- Published on
[Dyna-Q] Integrating Planning for Task-Completion Dialogue Policy Learning
논문 제목 : Integrating Planning for Task-Completion Dialogue Policy Learning
- Baolin Peng, Xiujun Li, Jianfeng Gao, Jingjing Liu, Kam-Fai Wong, Shang-Yu Su
- 2018
- 논문 링크
Summary
- 대화 시스템과 같은 언어 모델은 시뮬레이터로 만들어 강화학습 알고리즘을 학습시키기에는 적합하지 않다.
- Deep Dyna-Q에서는 실제 사용자를 대상으로 직접 Policy를 업데이트하면서 데이터의 효율성을 높이기 위해 사용자를 시뮬레이팅하는 World Model을 Agent 내부에서 Policy와 함께 학습시키고, 이를 다시 Policy를 업데이트 하기 위해 사용한다.
- World Model의 성능이 좋아 시뮬레이팅의 정확도가 높아진다면 한 번에 여러 Step을 예측하도록 해 학습 속도를 높일 수 있다.
Making Dialogue System with RL
MDP(Markov Decision Process)에 맞게 수식화를 할 수 있다면 강화학습을 적용하여 문제를 푸는 것이 가능하다. 논문에서는 어떤 Task를 완수하는 내용의 대화(Task Completion Dialogue)를 MDP로 보고 강화학습 알고리즘으로 해결하고자 시도하는데, 구체적인 예시는 다음과 같다.

위 이미지는 DQN과 논문에서 제시하고 있는 알고리즘인 Deep Dyna Q(DDQ)의 대화 결과를 비교해서 보여주고 있다. 이미지의 맨 위에 나와있는 것을 사용자의 목적(Goal)으로 보고 이에 맞춰 Agent가 예약을 진행해주는 Task를 수행하는 것이다. 당연하게도 DQN은 잘 수행하지 못하지만 DDQ는 빠르게 원하는 목적을 달성하고 대화를 종료하는 것을 확인할 수 있다.
강화학습은 기본적으로 Agent가 Environment와 상호작용하면서 Reward를 극대화하는 방법을 찾는 알고리즘이다. 이를 위해서는 당연히 많은 양의 상호작용이 필요한데 현실에서는 어려운 경우가 많다. 논문에서 다루고 있는 Dialogue System만 하더라도 실제 사람과 수백 수천 번 대화를 진행하는 것은 많은 비용을 요구한다. 이와 같은 현실적인 문제 때문에 강화학습에서는 현실을 모사한 시뮬레이터를 만들고 그에 맞춰 학습을 진행한다. 실제로 강화학습을 적용하여 Dialogue System을 만들려고 한 많은 시도들이 우선 시뮬레이터에서 학습시키고, 실제 사람과의 상호작용을 통해 조금 더 성능을 높이는 방식으로 이뤄져 왔다고 한다.
하지만 언어 모델의 경우 시뮬레이터를 사용하는 것은 다음과 같은 문제를 가지고 있다.
- 시뮬레이터가 실제 언어의 복잡성을 잘 표현하지 못한다.
- 시뮬레이터의 디자인에 따라 학습의 질이 크게 달라진다.
- 시뮬레이터의 성능을 비교 평가할 기준이 존재하지 않는다.
논문에서 제시하고 있는 DDQ는 이러한 이유로 시뮬레이터를 사용하지 않는다. 대신 적은 수의 실제 사용자와의 대화를 보다 효율적으로 학습하도록 하기 위해 Model-Based 접근법을 사용한다.
Deep Dyna Q
Dyna Q 알고리즘 자체는 1990년 Sutton이 제시한 방법으로 강화학습의 고전적인 방법론 중 하나라고 할 수 있고, Deep Dyna Q는 말 그대로 Deep Learning을 사용하여 Dyna Q를 구현한 것이다. Dyna Q의 가장 큰 특징 중 하나는 실제 환경으로부터 직접 얻은 정보 뿐만 아니라 Planning 정보를 함께 사용하여 Policy를 업데이트 한다는 것이다. 그리고 이러한 Planning은 환경을 시뮬레이팅하여 유사하게 동작하는 World Model을 통해 구하게 된다. 이러한 점에서 DDQ에서는 Policy 뿐만 아니라 World Model에 대해서도 학습을 진행한다.
Components of DDQ
DDQ은 세부적으로 다음 5가지 Component로 구성된다.
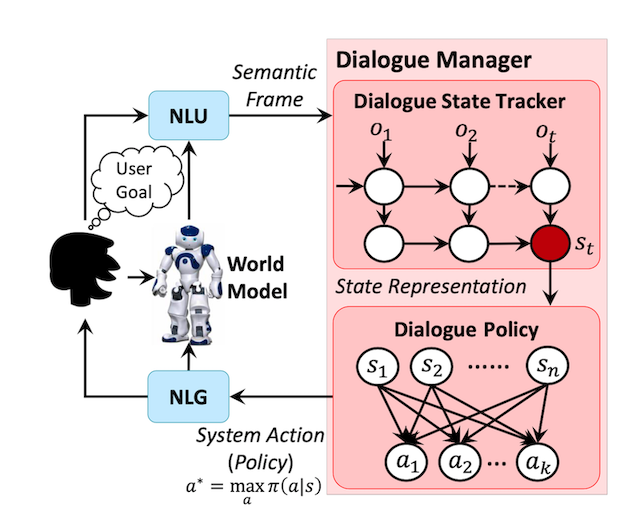
- NLU(Natural Language Understanding): 사용자의 자연어에서 의미를 추출하는 모듈
- State Tracker: 대화가 어떠한 상태인지, 어디까지 진행되었는지 파악하는 모듈
- Dialogue Policy: Action을 결정하는 모듈
- NLG(Natural Language Generation): Action을 자연어로 바꾸어주는 모듈
- World Model: 사용자의 Action과 Reward를 만들어내는 시뮬레이팅 모듈
Dialogue Policy의 알고리즘으로는 DQN을 사용했다고 한다.
How to Train DDQ
DDQ는 Policy 뿐만 아니라 World Model이 있기 때문에 단순히 사용자에서 추출한 정보를 바탕으로 Policy를 업데이트하는 기본적인 방법 외에도 다른 학습 알고리즘이 존재한다. 구체적으로는 아래 세 가지로 나누어 볼 수 있다.
1) Direct Reinforcement Learning
Direct Reinforcement Learning이란 Direct라는 표현에서도 짐작할 수 있듯이 사용자와의 직접적인 상호작용을 통해 Dialogue Policy를 업데이트하는 과정을 의미한다. 위에서 언급한대로 Dialogue Policy로는 DQN을 사용한다고 했는데 업데이트 또한 일반적인 DQN의 업데이트 방식을 따르고 있다. 따라서 업데이트를 위해 Replay Buffer 에 Transaction을 쌓게 되며 Exploration을 위해 -Greedy를 사용한다. Gradient는 다음과 같이 구해진다. 여기서 은 Target Value Function이다.
참고로 의 첨자에서 알 수 있듯이 에는 실제 사용자와의 Transaction만이 저장되고, World Model에 의해 모사되어 만들어진 Transaction은 에 따로 저장하게 된다.
2) Planning
Planning Process란 World Model에서 만들어 낸 경험을 사용하여 Dialogue Policy에 대한 학습을 진행하는 것을 말한다. 이때 중요한 하이퍼 파라미터로 Planning Step 가 있는데 쉽게 말해 몇 스텝 뒤 까지 예측할 것인가를 결정하는 파라미터라고 할 수 있다. 만약 World Model의 성능이 좋다면 가 커지더라도 문제가 없을 것이고, 이렇게 되면 많은 Transaction을 빠르게 쌓을 수 있어 보다 빠른 학습이 가능해진다. 위에서 언급한대로 이렇게 만들어진 Transaction은 에 저장되어 별도로 관리된다.
World Model은 로 표현할 수 있으며, State와 Dialogue Policy가 결정한 Action에 대한 정보를 입력 받으면 사용자가 했을 법한 Action 와 Reward 그리고 Done_bool을 출력하게 된다. 이를 위해 World Model은 아래 식과 같이 구성되며, 구조는 그림과 같다.
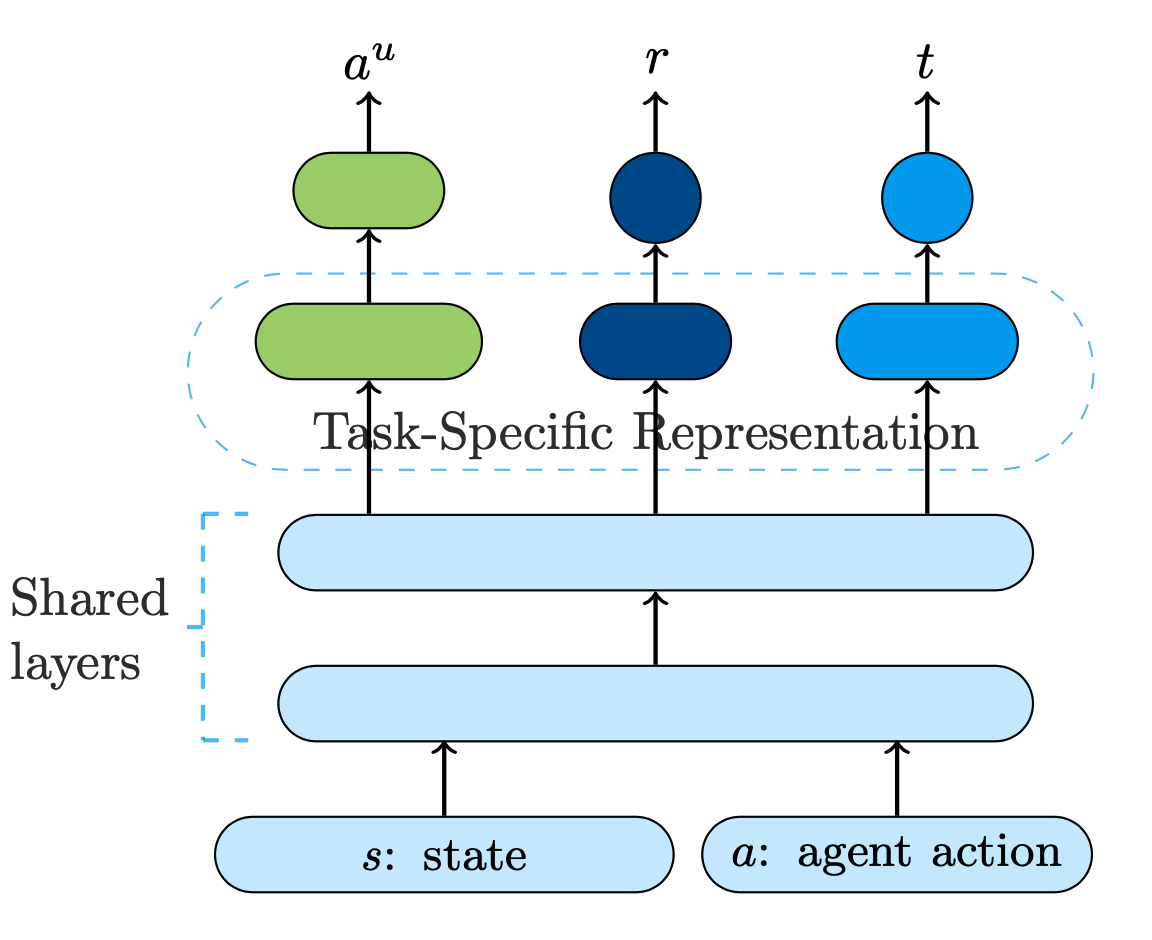 \eqalign{ &h = \text{tanh}(W_h(s,a) + b_h)\\ &r = W_r h + b_r\\ &a^u = \text{softmax}(W_a h + b_a)\\ &t = \text{sigmoid}(W_t h + b_t) }
\eqalign{ &h = \text{tanh}(W_h(s,a) + b_h)\\ &r = W_r h + b_r\\ &a^u = \text{softmax}(W_a h + b_a)\\ &t = \text{sigmoid}(W_t h + b_t) }Planning과 관련하여 특이한 점이 있다면 어떤 Transaction을 생성할 것인지 사용자 목표(Goal)을 전달하고 그에 맞춰 시뮬레이팅 한다는 것이다.
Goal은 다음과 같이 Contraint와 Request로 구성되며, 시뮬레이터는 이를 주어진 환경으로 보고 데이터를 생성하게 된다.
3) World Model Learning
로 정의되는 World Model은 실제 사용자를 최대한 모사하는 것을 목표로 한다. 따라서 즉, 실제 사용자와 Dialogue Policy 간의 상호작용에 대한 데이터가 담긴 Replay Buffer를 사용하여 학습하게 된다.
Algorithm of DDQ
DDQ의 학습 알고리즘은 아래와 같다. (1) Direct Reinforcement Learning (2) World Model Learning (3) Planning을 차례대로 진행하는 것을 확인할 수 있다.
