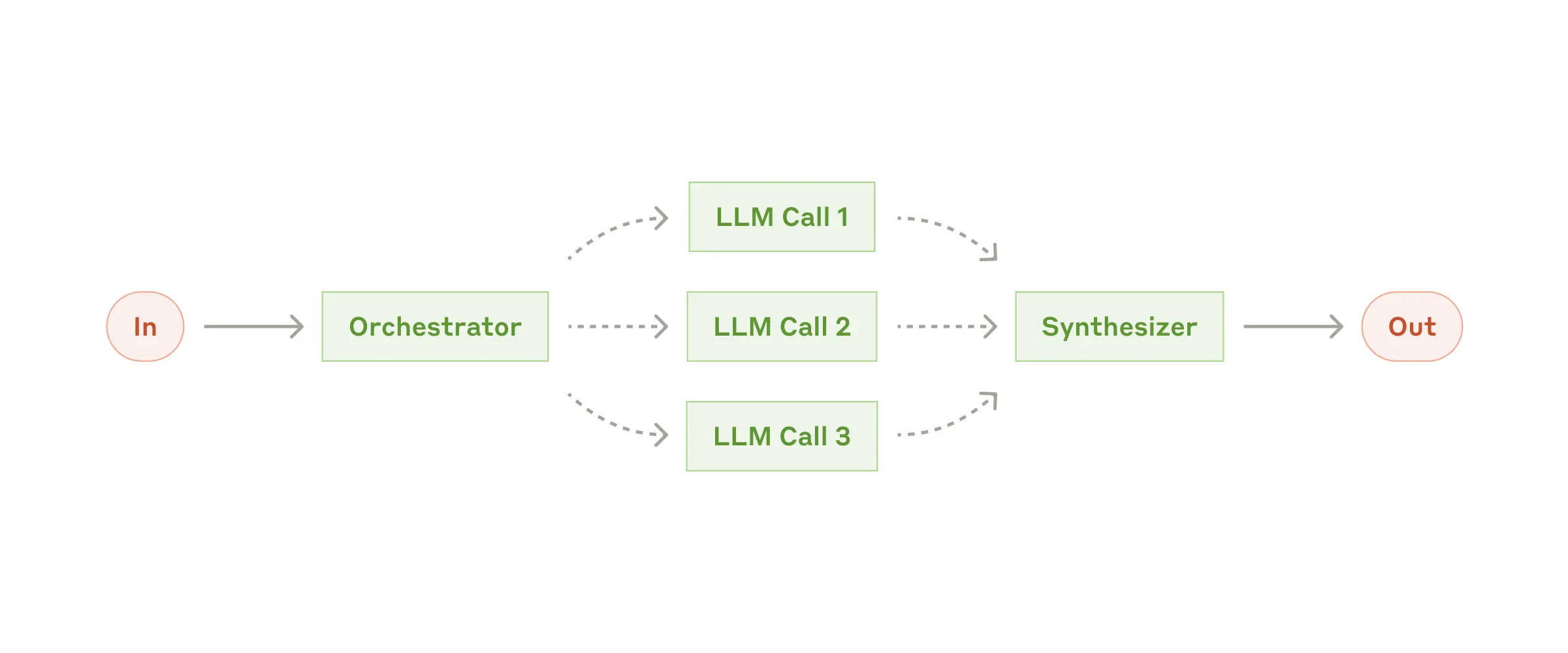
- 복잡한 하나의 문제를 여러 문제로 쪼갠 후 각각의 LLM 에 맡긴 뒤, 통합하여 최종 출력을 만들어내는 구조
- Orchestrator 가 어떤 LLM 을 사용할 것인지 결정한다는 점에서 Parallelization 과 다름
Workflow: Evaluator-Optimizer
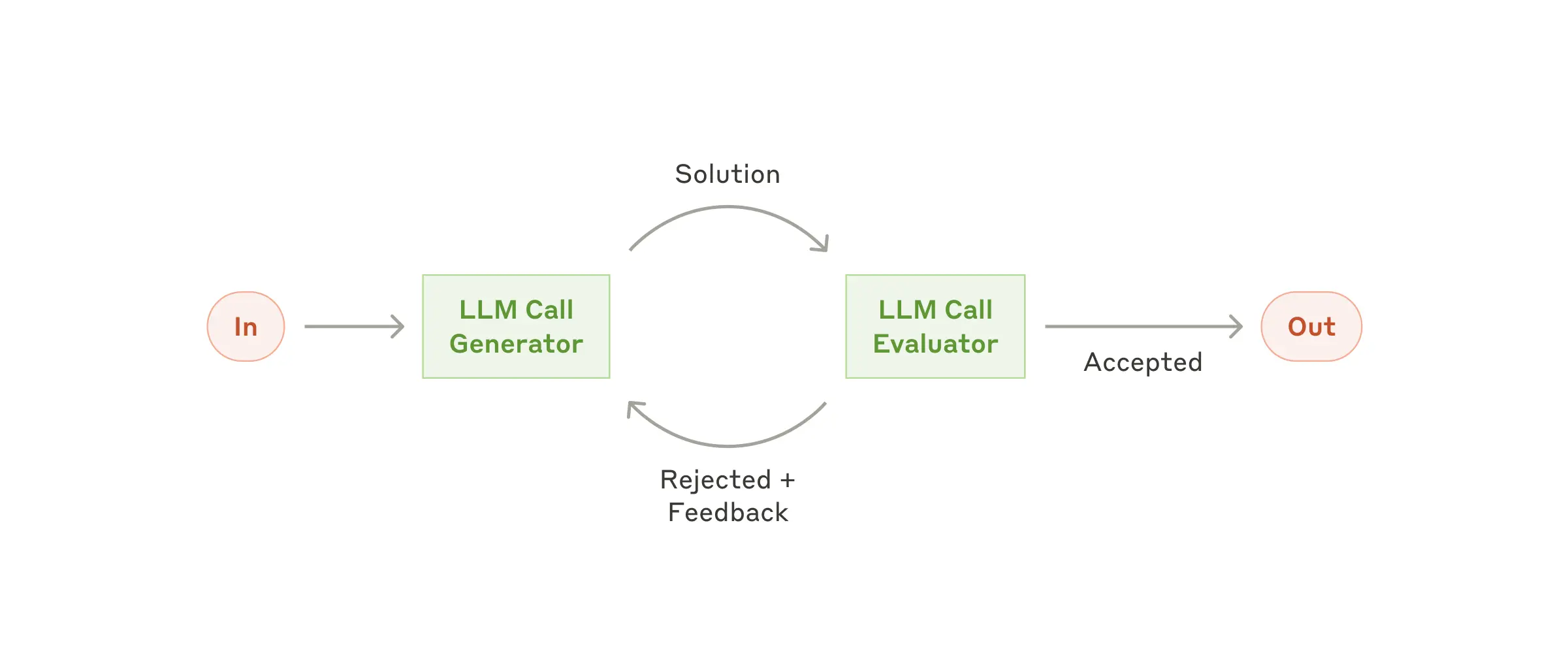
- LLM 이 생성한 결과를 Evaluator LLM 이 평가하고, Feedback 을 제공하여 반복 개선하는 구조
- evaluation 기준이 명확하고, 반복 개선이 가능한 문제을 다룰 때 효과적
Agents
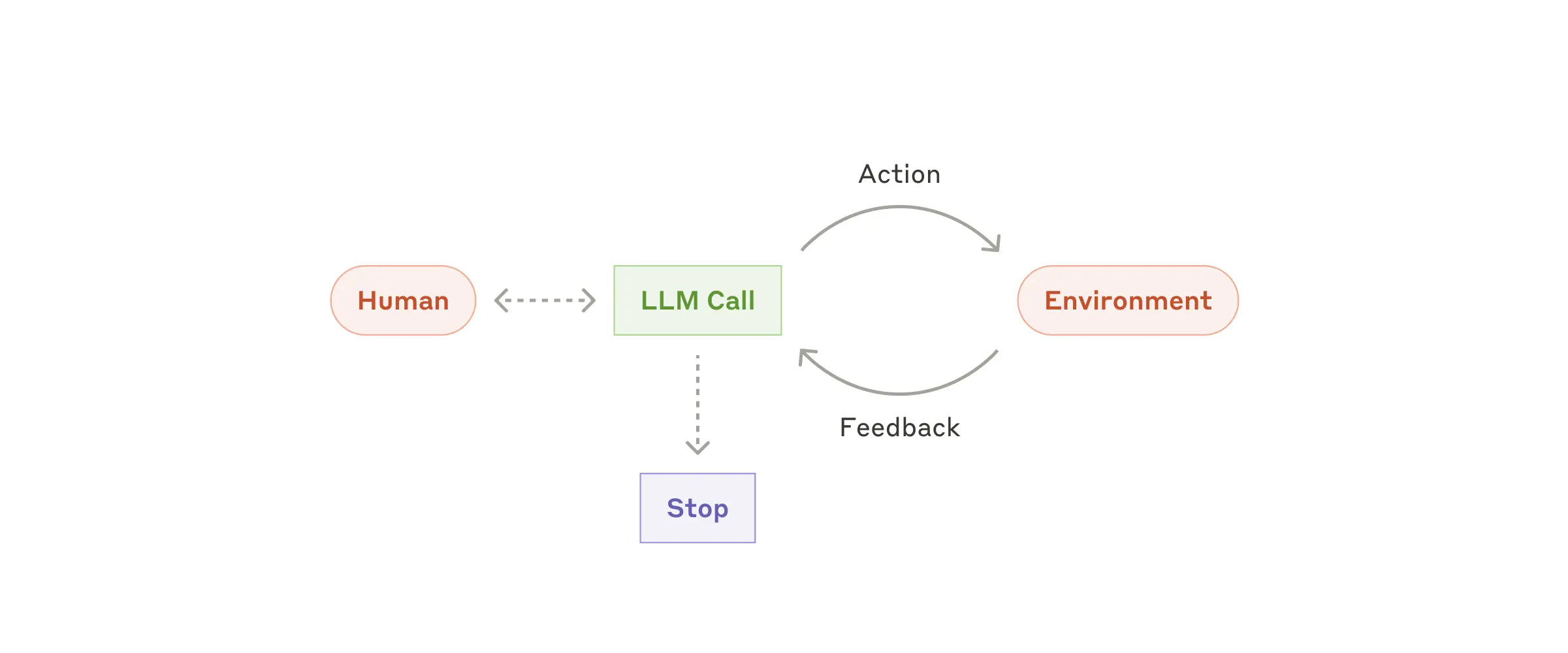
- Agent 사용자와의 상호작용을 통해 문제를 정의하고, 독립적으로 해결 방법을 계획하여 수행하게 된다. 이 과정에서 추가적인 정보를 사용자에게 요청할 수도 있고, 결과물에 대한 피드백을 받을 수도 있다.
- LLM 이 가지고 있는 복잡한 입력을 이해하고, 이를 바탕으로 추론 및 계획한 뒤, 도구들을 적절히 사용하여 해결하는 능력, 에러가 발생하더라도 적절히 대처하는 능력을 활용
- Agent는 문제 해결을 위해 어떤 도구를 사용하는 것이 좋을지, 얼마나 많은 step 을 거치는 것이 좋을지 판단하기 어려운 복잡한 문제를 해결하는 데에 도움이 된다.
효율적인 agent 구현을 위한 Core Principles
- agent 디자인에 있어 단순함을 유지하라
- 명시적으로 agent의 step planning 을 보여주도록 하라
- 철저한 도구 문서화 및 테스팅을 통해 좋은 agent-computer interface(ACI) 를 만들어라
- 프레임워크를 사용하는 것도 좋지만, 프로덕션 단계로 넘어갈 때에는 추상화 계층을 최대한 줄이고, 기본적인 구성 요소로 구축하는 것을 지향하는 것이 좋다.
appendix 2: prompt engineering your tools
- agentic system 을 만들 때에는 tool 을 어떻게 만드느냐가 매우 중요함
- 각 tool 을 정의하고, 설명하는 프롬프트를 작성할 때에는 매우 많은 주의를 기울여야 함
- tool 개발 시 고려해야할 권장 사항들
- 모델이 막다른 길에 도달하기 전에 충분히 생각할 수 있도록 충분한 토큰 제공하기
- 형식을 인터넷에서 자연스럽게 발견되는 텍스트와 유사하게 유지하기
- LLM 이 잘 하지 못하는 부분들 없애기(수천 줄의 코드를 정확히 세는 것, 작성하는 코드를 문자열 이스케이프하는 것과 같은 형식 지정하는 것)
- 훌륭한 에이전트-컴퓨터 인터페이스(ACI)를 만드는 방법
- 모델의 입장이 되어 생각해보기 - 좋은 도구 정의는 종종 사용 예시, 예외 사례(edge cases), 입력 형식 요구사항, 그리고 다른 도구와의 명확한 경계를 포함함
- 매개변수 이름이나 설명을 어떻게하면 더욱 명확히 할 수 있을지 생각해보기 - 주니어를 위한 독스트링 작성
- 모델이 도구를 어떻게 사용하고 있는지 테스팅하기
- 도구에 poka-yoke 적용하기 - 실수를 저지르기 더 어렵도록 arugment 를 변경하기
- poka-yoke: 실수 방지 를 뜻하는 일본어, 제조 공학 용어 - 인간의 실수를 방지하거나, 실수가 발생하더라도 피해를 최소화하는 구조 및 설계를 지칭
- “모델이 루트 디렉토리 밖으로 이동한 후 상대 파일 경로를 사용하는 도구에서 실수를 저지르는 것"을 발견 → 도구가 항상 절대 파일 경로를 요구하도록 변경 (실수하지 않도록 방지함)
[Paper] LLaVA: Visual Instruction Tuning
contribution
- Dataset: Multimodal instruction-following dataset
- language-only GPT-4 모델을 사용하여 multimodal language-image instruction-following dataset 을 생성함
- Large multimodal model 제안: LLaVA(Large Language and Vision Assistant)
- vision encoder 와 LLM 을 연결하는 End-to-End Model
- Image Encoder(CLIP) + Language Decoder(Viduna)
- Fine-Tuning 도 진행함
- Benchmark: LLaVA-Bench
GPT-assisted Visual Instruction Data Generation

- 이미지와 그에 대한 캡션이 있다고 할 때, 그것에 맞는 질문을 생성하고, 묶는 것만으로는 다양하고 추론을 요구하는 문제를 만드는 것에 한계가 있음
- 이를 해결하기 위해 GPT-4, ChatGPT 와 같은 language-only 모델들을 visual content 를 포함하는 instruction-following 데이터셋을 만드는 데 있어 strong teacher 로 사용함
- 두 가지 symbolic representations 사용: Captions, Bounding boxes
- 이 두 가지는 LLM 이 이해할 수 있는 sequence 형태로 이미지를 인코딩할 수 있게 해줌
- COCO 데이터셋의 이미지를 사용했으며, 최종적으로 세 가지 종류의 instruction-following data 를 생성함
- Conversation: 이미지에 대해 질의하는 사람과 그것에 대해 응답하는 assistant 에 대한 대화.
- Detailed description: 이미지에 대한 제세하고 풍부한 설명.
- Complex reasoning: step-by-step reasoning process 를 통해 복잡한 추론을 요구하는 질문과 응답.
- 총 158K 개의 샘플 추출
- 58K conversation, 23K detailed description, 77K complex reasoning
Visual Instruction Tuning
- Vision Encoder
- CLIP 의 visual encoder ViT-L/14 를 사용
- trainable 한 projection layer 를 붙여, word embedding space 로 사영
- 단순함이 핵심, 아래와 같이 더 복잡한 방법들이 있었지만 단순하고 효율적인 방법을 쓰고 싶었다.
- Flamingo → gated cross-attention
- BLIP-2 → Q-former
- large language model 로는 Vicuna 사용
Training
- Conversation 데이터의 경우 question, answer 가 반복되는 구조로 되어 있음
- Intruction 은 다음 수식 처럼, 첫 step 에 question 이 먼저 올지, image 가 먼저 올지 랜덤하게 샘플링하여 입력으로 전달.
- 두 번째 부터는 question 만 instruction 으로 사용
- 만들어진 instruction 은 아래 이미지처럼 사용됨
- auto-regressive training objective function
- 위의 이미지와 아래 objective function 의 녹색 부분이 예측 대상이자 loss 계산 시 사용되는 부분
<STOP>=###을 예측해야 함- Assistant 의 답변을 예측해야 함
- 그 외 system message 나 human 이 주는 것으로 간주하는 x_instruction 등은 loss 계산에 포함되지 않음
- 위의 이미지와 아래 objective function 의 녹색 부분이 예측 대상이자 loss 계산 시 사용되는 부분
- Stage1: Pre-training for Feature Alignment
- LLaVA 모델이 시각적 특징과 언어 모델의 임베딩 공간을 서로 조율하는 것을 목표
- 데이터셋: CC3M 에서 필터링한 이미지-텍스트 쌍 사용
- naive expansion 방법을 사용하여 단일 턴(single-turn) 대화 형식의 instruction following data 로 변환
- 이미지 + “이 이미지를 설명해줘” 와 같은 단순한 instruction → caption 생성
- image encoder 와 LLM 은 고정, projection layer 만 학습
- 이 단계를 거치지 않을 경우 성능이 5.11% 감소하는 것을 확인함
- Stage2: Fine-tuning End-to-End
- image encoder 는 고정, projection layer 와 LLM 은 업데이트
- 데이터셋: 앞에서 설명한 GPT4 로 생성한 데이터셋 사용
Experiment
- 다음 두 가지 use case 에 대해 실험: Multimodal Chatbot, Science QA