- Published on
[Attention] Neural Machine Translation by Jointly Learning to Align and Translate
- Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio
- 2014
- 논문 링크
세 줄 요약
- RNN Encoder-Decoder 구조는 sequence의 길이가 길어지면 길어질수록 context vector에 모든 정보를 담지 못하는 문제를 가지고 있다. 이를 해결하기 위한 방법으로 Attention Mechanism을 제시한다.
- Decoder의 이전 hidden state 를 Encoder의 모든 hidden state 와 비교하여 유사도가 높은 hidden state가 context vector에 보다 많이 반영될 수 있도록 한다. 이때 와 간의 유사도를 Attention Score라고 한다.
- Attention Score를 구하기 위해 가 아닌 를 사용하기도 한다. 본 논문의 방식을 Bahdanau Attention이라고 하고 를 사용하는 방식을 Loung Attention이라고 한다.
Fixed length vector
RNN Encoder-Decoder 구조는 딥러닝을 Sequence to Sequence 문제에 적용한 첫 번째 성공적인 사례로 꼽힌다. 그러나 RNN Encoder-Decoder는 문장의 길이가 길어지면 성능이 크게 떨어진다는 문제를 가지고 있었다. 직관적으로 보더라도 sequence의 길이에 상관 없이 동일한 크기의 벡터로 표현한다면 sequence의 길이가 길면 길수록 담아내지 못하는 정보의 양이 클 수 밖에 없을 것이다.
논문은 이러한 문제의식, 즉 fixed length vector가 RNN Encoder-Decoder 구조의 성능을 저해하는 병목이라는 점에서 출발하며 이를 해결하기 위해 인코더의 정보를 전달하는 새로운 방식인 어텐션을 제안한다.
Attention
어텐션은 위와 같은 문제를 피하기 위해 인코더에서 하나의 Context vector 만을 추출하지 않는다. 인코더의 매 time step에서 나오는 hidden state를 디코더에서 필요에 따라 적절하게 사용할 수 있도록 하는 것을 목표로 하며, 어텐션이라는 표현 또한 어떤 hidden state에 주의를 기울일 것인지 학습하겠다는 의미가 내포되어 있다고 할 수 있다.
기계번역의 예시를 들어 생각한다면 이러한 방법이 쉽게 이해가 된다. 예를 들어
나는 어제 사과를 먹었다.
라는 문장을
I ate an apple yesterday.
이라는 영어 문장으로 번역해본다고 하자.
매 time step에 단어 별로 입력이 주어진다면 apple을 출력하는 디코더의 4번째 time step에서는 인코더의 입력 중 다른 어떤 단어들보다 사과를이라는 단어에 집중해야 한다.
어텐션은 인코더의 모든 hidden state를 필요에 따라 적절히 합하여 디코더에게 전달한다. 따라서 디코더는 time step마다 다른 context vector를 전달받게 되어 매 time step에 보다 적응력 높게 대처할 수 있게 된다. 위의 경우에서라면 인코더의 세 번째 hidden state의 비율이 높게 구성된 context vector가 디코더에 전달되는 것이 바람직하다고 할 수 있다.
Encoder: Bidirectional RNN
어텐션 구조에서는 인코더의 마지막 hidden state만을 사용하는 것이 아니라 각 time step의 모든 hidden state를 사용한다. 그런데 이 경우 RNN Encoder Decoder 구조와 같이 순방향 hidden state 만으로 구성하게 되면 이른 시점의 hidden state에 들어있는 정보들은 초기의 몇몇 단어들의 특성만을 반영한다는 문제점이 있다.
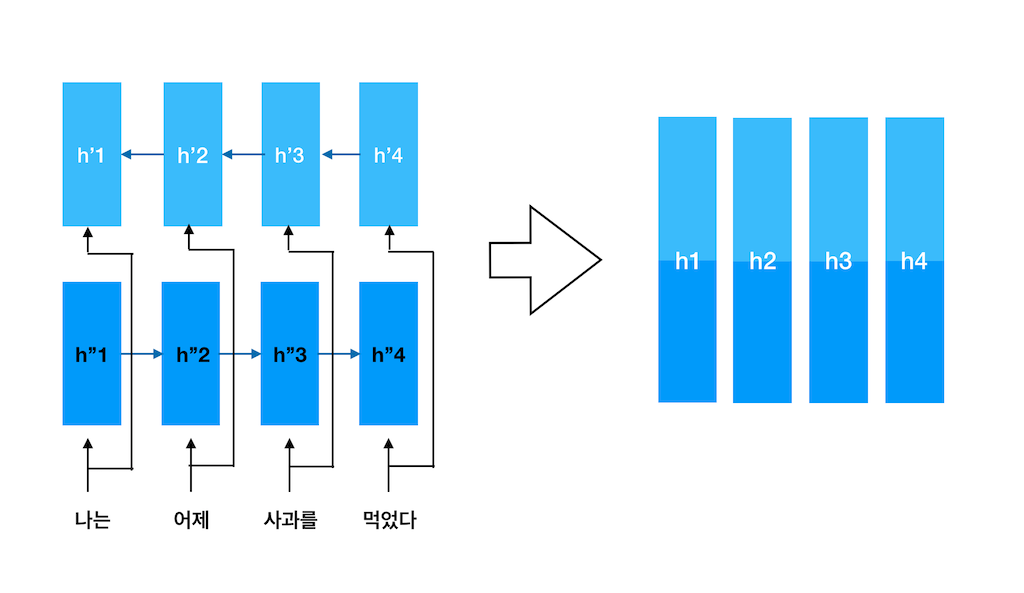
이를 해결하기 위해 어텐션에서는 Bidirectional RNN을 사용한다. 이름대로 두 방향, 즉 순방향과 역방향 모두에 대해 각각의 RNN 네트워크를 두어 hidden state를 구한 뒤 이를 concat한 값을 hidden state로 사용하는 방법이다. 이를 통해 모든 hidden state는 sequence 전체에 대한 정보를 가지게 되고, 동시에 앞 뒤로 가까운 값들의 영향을 보다 많이 받아 상대적인 위치에 따른 hidden state별 집중도가 다르게 나오게 된다.
Decoder: Attention Mechanism
RNN Encoder-Decoder 구조에서는 디코더의 hidden state 가 다음과 같이 계산되었다.
어텐션 구조에서는 다음과 같이 에서 로 변경되었다.
즉 디코더의 매 시점 에서 사용되는 contect vector 의 값이 다르다는 것이 디코더의 관점에서 가장 큰 차이점이라고 할 수 있다.
Context Vector
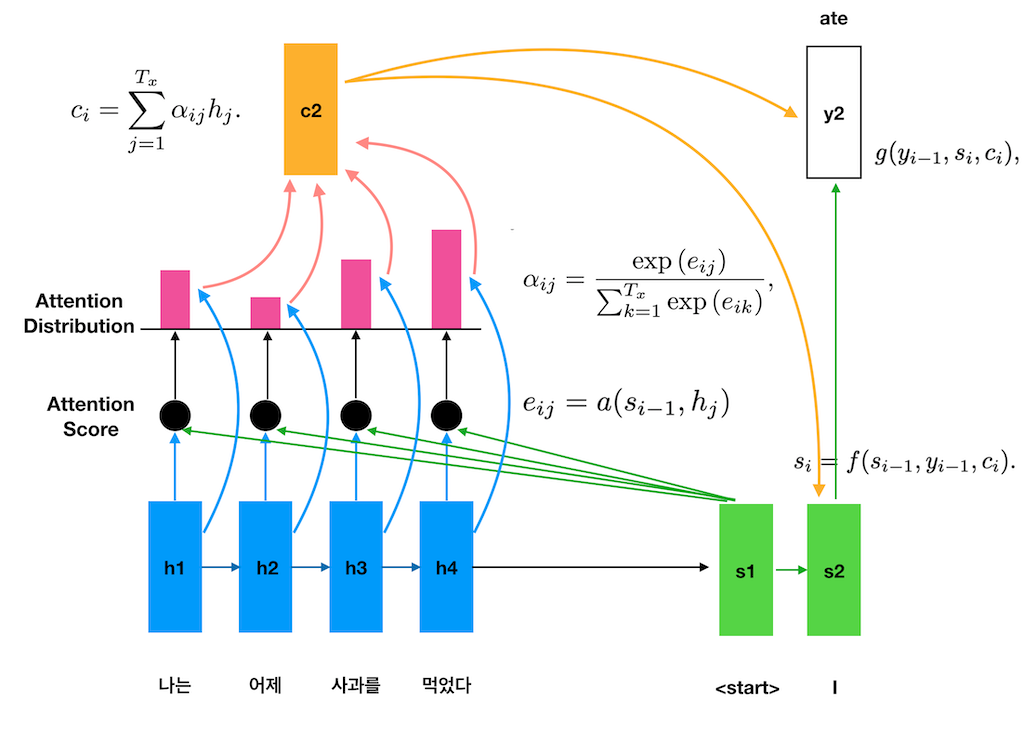
어텐션에서 Context Vector 가 도출되는 식은 다음과 같다.
여기서 의 값이 어떤 인코더 hidden state 가 중요한 정도를 의미한다. 의 값이 높으면 높을수록 해당 hidden state가 반영되는 정도가 높아지기 때문에 이를 Attention Distribution이라고 한다.
위의 식을 보게 되면 Attention Distribution이 어떤 값 의 softmax 값이라는 것을 알 수 있다. 의 값이 바로 어떤 hidden state가 중요한 정도를 나타내는 Attention Score이다. 이를 구하는 식은 아래와 같다.
Attention Score를 구할 때 사용되는 함수 a는 두 개의 vector 과 간의 유사도를 계산하는 것이라고 할 수 있다. 이와 관련하여 논문에서는 디코더의 이전 hidden state 의 관점에서 인코더의 hidden state의 중요성을 판단하고 그에 따라 next hidden state , 나아가 출력값인 를 결정하는 것이라고 표현한다.
Attention Architecture
Alignment Model
Attention Score를 구하는 함수를 논문에서는 Alignment Model이라고 표현한다. Alignment Model은 매 디코더 출력 마다 모든 인코더 hidden state에 대해 연산을 수행해야 한다. 따라서 한 sequence를 처리하는데 연산 횟수는 입력 sequence의 길이 X 출력 sequence의 길이가 된다. 연산량을 줄이기 위해 논문에서는 Alignment Model을 다음과 같이 처리할 것을 제시한다.
위의 식에서 는 디코더의 time step 에 구애받지 않기 때문에 전체 sequence에 대해 반복적으로 사용할 수 있어 연산량이 줄어들 수 있다고 한다.
Attention Score with or
어텐션에 대해 찾아보면 Attention Score를 구하기 위해 사용하는 디코더의 hidden state가 인 경우도 있고, 을 사용하는 경우도 있다. 본 논문에서는 를 사용하는데 이러한 방식의 어텐션을 논문의 저자 이름을 따 Bahdanau Attention이라고 부른다. 참고로 를 사용하는 것은 조금 뒤에 나온 Loung Attention이라고 하는데, Loung Attention 논문에서는 를 사용하는 방법을 제시하고 나아가 다양한 score function을 시도한다.