- Published on
Large Language Models for Information Retrieval A survey, Search Agent
Information Retrieval 서베이 논문 중 Search Agent 에 대한 내용만 간략히 정리
7. Search Agent
LLM 모델의 성능이 좋아지면서 스스로 정보를 탐색하고 해석하며 종합하는 능력을 갖춘 Search Agent 가 등장하기 시작했다. 이를 위해서는 다양한 기능들과 역할들을 필요에 따라 배치하여 연속된 작업들로 구성(파이프라인)할 수 있어야 하는데, 초기에는 사람이 웹사이트에서 정보를 얻는 방법을 그대로 모방하는 방식을 주로 시도하였다. 하지만 복잡한 사람의 행동을 모사하는 것은 여러가지 어려움이 있었고, 그 대신 LLM에게 자유를 주고 웹을 탐색할 수 있도록 하되, 피드백을 받아 개선하도록 하는 방법들이 더 좋은 성과를 보여주었다. 이에 최근에는 LLM 이 스스로 액션을 결정하고 그에 대한 피드백을 환경 또는 사람이 주는 방식으로 연구가 많이 진행되고 있다.
Search Agent 는 Agent 가 가지는 능동성의 수준에 따라 Static Agent 와 Dynamic Agent 두 가지로 나뉜다. Static Agent 는 미리 정해진 파이프라인에 따라 정보를 검색하고, 해석한 뒤 이를 종합하여 응답을 생성하는 Agent 를 말한다. 반면 Dynamic Agent 는 입력이 들어오면 이에 대한 응답을 하기 위해 필요한 작업은 무엇이 있는지 Agent 가 스스로 판단하여 수행한 뒤, 그 결과물들을 종합하여 응답을 생성하게 된다.
Static Agent
논문에서 언급하고 있는 Static Agent 의 주요 연구들로는 다음과 같은 것들이 있다.
LaMDA
- Transformer 기반 모델로, 대화형 응답 생성에 특화된 모델
- 사실적 근거 제공을 위해 외부 정보 검색을 적극 활용함 → 출처를 명시할 수 있음
SeeKeR
- 인터넷 검색 기능이 있음
- 검색 쿼리 생성 → 검색 결과에서 지식 추출 → 최종 응답 생성의 세 가지 단계로 구성됨
GopherCite
- 구글에서 관련있는 소스들을 검색하고, 이를 증거로 활용하여 LLM 모델의 응답을 검증함
WebAgent
- instruction decomposition, planning, action programming, HTML summarization 등을 포함한 일련의 작업들을 수행할 수 있음
- 웹을 탐색하며 다양한 출처의 정보들을 종합하여 결과물을 도출함
WebGLM
- 검색기, 부트스트랩 생성기, 인간 선호도 측정기 등을 활용하여 웹 기반의 질의 응답 제공
CoSearchAgent
- 다자간의 대화 속에서 사용자의 질의를 이해하고 처리함
- 불완전하고 모호한 질의를 재작성하고, 웹을 활용해 관련 정보들을 검색함
Dynamic Agent
Dynamic Agent 로는 다음 연구들이 있다. Dynamic Agent 에 대한 연구는 에이전트 설계, 프레임워크 및 시스템, 벤치마크 세 파트로 나누어 분석하는데, 에이전트 설계 관련 연구로는 다음 네 가지가 있다.
WebGPT
- 강화학습을 활용하여 GPT3이 검색 엔진을 자율적으로 활용할 수 있도록 훈련함
- 검색 쿼리 생성, 결과 스크롤링, 참조 인용 등의 특수 토큰을 활용함
ASH(Actor-Summarizer-Hierarchical) prompting
- WebShot 벤치마크에서 LLM의 성능을 크게 향상시키는 프롬프팅 방식
TRAD
- 순차적인 의사 결정이 필요한 테스트에서 LLM 모델의 성능을 개선함
- thought matching process 를 도입함
AutoWebGLM
- 기존 웹 브라우징 에이전트의 문제점
- 웹페이지 동작의 다양성, 긴 HTML 텍스트의 처리, 개방형 웹 의사결정 문제 등
- HTML 단순화 알고리즘, 강화학습, rejection sampling 등을 통해 웹 페이지의 이해력 증가, 브라우저 조작, 작업 분할 능력의 향상을 이끌어냄
프레임워크 및 시스템 연구는 다음 네 가지가 있으며,
KwaiAgents
- 다양한 기능을 가진 cognitive core 로서 LLM이 동작하게 됨
- 쿼리 이해, 외부 문서 참조, 내부 메모리 업데이트 및 검색, 하이브리드 검색-탐색 도구 실행 기능
WebVoyager
- 대형 멀티 모달 에이전트로 웹 사이트를 탐색하고 상호 작용할 수 있음
- 스크린 샷, 텍스트 입력 등과 같이 인간의 웹 탐색 행동을 모방함
IoA (Integration of Agents)
- 다양한 에이전트 간의 협업을 지원하는 프레임워크
AgentE
- 계층적 시스템(Planner Agent + Browser Navigation Agent)으로 역할 분리
- 유연한 DOM(Document Object Model) 변환 기법을 도입하여, 작업별 최적의 DOM 표현 선택 가능.
MindSearch
- WebPlanner: 사용자 질의를 원자적 하위 질문으로 분해하고 추론 과정 조정.
- WebSearcher: 계층적 정보 검색 수행, 대량의 웹페이지에서 정보 과부하를 관리하며 핵심 정보를 선별.
마지막으로 벤치마크 관련 연구는 다음 두 가지가 있다.
WebShop
- 온라인 쇼핑을 위한 확장 가능하고 인터랙티브한 웹 환경을 제공하는 벤치마크.
WebCanvas
- 동적이고 변화하는 온라인 환경에서 웹 에이전트의 성능을 평가하는 벤치마크.
- 정적인 웹 환경이 아닌 UI 및 콘텐츠의 빈번한 업데이트를 반영함
Limitations
Search Agent 연구의 한계로
- 정적 에이전트에 비해 동적 에이전트에 대한 연구가 다소 부족하다,
- 몇몇 에이전트의 경우 잘못된 정보를 검색하여 사용하거나 적절치 않은 출처를 가진 정보를 사용하는 문제가 있다,
- 편향적이거나 윤리적으로 적절치 못한 응답을 만들어내는 경우가 있다,
- 개인정보와 보안 문제를 일으킬 수 있다,
등을 제시하고 있다. Search Agent 는 웹 검색, 데이터베이스 접근 등, 단순한 Retriever에 비해 시스템에 더욱 많은 자율성을 부여한다는 점에서 그 과정과 결과물에 대해 보다 높은 기준이 적용될 필요가 있어 보인다.
[Static Agent] LaMDA: Language Models for Dialog Applications(Google)
문제 의식
- 단순 모델 크기의 증가와 학습량의 증가 만으로는 Safety 와 Factual Grounding 문제를 해결하기 어렵다.
해결 방안
- 기술적 → 파인 튜닝과 외부 지식 활용
- 안정성 → 모델이 유해하고 편향된 응답을 하지 않도록 제어 / human values 기반 안정성 평가 지표 활용
- 사실적 근거 → 외부 지식 소스를 활용하여 정확한 정보 제공 / groundedness metric 개발 및 도입
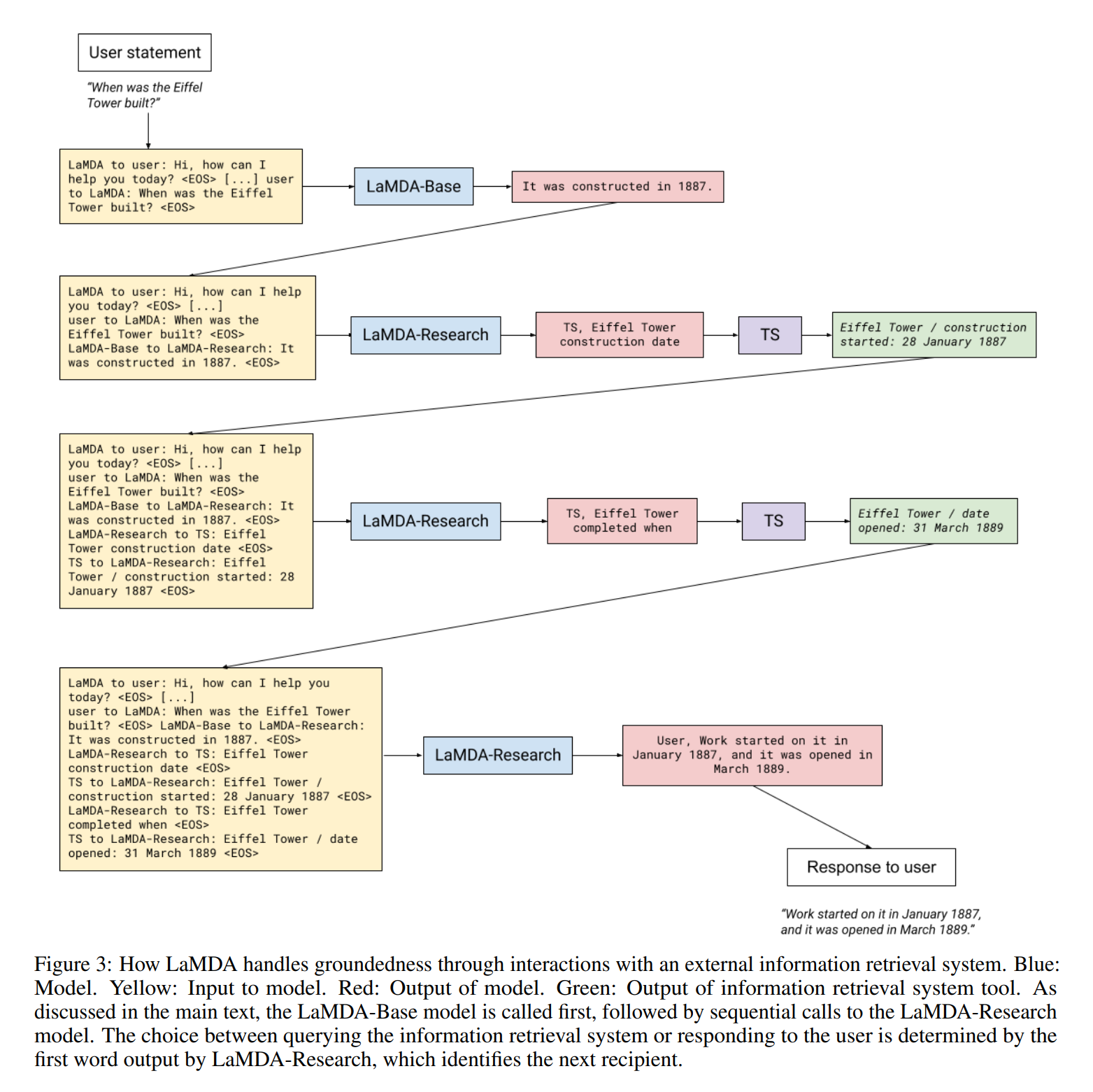
- 사용자가 쿼리 입력
- 프롬프트를 추가하여 베이스 모델(LaMDA-Base)에 전달하면, 그에 맞는 답을 생성함
- 생성된 답까지 프롬프트에 추가하여 리서치 모델(LaMDA-Resaerch)에 입력으로 전달함
- 리서치 모델은 (1) Retrieval system 에 관련 정보 검색 (2) User 에게 응답 두 가지 액션 중 하나를 선택함. 선택 결과는 출력의 첫 번째 토큰으로 나오게 됨
- User 에게 응답하는 토큰이 나올 때까지 이를 반복함.
- 최종적으로 응답할 것을 뜻하는 토큰이 나오면 유저에게 응답을 전달함.
[Dynamic Agent] WebGPT: Browser-assisted question-answering with human feedback(OpenAI)
문제 의식
- Long-form question-answering(LFQA) 문제에서는 언어모델의 성능이 제한적임
해결 방안
- document retrieval + fine-tuning for synthesis + human feedback
- 모델이 직접 웹 브라우저(Bing)에서 검색하여 정보를 수집할 수 있도록 함
- 모델은 검색, 링크 클릭, 스크롤, 뒤로 등과 같이 사람이 브라우저를 사용할 때 취할 수 있는 액션들을 선택할 수 있음
- 응답 액션이 선택되면 지금까지 수집된 자료들을 종합하여 최종적인 응답을 생성하게 됨

OpenAI 팀에서 개발한 text-based web-browsing environment

text-based web-browsing environment 에서 선택 가능한 Action 들