- Published on
This Week I learned 1
Summary
1. [Paper] Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation
- Low-level Motion Planner 로서의 LLM
- Grounded SAM(Affordance 추출) -> LLM(Waypoints, Path 추출) -> LLM(경로 추론)
2. [Paper] CognitiveDrone: A VLA Model and Evaluation Benchmark for Real-Time Cognitive Task Solving and Reasoning in UAVs
- 높은 수준의 인지 능력을 요구하는 자연어 구조의 Task를 자율적으로 수행할 수 있는 모델 생성
- OpenVLA 로 실시간 제어 + LLM(Qwen)으로 Task 이해
3. [Paper] OpenVLA: An Open-Source Vision-Language-Action Model
- Image + Text 를 입력으로 받아 Action 을 결정하는 VLA 모델
- Vision Encoder + MLP Projector + LLM Backbone 으로 구성(VLM 구성과 유사)
4. [Paper] SIMULATING HUMAN-LIKE DAILY ACTIVITIES WITH DESIRE-DRIVEN AUTONOMY
- 내재적인 욕구와 개인의 특성을 반영하여 인간과 유사하게 행동을 스스로 결정하는 Agent 개발
5. [Paper] ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings
- ObjectNav, 시뮬레이션 내에서 특정 물체를 찾아내는 문제를 해결하는 모델
- 특히, Open World 즉 학습 시에 보지 못한 종류의 물체에 대해서도 해결하도록 하는 것이 목표
- CLIP 을 사용하여 학습 시에는 이미지 인코더로, 평가 시에는 텍스트 인코더로 작업을 수행하도록 함
Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation
Problem
- High-level Task Planning 뿐만 아니라 Low-level Motion Planner 로서도 LLM 이 기능할 수 있을까?(can LLMs not only handle high-level tasks but also serve as low-level motion planners?)
- 기존 LLM 기반 Agent들은 Vision-Language Navigation Task 에 있어 고수준의 작업 계획(High-level task planning)에만 초점을 맞춰 왔음
- 저수준의 Policy Training을 위해서는 여전히 시뮬레이터로부터 많은 데이터를 수집해야 함
AO-Planner: Affordance-Oriented Planner
- 다양한 파운데이션 모델을 통합하여 어포던스 지향적인 저수준 동작 계획 및 고수준 의사 결정을 모두 제로샷 설정에서 수행할 수 있도록 함
- 어포던스(affordances) 내의 픽셀 수준 경로 계획을 통해 LLM의 RGB 공간 예측과 3D 세계 내비게이션 사이의 간극을 메우는 것이 목표
Steps
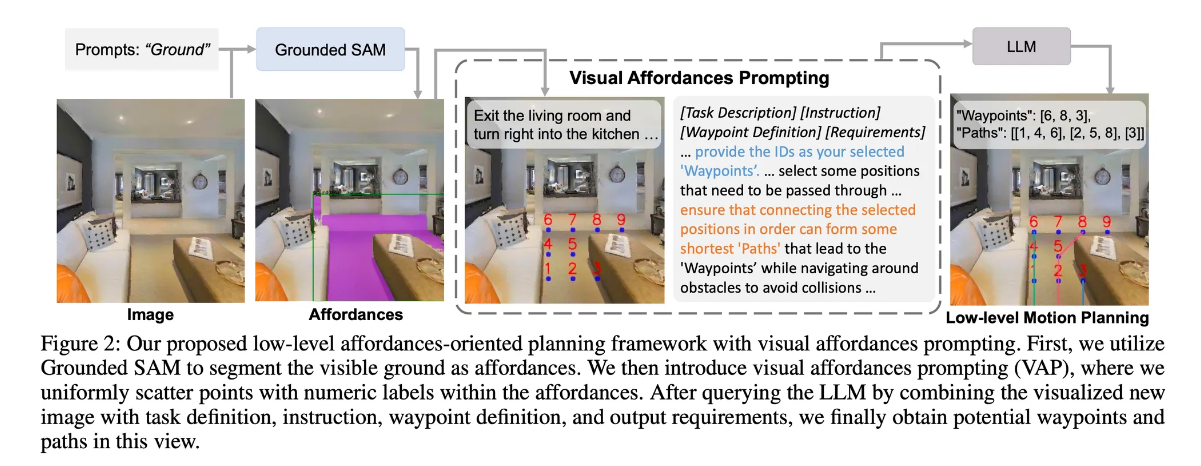
- Grounded SAM 을 통한 Navigational Affordance 추출(Segmentation)
- Visual Affordance Prompting(VAP) 를 통해 가능한 Waypoint 와 Path 추출(LLM)
- Path Agent 를 통한 Path 결정(LLM)
Affordance Segmentation
- 이동 가능한 지면 영역을 Navigation Affordance 로 분할하여, LLM 이 선택 가능한 포인트들을 샘플링하는 단계
- Grounded SAM 모델을 사용함, Grounded SAM = Grounded DINO + SAM(Segment Anything Model)
- Grounded DINO 는 Ground 의 대략적인 위치를 탐지로 바운딩 박스를 추출
- SAM 은 바운딩 박스 상에서 정확한 Ground(Affordance) 픽셀을 추출
Visual Affordance Prompt(VAP)
- Affordance Segmentation 을 LLM 의 입력으로 전달하여 잠재적인 Way Points 를 추출하고, 각 Way point 로 향하는 low-level path 를 계획하는 단계
- 3D 정보 없이 RGB 공간에서 전적으로 수행되는 것이 특징
: Way Point
: Path
: 저수준 작업 설명, "장애물을 회피하여 경로를 선택할 것" 등과 같이 웨이 포인트와 경로를 추출하는 데에 필요한 구체적인 정의를 포함함
: 현재 Episode 와 관련된 지시 시항
: Affordance Segmentation 정보가 포함된 이미지
LLM 호출이 비싸므로, LLM 을 어노테이터로 활용하여 수집한 데이터셋으로 새로운 학습 기반 Way Point Predictor 를 만드는 시도도 있음(Way Point Distillation)
PathAgent
- 선택 가능한 Way points 와 Path 를 이미지에 표시하고, 환경 정보들을 함께 사용하여 가장 유력한 경로를 추론하는 단계
- : 선택 가능한 Way points 와 Path 가 증강된 이미지
- : 고수준의 작업 설명
- : 현재 Episode 와 관련된 지시 시항
- : 과거 정보
3D Mapping and Motion Control
- 카메라 내재 매개변수(camera intrinsic parameters)와 깊이 정보(depth information)를 결함하여 RGB 공간의 픽셀 예측을 일련의 3D 좌표로 변환하여 에이전트를 지정된 위치로 내비게이션함
- 3D 좌표로 변환된 각 선분(path의 일부)에 대해 ETPNav 의 저수준 컨트롤러를 따름
- 상대적인 방향과 거리를 계산한 후, VLN-CE 작업의 정의된 액션 공간 상의 액션으로 변환됨
Ideas
- Grounded DINO 로 바운딩 박스를 먼저 추출하고 Segment 하는 것이 효율적일까? 바로 Segment 하는 것이 낫지 않을까?
- DINO 모델 확인하기
CognitiveDrone: A VLA Model and Evaluation Benchmark for Real-Time Cognitive Task Solving and Reasoning in UAVs
Objective
- 높은 수준의 인지 능력을 요구하는 자연어 구조의 임무를 자율적으로 수행할 수 있는 모델 생성
CognitiveDrone Architecture
- 두 개의 모델로 구성됨
- OpenVLA based model: 비행 물리학 이해를 기반으로 실시간 제어 명령을 생성하는 모듈
- Qwen2.5-VL based model: 작업 지침을 정제하고 명료화하는 느리지만 강력한 추론 모듈
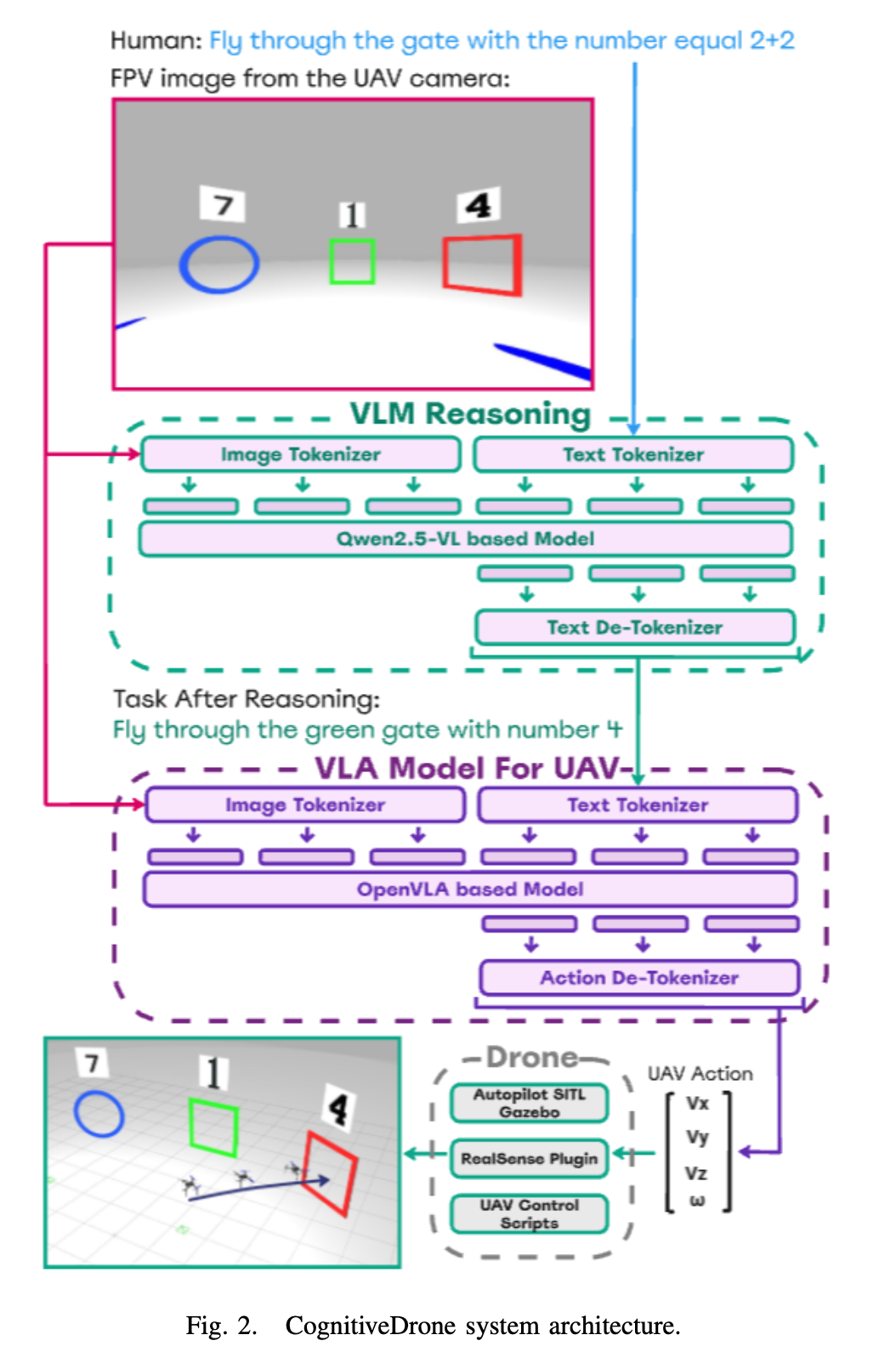
VLA Model For UAV
- UAV가 단순히 비행하는 것을 넘어, 높은 수준의 인지 능력을 요구하는 복잡한 임무를 수행할 수 있도록 특별히 설계된 VLA(Vision Language Action) 모델
- 8000개 이상의 시뮬레이션된 비행 궤적 데이터셋으로 훈련
- Tasks: Human recognition, Reasoning, Symbol Understanding
- 1인칭 입력(드론의 카메라)과 자연어 명령을 바탕으로 실시간 4D 액션 명령을 생성함
- Actions: 드론의 전후, 좌우, 상하 속도 및 회전 속도
VLM Reasoning
- 고주파(10Hz) 제어를 담당하는 main VLA 보다 낮은 주파수(2Hz)로 작동하면서 작업 지시의 모호성을 해결하고 복잡한 명령을 VLA 모델이 실행할 수 있는 명확한 액션으로 단순화하는 역할을 담당
CognitiveDroneBench
- Gazebo 기반 물리 시뮬레이션 환경 위에 구축된 오픈 소스 벤치마크
Model Training
- OpenVLA 와의 호환성을 위해 RLDS(RL Dataset) 형식으로 학습 데이터 구조화
- OpenVLA-7B 모델을 파인튜닝하는 데에 사용
- 효율적인 업데이트를 위해 LoLA 를 사용함, rank-32 어댑터 적용
- 네 대의 A100 GPU 사용
Ideas
- Base Model 이라 할 수 있는 OpenVLA 확인하기
- RLDS(Reinforcement Learning Dataset) 이 무엇인지 확인하기
OpenVLA: An Open-Source Vision-Language-Action Model
Problems
- 기존 VLA 모델들은 대부분 비공개
- 일반화 성능이 낮고, 새로운 작업들에 대해 효율적으로 파인튜닝하는 방법에 대한 연구가 부족했음
- 소비자 레벨의 GPU 에서 구동하는 것이 어려웠음
OpenVLA Model Architecture
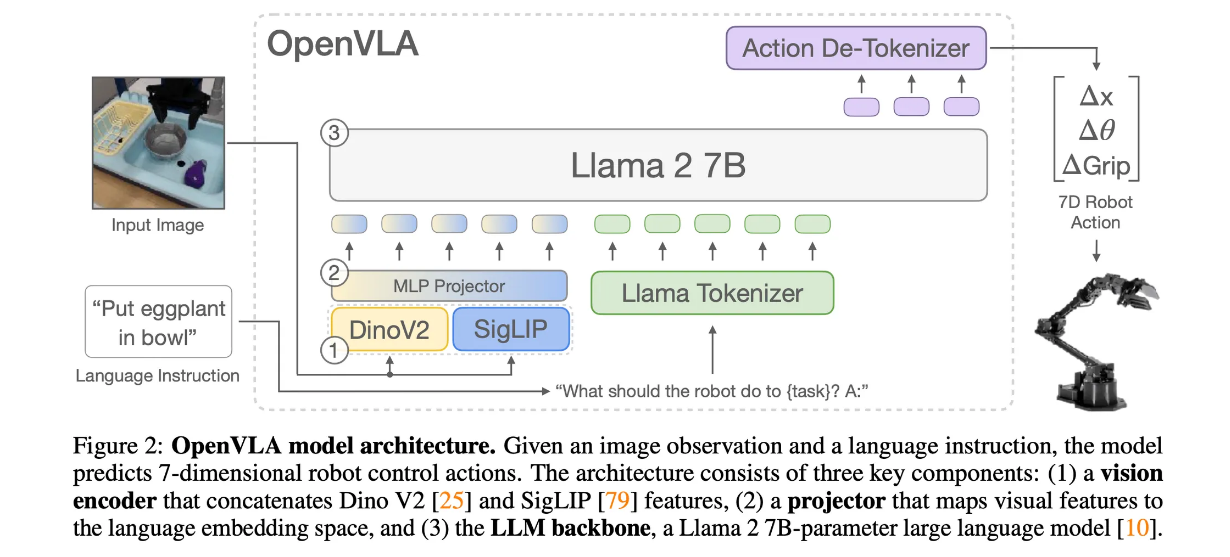
- 기존 policies for robotic manipulation 은 일반화 성능이 낮은 문제를 가짐, 즉 트레이닝 시 보지 못한 특성을 가진 작업은 잘 수행하지 못함
- CLIP, CigLIP, Llama2 와 같은 vision language model 들은 높은 일반화 성능을 보임
- 따라서 기존 비전 언어 모델들을 핵심 구성 요소로 사용하면 높은 일반화 성능을 가지는 로봇 조작 모델을 만들 수 있을 것으로 기대
- Prismatic-7B VLM 을 기반으로 구축
- Vision Encoder + MLP Projector + LLM Backbone 으로 구성(VLM 구성과 유사)
- Vision Encoder: SigLIP, DinoV2(DinoV2 를 추가했을 때 공간 추론을 더욱 잘하는 것으로 나타남)
- MLP projector: 2 MLP layer
- LLM Backbone: Llama2 로봇 행동의 각 차원을 256 개의 bin 중 하나로 이산화
- Vision Encoder + MLP Projector + LLM Backbone 으로 구성(VLM 구성과 유사)
- 연속적인 로봇 행동을 언어 모델의 토크나이저가 사용하는 이산적인 토큰으로 매핑하여 LLM 의 출력 공간에 행동을 표현할 수 있도록 함
- input: observation image + natural language task instruction
- output: string of predicted robot actions
Architecture 설계 시 고려사항
- 본격적인 학습에 앞서 소규모 실험을 통해 설계 방법을 탐색함
- OpenX 데이터셋 대신 BridgeDataV2 를 사용하여 초기 실험을 진행
- VLM backbone
- Prismatic 외 IDEFICS-1, LLaVA 등에 대해 테스트를 진행함
- Prismatic 의 성능이 가장 좋았음, SigLIP 과 DinoV2 백본의 융합으로 인해 공한 추론 능력이 향상된 것을 이유로 봄
- Image Resolution
- 224x224 와 384x384 를 비교함 → 성능 상 큰 차이 없음, 시간은 3배 더 걸림 → 224 x 224 선택
- Vision Encoder
- 일반적으로는 비전 인코더는 고정한 채로 파인튜닝하는 것이 좋다고 알려져 있음
- 여기서는 비전 인코더를 함께 파인튜닝하는 것이 VLA 성능 개선에 결정적
- Training Epoch
- VLM 트레이닝에는 많아야 2 에폭
- VLA 트레이닝에서는 반복 트레이닝하는 것이 성능 향상에 도움이 됨을 확인함 → 27 에폭 수행
Model Training
- 사전 훈련된 Prismatic-7B 모델을 백본으로 모델 행동 예측을 위해 파인튜닝
- Training Dataset 확보
- 로봇의 다양한 형태(embodiments), 장면(scenes), 작업(tasks)을 광범위하게 포괄하는 데이터 셋 구성 목표
- Open-X Embodiment 데이터셋의 97만 개(970k) 로봇 조작 궤적으로 구성된 대규모의 다양한 데이터셋 사용
- 데이터 큐레이션: 일관된 입출력 공간 확보 및 로봇 형태, 작업, 장면 간의 밸런스 고려 → Octo 의 데이터 혼합 가중치 활용
- 로봇의 다양한 형태(embodiments), 장면(scenes), 작업(tasks)을 광범위하게 포괄하는 데이터 셋 구성 목표
- Training Dataset 또한 실제 로봇의 연속적인 액션으로 구성되어 있으므로 이산화 필요
- 훈련 데이터의 동작의 1% 분위 수와 99% 분위 수 사이를 256개로 쪼개어 이산화함(Rt-2 에서는 min-max 를 사용)
- 아웃라이어를 줄이고, bin 간의 간격을 줄여 유효한 수준의 세분성을 다루기 위함
- bin 간의 간격이 너무 크면 모델이 동작을 정밀하게 예측하는 능력이 떨어질 수 있음
- 훈련 데이터의 동작의 1% 분위 수와 99% 분위 수 사이를 256개로 쪼개어 이산화함(Rt-2 에서는 min-max 를 사용)
Ideas
- DinoV2 를 함께 사용했을 때 성능이 좋아진 이유 확인 필요(SigLIP, CLIP 등과 비교해보기)
SIMULATING HUMAN-LIKE DAILY ACTIVITIES WITH DESIRE-DRIVEN AUTONOMY
Problem
- 기존 에이전트들은 복잡하고 예측 불가능한 실제 환경에서 인간처럼 유연하고 적응적인 행동을 생성하는 데에 어려움을 겪음 -> 인간은 다양한 내재적 욕구에 의해 동기가 부여되고 행동한다는 점을 고려해보자
- 기존에는 고정된 환경에서 미리 결정된 작업을 얼마나 잘 수행하는지에 초점 맞춤 -> 개방형 환경에서 활동을 생성하는 문제를 다뤄보자
- 일부 연구들이 개방형 환경에서 외부 보상을 활용하나, 내재적 동기를 모델링하는 데에는 실패하였고, 일반화 성능이 좋지 못함
- 인간과 유사한 자율 에이전트를 만드는 것이 목표, 욕구에 기반하여 일상 활동을 자율적으로 생성하고 수행하는 프레임워크 제안
D2A(Desire-drieven Autonomous Agent) Framework
- 욕구 이론(Theory of Needs)에서 영감을 받은 동적 가치 시스템
- 각 단계에서 에이전트는 현재 상태의 가치를 평가하고, 일련의 후보 활동을 제안하며, 내재적 동기에 가장 잘 부합하는 활동을 선택함
- 에이전트가 자신의 내재적 동기에 부합하는 활동을 생성하고 추구할 수 있도록 권한을 부여하는 욕구 기반 자율성 프레임워크
- 메슬로우의 욕구 단계설에 영감, 인간의 행동이 다양한 내재적인 욕구를 충족시키려는 동기에 의해 움직인다는 아이디어
- 에이전트에게 특정 작업을 수행할 것을 명령하는 것이 아닌 여러 차원의 욕구를 설명하고, 에이전트에게 이러한 욕구를 충족시키는 행동을 추구하도록 함
Formulation
- The problem of simulating human-like daily activities in interactive environments without explicit task instructions.
- : 이전에 선택한 Action
- : 지금까지 확인한 Observation
- : 욕구 수치 등 Customized information
- : 나이, 성별, 이름, 특성 등 Agent 의 특징
- : 시뮬레이션 환경에 대한 설명
Agent
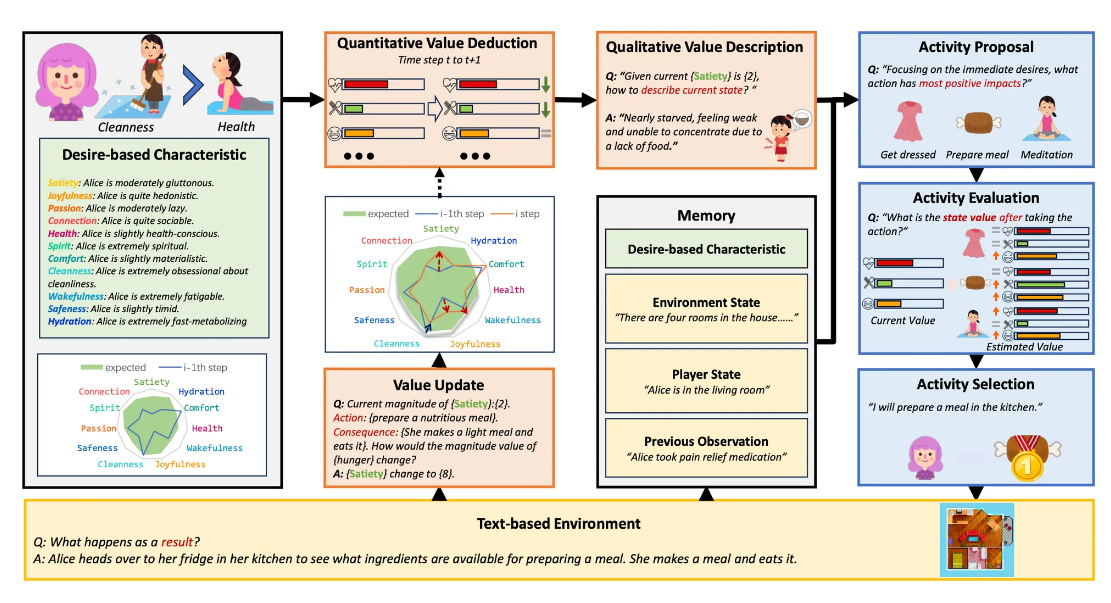
- 가치 시스템과 가치에 따른 행동을 결정하는 플래너로 구성
Desire Generation
- 인간 행동은 안전, 사회적 소속감, 존중, 자아실현과 같은 개인의 필요나 욕구를 충족시키려는 동기에서 비롯된다는 욕구 이론에 영감
- 성격 프로필()를 예상 욕구 값()과 연결하는 가치 시스템 개발
- 구체적으로 11가지의 기본적인 욕구 차원 정의
- 생리적 차원: '허기', '갈증', '졸음', '청결', '편안함', '건강'
- 안전 욕구: '안전감'
- 사랑과 소속감 욕구: '사회적 연결성'
- 자아실현 욕구: '기쁨', '열정', '정신적 만족'
- 다중 에이전트 환경에서는 '인정', '통제감', '우월감' 세 가지 욕구 차원이 추가되어 더 높은 수준의 사회적 동기를 통해 활동 생성을 유도
- 욕구 수준의 변화를 정량적으로 추적하고, 수치 값을 서술적 상태로 질적 변환하기 위해 각 차원에 대해 리커트 척도를 적용하여 수치 값을 텍스트 서술적 결과와 매핑함
- 리커트 척도: 개인, 대상, 관념, 현상 등에 대한 개인의 태도나 성향의 강도를 측정하는 기법
Value system for Desire Evaluation
- 정량적 가치 추론, 질적 가치 설명, 가치 업데이트 세 가지 작업 수행
- 정량적 가치 추론: 모든 내재적 가치에 대한 감쇠 매커니즘을 포함하여 욕구의 변동성을 모델링함
- 질적 가치 설명: 수치 값을 의미 있는 텍스트 욕구로 변환 → 에이전트가 현재 욕구 상태를 이해하고 적절한 행동을 생성하는 데 활용
- 가치 업데이트: 욕구 기반 플래너가 행동을 생성하고 환경에 대한 observation 을 수집한 뒤 가치를 업데이트함 → 이후 욕구 구성 요소의 내재적 수치값을 업데이트함
Desire-driven Planner
- 가치 시스템이 제공하는 현재 욕구 상태 정보를 처리하고, 기억 구성 요소로부터 과거의 기억을 통합하여 에이전트의 다음 행동을 결정하게 됨. 행동 제안, 행동 평가, 행동 선택 세 가지 핵심 절차로 나뉨
- 행동 제안: 욕구에 긍정적인 영향을 미칠 수 있는 N 개의 후보 활동을 생성하도록 프롬프팅하는 단계
- 행동 평가: 각 활동과 에이전트가 경험할 결과적인 욕구 상태를 상상하여 평가하는 단계
- 행동 선택: 각 행동에 의한 예측된 욕구 상태를 비교, 에이전트의 내재적 욕구를 가장 잘 충족시킬 것으로 에상되는 활동 선택하는 단계
Simulator
- Concordia를 베이스로 하는 Text 기반 일상 활동 시뮬레이터(Text Based daily activity simulator) 구현
- Concordia 라이브러리에서 목표 및 계획 관리, 시간 보고, 메모리 저장 및 검색 등과 같은 특정 역할을 수행하는 풍부한 구성 요소들을 제공
- DeepMind Concordia
- Concordia 에서 다음 두 가지를 업데이트함
- 환경 일관성 강화
- 명시적인 절차와 프롬프트를 통해 환경 일관성을 강화하여 에이전트가 환경 내에 존재하는 항목하고만 상호작용하도록 보장함으로써 사실성(realism)을 유지
- 평가 및 시각화를 위한 강력한 방법 제공
- 단일 단계의 행동과 전체 활동 시퀀스의 일관성(coherence) 및 그럴듯함(plausibility)을 평가할 수 있는 강력한 방법들을 제공
- 환경 일관성 강화
ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings
Objective
- 에이전트에게 특정 물품을 찾아달라고 요청하는 문제인 ObjectNav(객체 목표 네비게이션)는 객체의 이름이 주어지면 3D 환경을 탐색하여 해당 객체를 찾아내는 것을 목표로 함
- Habitat challenge: Meta, Habitat 3.0
- 지금까지의 ObjectNav 연구는 Closed world, 즉 사전에 미리 정의된 객체에 대해서만 찾는 방식이라는 제한적인 조건에서 이뤄짐
- Open world, 즉 사전에 정의된 객체에 구애받지 않고 제로샷으로 Object 를 Navigation 하는 에이전트를 만들어보자
ObjectNav
- ObjectNav 테스크는 에이전트를 조작하여 특정 물체가 위치해 있는 장소로 이동한 뒤, 해당 물체를 바라본 채로 STOP 액션을 하도록 만드는 것
- ZSON 의 목표는 학습 시에도 보지 못한 카테고리의 물체에 대해서도 Agent 가 환경 내에서 찾아내도록 하는 것임
- 이를 위해서 CLIP 의 구조적인 특성을 활용함
CLIP
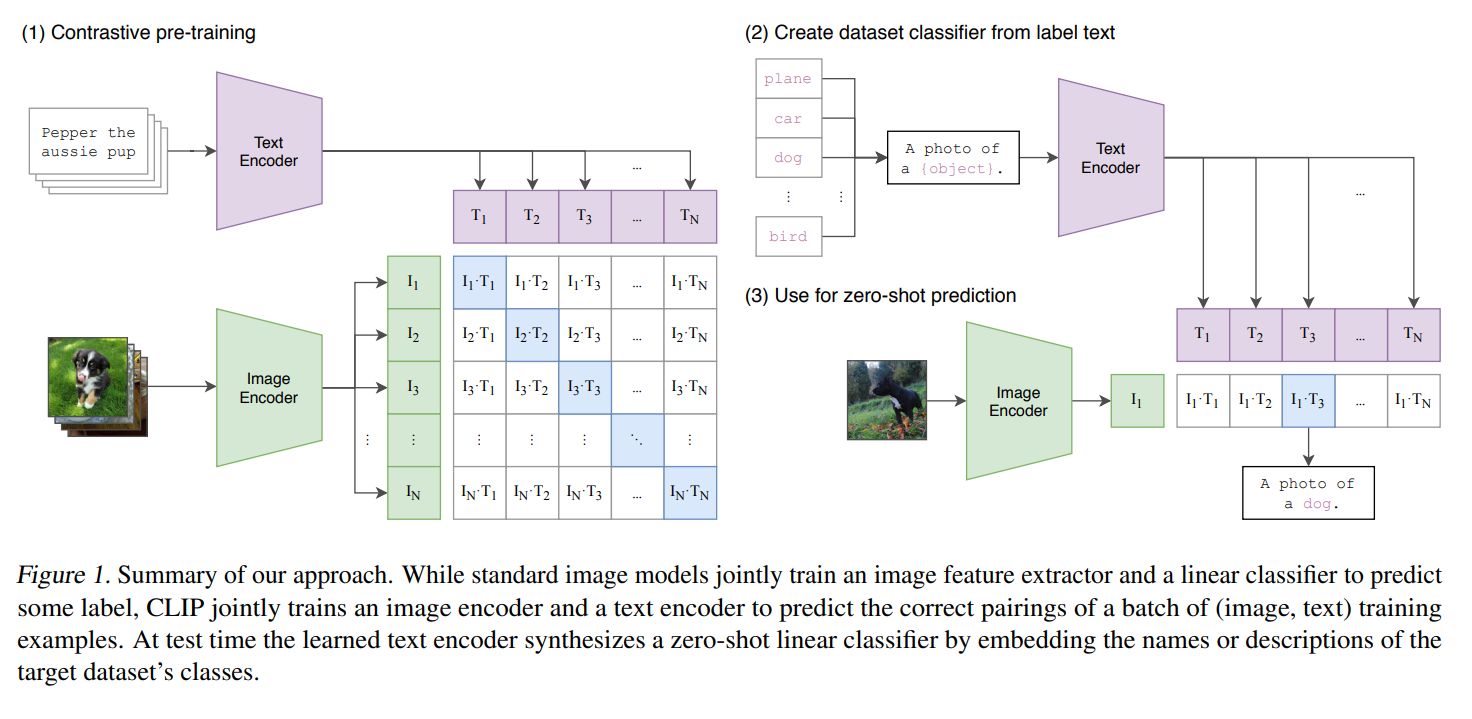
- CLIP 은 이미지와 텍스트를 공유 임베딩 공간으로 매핑하도록 학습된 모델임, 여기서는 CLIP을 이미지 목표와 객체 목표를 네비게이션 대상을 나타내는 semantic-goal 로 변환하는 인코더로 사용함
- CLIP 의 가장 큰 특징 중 하나는 어떤 Simantic 에 대한 이미지와 텍스트를 Visionlinguistic embedding space 상에서 비슷하게 위치하도록 인코딩할 수 있다는 것임
- 이를 활용하면 학습 시에 특정 이미지를 Semantic Goal 로 주입하여 그것을 찾도록 학습시키면 평가 시에는 모델이 CLIP 의 Simentic 추론 능력을 활용하여 학습 시에 보지 못한 물체에 대해서도 찾는 능력을 가질 수 있을 것으로 봄
SemanticNav
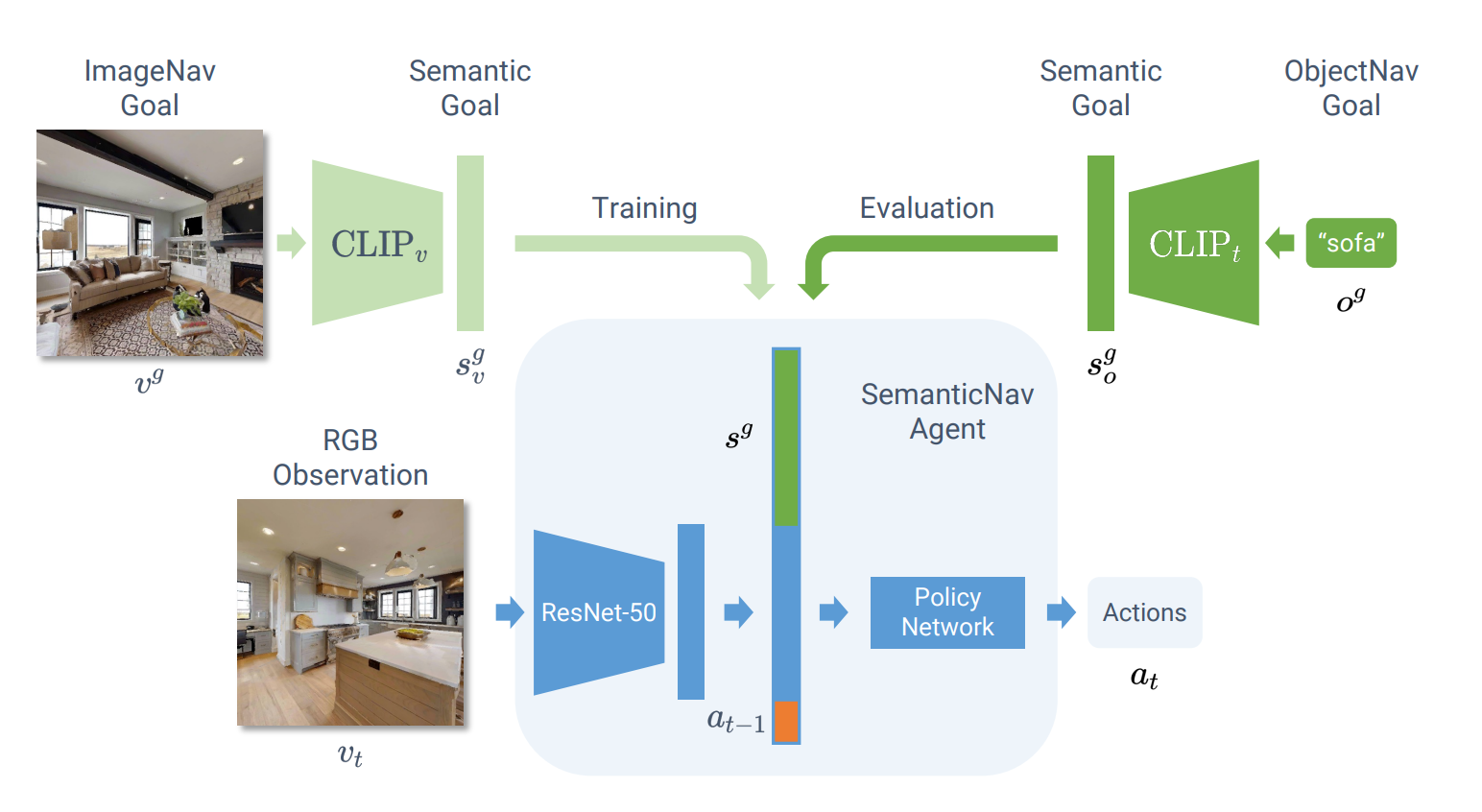
- Resnet-50 인코딩 결과 + Semantic Goal + 과거 action 을 입력으로 다음 action 을 결정하는 Policy network 학습
- Resnet 인코더는 OVRL 에서 제시된 사전 훈련 방식을 따라 자가 지도 학습(DINO)를 사용하여 OSD(Omnidata Starter Dataset) 에서 PreTraining
- Policy Network 는 2계층 LSTM 으로 구성
Training
- 강화학습(DD-PPO)을 사용하여 SemanticNav 에이전트를 트레이닝함
- 두 가지 데이터 어그맨테이션 방법(Color jitter, Random Translation) 적용(OVRL에서 차용)
- Al-Halah 에 의해 제안된 Reward Function 을 사용
- : 목표의 1 미터 내에서 stop 하면 5
- : 목표의 1 미터 내에서 25도 각도 이내로 목표를 바라본 채로 stop 하면 5
- : 목표까지의 거리에 따른 보상
- : 목표와 에이전트가 바라보는 시선의 각도에 따른 보상
- : 빠른 탐색을 장려하기 위한 -0.01
- 800개의 HM3D 훈련 환경을 사용하여 SemanticNav 에이전트 훈련을 위한 데이터셋 생성
- 9000개의 ImageNav 에피소드를 샘플링, 경로 길이에 따라 3가지 난이도로 동일하게 분할
- 총 800 * 9000 = 720만 개의 네비게이션 에피소드 생성
- CLIP의 ResNet-50 으로 인코딩하여 1024 차원의 임베딩으로 만듦(semantic goal embedding)
Evaluation
- 하나의 ImageNav 와 세 개의 ObjectNav 데이터셋에서 성능을 측정함. 이들은 모두 시뮬레이션으로 상호작용 결과가 메트릭으로 계산됨
- ImageNav (Gibson), ObjectNav (Gibson), ObjectNav (HM3D), ObjectNav (MP3D) 등을 사용함.
- Metrics
- SR(Success Rate, 성공률): 에이전트가 목표물의 1m 이내에서 STOP 을 호출한 비율
- SPL(Success Rate weighted by normalized inverse Path Length, 정규화된 역 경로 길이 가중 성공률): 성공한 에피소드에 대해 에이전트가 목표에 도달하기 위해 이동한 실제 경로 길이와 최단 경로 길이를 비교하여 스코어링, 탐색 경로의 효율성을 평가
Idea
- 요약해보면, CLIP 을 통한 입력이 training 과 evaluation 에 서로 다름. training 에서는 CLIP-v 를 사용하여 이미지를 입력 받고, evaluation 시에는 CLIP-t 를 사용하여 텍스트를 입력 받음. 이는 모델의 목표가 Open-world, 즉 학습에 사용되지 못한 객체도 찾을 수 있도록 하기 위함임. 즉 학습 시에는 이미지를 입력 받아 해당 이미지를 찾도록 하여 ‘찾는 행동’을 할 수 있도록 학습하는 데에 초점을 맞춤. 반면 Evaluation 시에는 사람의 다양한 입력에 대응하기 위해 자연어로 입력을 받도록 함. CLIP 은 이미지와 자연어를 동일한 공간에 매핑할 수 있으므로 이러한 점에서 장점이 있음
- CLIP 복습하기
- OVRL 알아보기
- OSD(Omnidata Starter Dataset) 알아보기
- DD-PPO 확인해보기
- HM3D, MP3D, Gibson 과 같은 시뮬레이터 확인해보기