- Published on
[In-Context RALM] In-Context Retrieval-Augmented Language Models
Summary
- Token 단위 Generation 에 검색 결과를 달리하여 추론하는 In-Context RALM을 제안한다.
- 지금까지 생성된 Token 들을 대상으로 Retrieval 하고, 그 결과를 Concatnation 하여 LM 모델에 입력으로 전달한다.
- 컴퓨팅 자원 효율성 및 성능을 고려하여 Retrieval Strid, Retrieval Query Length 등을 하이퍼 파라미터로 추가했다.
RALM
RALM(Retrieval-Augmented Language Model) 이란 Language Model이 검색된 관련 문서를 활용하여 추론 결과를 생성하는 방법을 말한다. 기존의 LM 모델은 학습 시에 사용되지 않은 정보들을 활용하지 못하는데, 처음 보는 정보에 대해서도 그럴싸한 답을 내놓는 경우(Hallucination)가 있어 문제로 여겨져 왔다. RALM은 검색을 통해 사용자의 질문과 관련성이 높은 문서들을 찾고, 이를 생성에 적극 활용하도록 함으로써 이러한 문제를 해결하려하는 접근 방법이라 할 수 있다. RALM 을 활용하면 검색기 또는 검색 대상이 되는 데이터셋만 업데이트되면 LM 모델이 학습 시에 보지 못한 데이터에 대해서도 성능을 향상시킬 수 있다.
Retrieval, 즉 검색을 하고 이를 생성에 활용한다고 하면 RAG(Retrieval Augmented Generation)가 가장 먼저 떠오를 수 밖에 없다. RALM은 RAG를 포괄하는 개념이라고 할 수 있는데, RAG는 검색 결과가 되는 문서를 LM 모델 추론 전에 검색을 마치고, 이를 프롬프트에 입력으로 추가하여 전달하는 방식이지만 RALM 은 추론 과정 중간 중간에도 검색을 진행하고, 이를 활용하는 것까지 포함하기 때문이다.
논문에서는 Related Work 에서 RALM 연구에 대해 개괄적으로 다루고 있는데, 크게 두 가지로 분류한다.
Nearest-neighbor Language Models(kNN-LM)
검색된 가장 가까운 k개의 이웃(nearest neighbors)의 출력을 참조하여, 기존 LM의 확률 분포를 보정하는 방법이다. Khandelwal et al. (2020)에서 처음 제안되었다. 분류의 이름에서도 알 수 있듯이 유사도가 높은 문서를 검색하고, 이를 참조하여 기존 LM 의 확률 분포를 보정하는 방법이다.
다음 수식들은 Khandelwal et al. (2020) 논문에서 발췌하였는데, kNN으로 검색된 개의 검색 결과들에 따른 확률과 기존 LM 모델의 확률을 적절한 비율로 결합하여 다음 단어를 예측하는 데에 활용함을 확인할 수 있다.
Retrieval and Read Model
kNN-LM과 Retrieval and Read Model 의 가장 큰 차이점은 Document Selection 과 Document Reading 부분이 명확히 구분되어 있다는 점이다. RAG (Lewis et al., 2020), FiD (Izacard & Grave, 2021), REALM (Guu et al., 2020), RETRO (Borgeaud et al., 2022) 등이 이와 관련된 방법이라고 할 수 있다.
논문에서 제안하는 In-Context RALM은 이들 연구와 비교해 볼 때 다음 두 가지 지점에서 차이를 가진다고 한다.
- 언어 모델을 추가로 훈련하지 않고, 기존의 사전 훈련된(off-the-shelf) 언어 모델을 문서 읽기에 활용함
- 언어 모델의 성능을 향상시키기 위한 문서 선택 방법에 집중함
In-Context RALM
In-Context RALM 모델의 기본 수식은 다음과 같다.
여기서 는 를 입력으로 하여 찾은 검색 결과를, 는 string 와 를 Concat 한 것을 의미하므로, 쉽게 말해 다음 토큰 를 추론하기 위해 이전에 생성된 토큰들과 이들만을 활용한 검색 결과를 붙인 텍스트를 활용한다는 것이다.

제시된 이미지를 보면 보다 직관적으로 이해할 수 있다. 지금까지 생성된 단어 이 "World Cup 2022 was the last with 32 teams, before the increase to" 라고 할 때, 일반적인 생성 모델은 이 단어 시퀀스만 활용하여 다음 단어를 생성하게 되지만, In-Context RALM 은 이들을 Retriever 에 넣어 생성에 필요한 정보 "FIFA World Cup 2026 will expland to 48 teams"를 찾아 두 가지를 Concat 해서 생성하도록 한다. 이를 통해 언어 모델의 추가적인 학습 없이도 실시간 데이터와 같이 새로운 정보들도 잘 다룰 수 있다고 한다.
Design Choices
기본적인 In Context RALM 모델의 효율성을 높이기 위해 논문에서는 다음 두 가지를 적용해 보았다고 한다.
Retrieval Stride
첫 번째는 Retrieval Stride, 즉 얼마나 자주 검색을 수행할 것인지에 관한 것이다. 위의 In-Context RALM 기본 수식을 보면 를 추론하기 위해 를 활용한다. 즉, 매 token generation step 마다 검색을 진행하고, 그 결과를 반영토록 할 수 있다는 것이다.
하지만 이렇게 되면 생성 토큰의 갯수에 비례하여 검색를 수행하게 되고, 이는 곧 과도한 컴퓨팅 리소스를 의미한다. 이를 해소하기 위해매번 하지 않고, 일정 간격 - 토큰 - 을 두고 새로운 문서를 검색하는 방법을 제안하는데, 이 부분이 적용된 수식은 아래와 같다.
토큰을 생성하는 데 있어 이 고정되어 있음을 알 수 있다. 관련 실험에서 Retrieval Stride 를 길게 잡을수록 성능은 떨어지는 것을 확인하였고, 따라서 연산량과 성능의 트레이드 오프를 관찰할 수 있었다고 한다.
Retrieval Query Length
에서 알 수 있듯이 Retriever 는 지금까지 생성된 전체 Token을 입력으로 받는다. 하지만 새로운 다음 토큰을 추론하는 데에 지금까지 생성된 모든 토큰 정보는 필요하지 않을 수도 있다. 논문에서는 최근에 생성된 토큰들일 수록 직후 토큰을 생성하는 데에 보다 관련성이 높을 것으로 가정하고, 최근 생성 토큰들만 Retriever 에 넣도록 하였다. 여기서 이 query length 이다.
최종적으로 Retrieval Stride 와 Retrieval Query Length 가 모두 적용된 In-Context RALM 수식은 다음과 같다.
Retrieval Stride 와 Retrieval Query Length 두 가지를 함께 적용함에 있어 중요한 점 중 하나는, 두 가지 하이퍼 파라미터의 크기가 같은 경우, 즉 으로 설정하면 성능이 떨어진다는 것이다.
Experiment Settings
Dataset
실험에 사용한 데이터 셋은 다음 7가지이다.
- Language Modeling Dataset
- WikiText-103
- The Pile
- Stack Exchange
- FreeLaw
- Real News
- Open Domain QA
- Natural QA(NQ)
- Trivia QA
Model
언어 모델로는 GPT-2, GPT-Neo, OPT, LLaMA 등 Open Source로 쉽게 구할 수 있는 모델들을 사용하고 있으며, 각 모델의 크기 또한 다양하게 실험을 진행하여 모델 크기에 따른 성능 비교도 함께 확인하려 하고 있다.
Retriever & Reranker
Retriever 또한 Sparse, Dense 모두 사용하는 등 다양하게 실험을 진행하고 있는데, 다음과 같다.
- Sparse Retriever
- BM25
- Dense Retriever
- frozen BERT-base
- Contriever
- Spider
Reranker 의 경우 RoBERTa-Base 를 바탕으로 트레이닝하였다.
Experiment results
1. The Effectiveness of In-Context RALM with Off-the-Shelf Retrievers
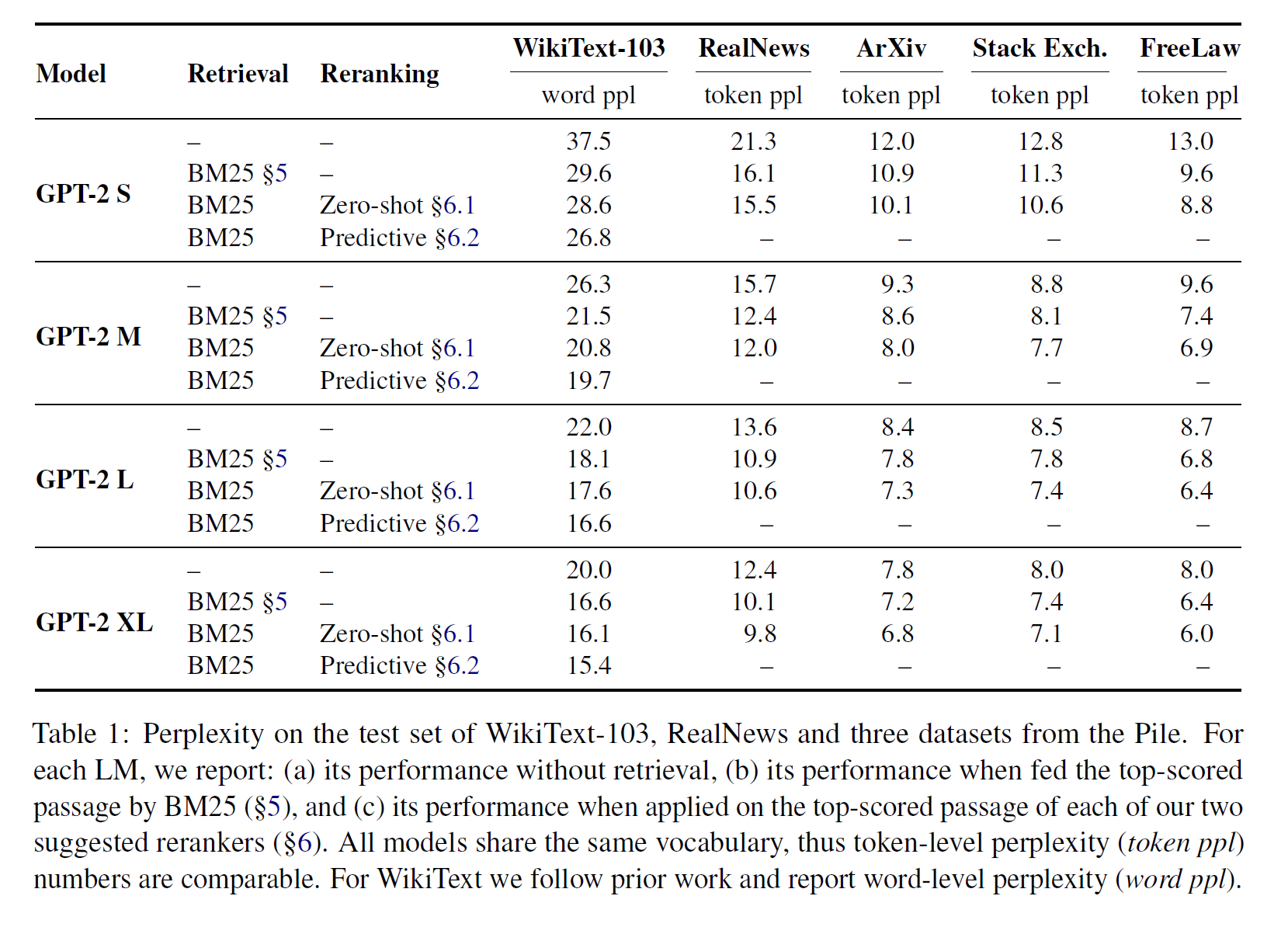
각 모델의 첫 번째 줄과 두 번째 줄의 실험 결과를 비교해보면 BM25와 이 비교적 간단한 Retriever 를 사용한 경우에도 In-Context RAML을 적용하면 성능이 높아질 수 있음을 확인하였다. 경우에 따라서는 In-Context RAML 을 적용하여 더 큰 모델의 성능을 앞지르기도 하였다.
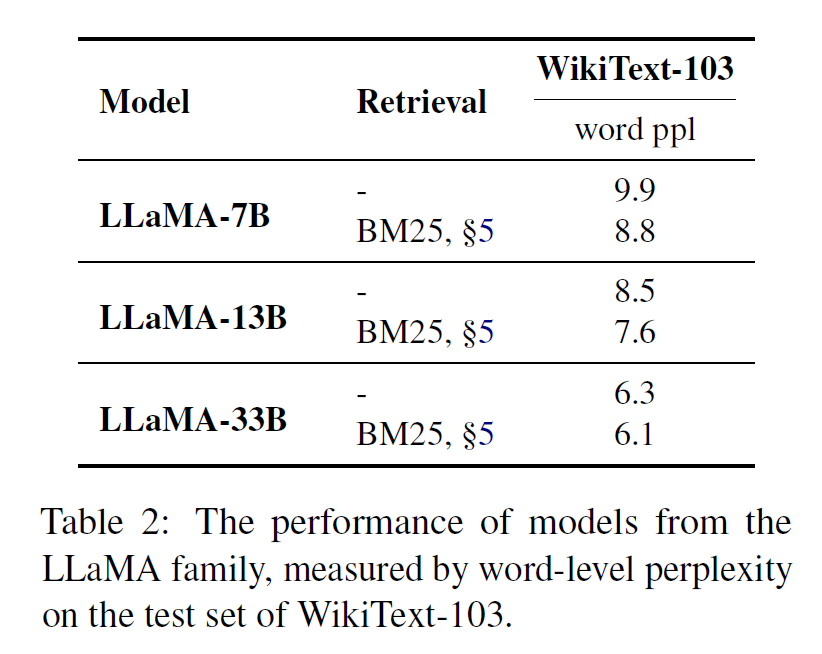
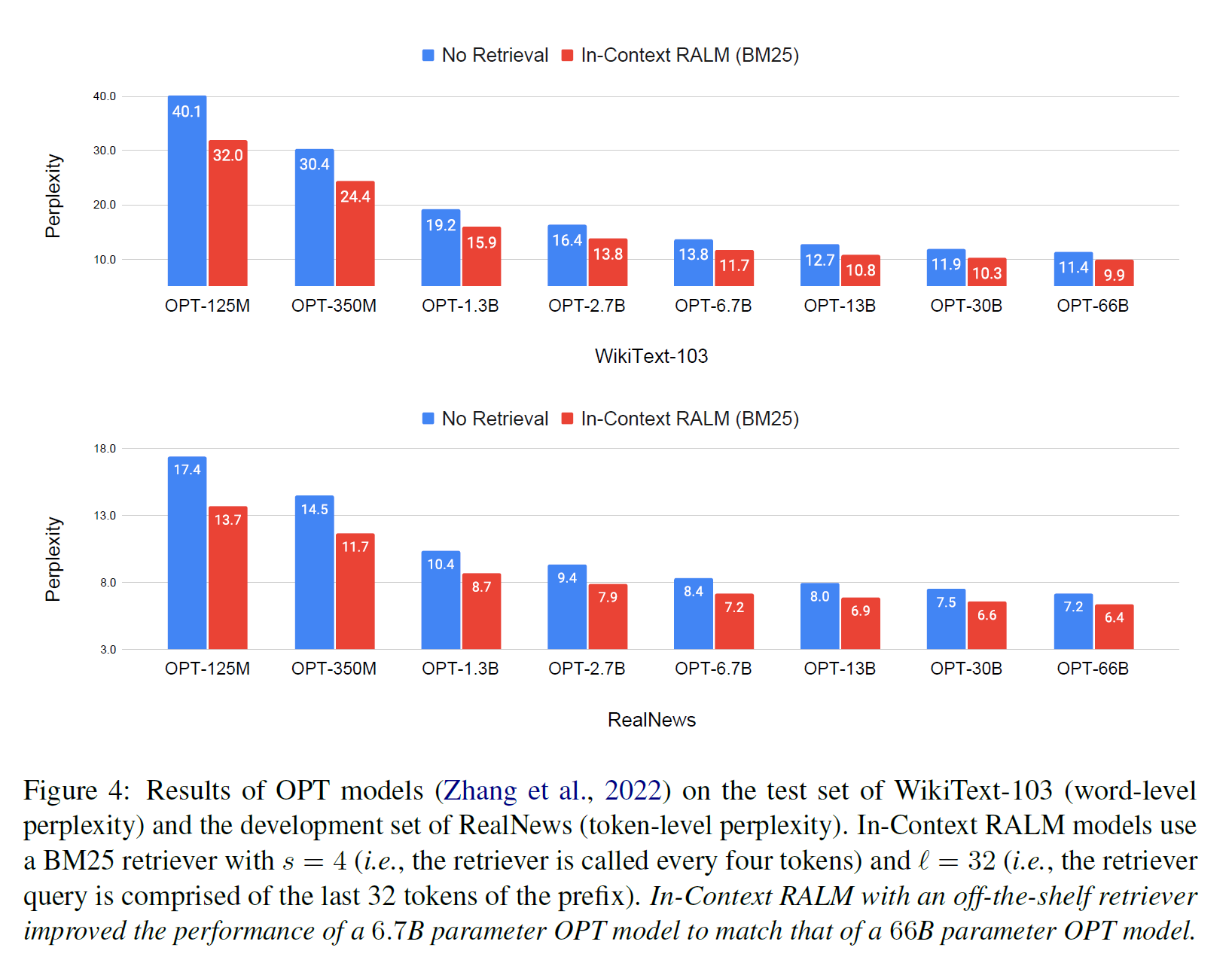
위 플롯과 표를 통해 다양한 크기의 LLaMA와 OPT 모델들들에 대해서도 유사한 실험 결과를 보여주었음을 알 수 있다.
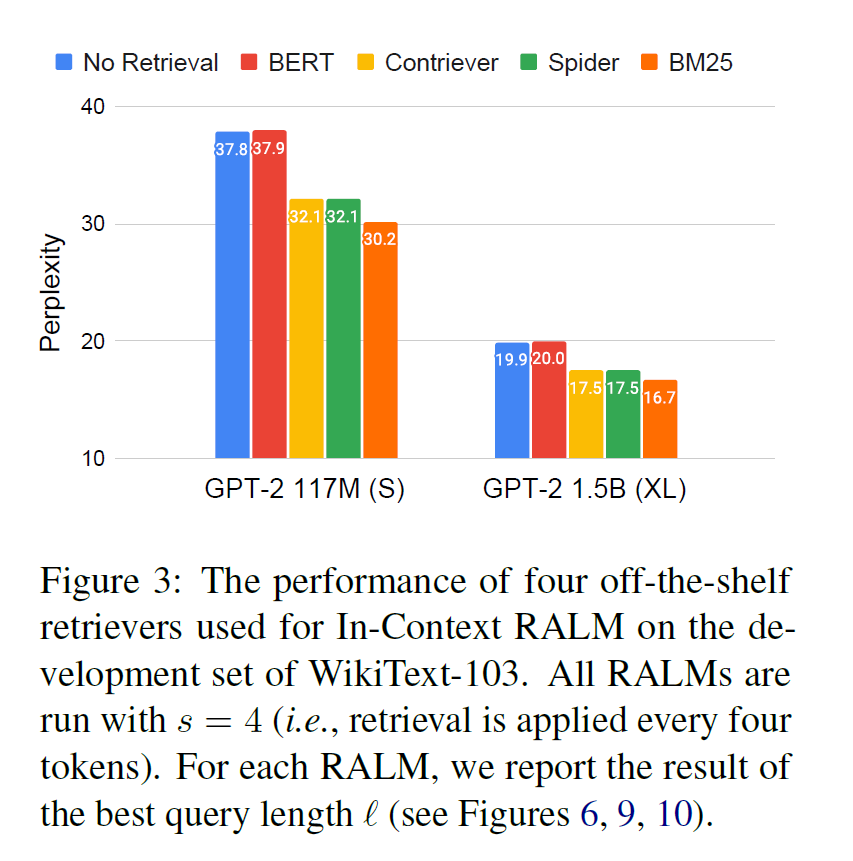
흥미로운 결과 중 하나는 Sparse Retriever 인 BM25를 적용했을 때 다른 Dense Retriever 보다 더 높은 성능을 보여주었다는 것이다. 이는 Zero-Shot 환경에서는 BM25가 다른 Dense Retriever 보다 더 나은 성능을 보여주었던 기존 연구(BEIR)들과 유사한 결과이며, 일반적으로 연산량도 더 적다는 측면에서 BM25를 Retriever로 선택하는 것이 매력적인 옵션이 될 수 있을 것으로 보인다.
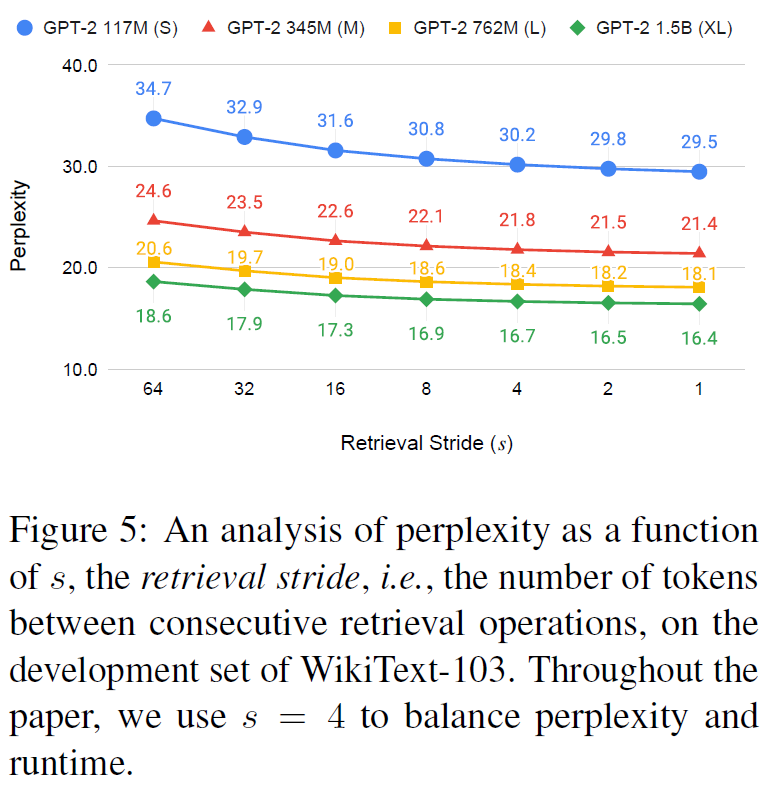
Retrieval Stride 의 크기에 따른 실험도 진행했는데, 쉽게 추측해볼 수 있듯 Stride 의 크기가 작을수록, 즉 검색을 더 자주할수록 성능이 좋아진다는 것을 알 수 있다. 이는 현재 문맥에 더욱 맞는 문서를 적극적으로 활용할 수 있기 때문으로 추측해 볼 수 있는데, Stride 가 작으면 작을수록 Retrieval 비용은 증가하므로 Trade-Off를 고려해야 할 필요가 있는 부분이다.
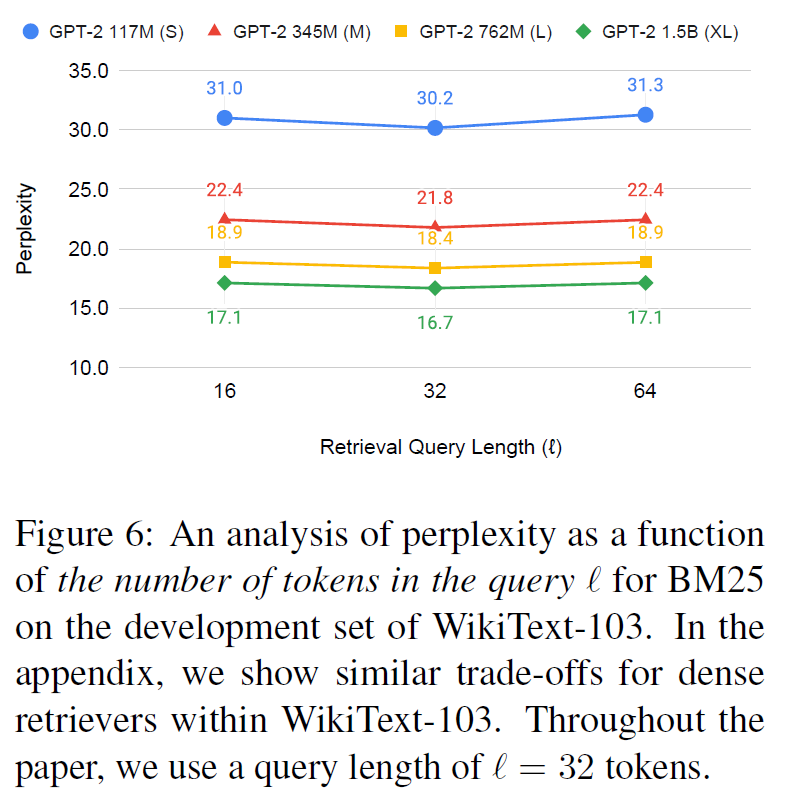
Query Length 에 대해서는 32 Toekn 정도로 잡는 것이 가장 좋았다(Sweet Spot)고 한다.
2. Improving In-Context RALM with LM-Oriented Reranking
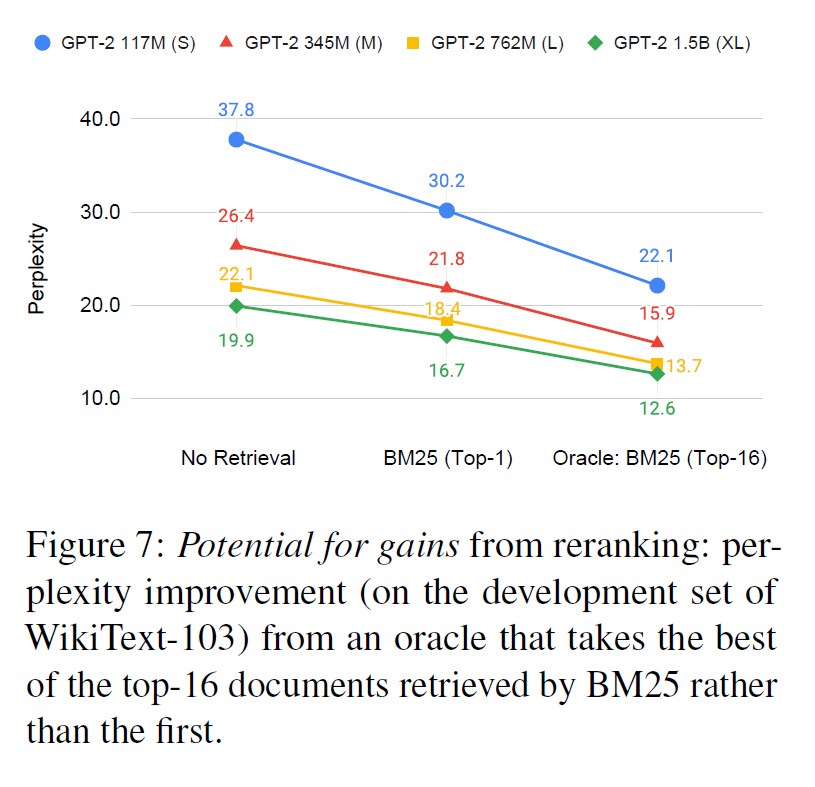
위 플롯은 Retriever 가 판단한 최상의 1개 문서를 사용하는 것보다 Top16 개의 문서 중 가장 최선의 것을 사용하면 더 좋은 성능을 보일 수 있음을 보여준다. 이를 통해 Retriever의 Reranker를 개선하는 것으로도 In-Context RALM의 성능이 높아질 수 있음을 짐작하게 되었고, 관련 실험들 또한 다수 진행했다고 한다.
LMs as Zero-Shot Rerankers
Reranker 의 목적은 Next Text 을 예측하는 데에 있어 가장 유용한 Document 를 찾아내는 것이다. In-Context RAML 에서는 Retrieval Stride와 Query Length를 고려하여 다음과 같이 가장 이상적인 문서 를 수식화 할 수 있다.
하지만 이는 곧바로 적용하기 어려운데, Test Time 에는 생성 중이므로 Next Text 를 알 수 없기 때문이다.
대신 가장 최근에 생성된 문맥들()을 예측하는 데에 도움이 되는 Document 를 찾는 것으로 변경하여 진행했다. 이는 이전 문맥에 잘 맞는 문서라면 다음에 나올 텍스트를 예측하는 데에도 도움이 될 것이라고 가정하는 것이라 할 수 있다.
이상적인 케이스 가 Retrieval Stride 개 만큼의 Next Token 들을 예측하는 것이라면 이를 근사한 최근에 생성된 개를 예측하는 것으로 변경했다고 할 수 있다. 이를 수식으로 나타내면 다음과 같다.
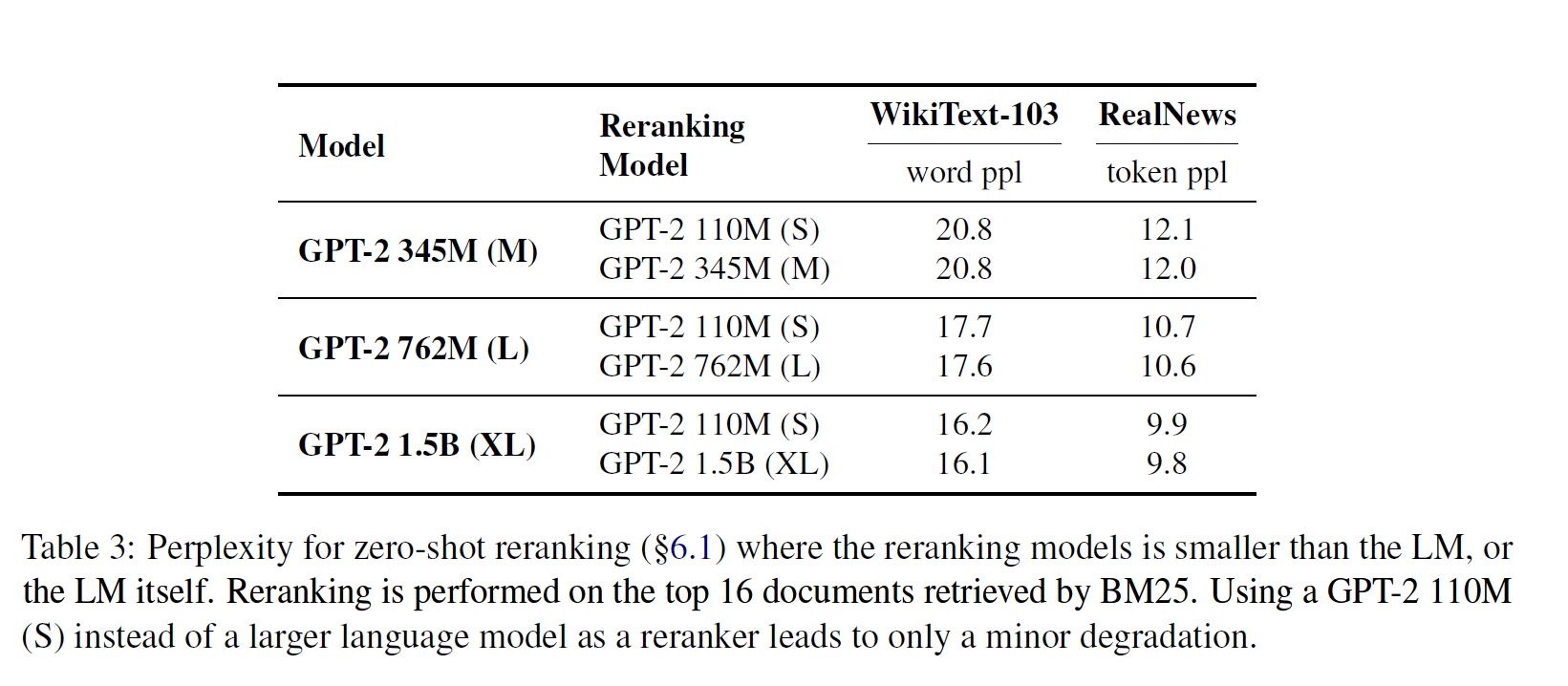
위의 실험 결과는 으로 설정하고 다양한 크기의 GPT-2에 Zero-Shot reranker 를 적용한 결과이다. 언어 모델과 Reranker 가 반드시 동일할 필요는 없으며, Reranker 의 크기에 성능이 크게 달라지는 것은 아니라는 것을 알 수 있다.
Training LM-dedicated Rerankers
BM25가 뽑은 Top K 문서들에 대한 Reranker를 직접 학습해보기도 하였다. 논문에서는 prediction을 도와준다는 의미에서 이를 Predictive Reranking 이라고 부른다.
어떤 문서가 유용한 정도는 위와 같이 표현할 수 있고,
를 찾는 것이 목표가 된다.
Loss function 은 다음과 같이 설정하고 학습을 진행했다.
위 표의 Zero-Shot, Predictive 실험 결과에서 Predictive Reranking 의 효용을 확인할 수 있다. 모든 경우에 있어 Predictive Reranking 을 적용한 경우 그렇지 않은 경우에 비해 성능이 개선되었다. 즉, Retriever에 대한 학습을 통해 더 나은 문서를 찾을 수 있게 되었다는 것이다. 이는 Doamin Specific Task에 있어 Retriever 의 추가 학습이 특히 유용할 수 있음을 의미한다.
In-Context RALM for Open-Domain Question Answering
LLaMA 모델을 사용하여 Open-Domain Question Anwsering 에서도 In-Context RALM 이 유용한지 확인하는 실험을 진행했다.
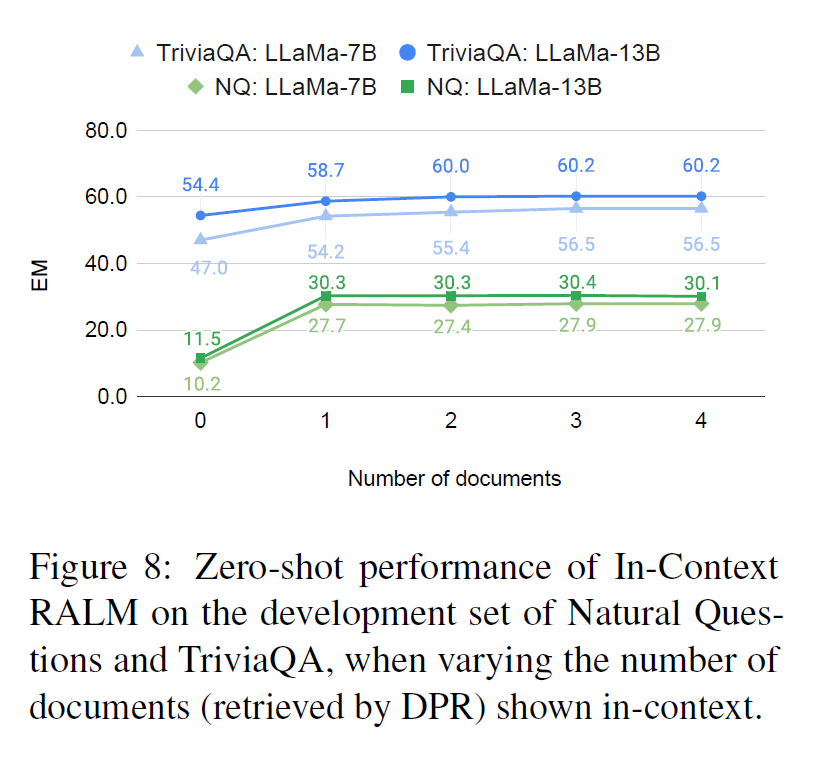
In-Context RALM을 사용하여 검색된 문서를 추가했더니 그렇지 않은 경우에 비해 성능이 대폭 향상됨을 확인할 수 있다. 문서의 갯수가 늘어나면 성능도 조금씩 좋아지나 큰 차이는 없어 보인다.
Reference
- Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., Lewis, M. and University, S. (n.d.). Published as a conference paper at ICLR 2020 GENERALIZATION THROUGH MEMORIZATION: NEAREST NEIGHBOR LANGUAGE MODELS.
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-T., Rocktäschel, T., Riedel, S., Kiela, D., Facebook and Research, A. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
- Izacard, G. and Grave, E. (2020). Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
- Guu, K., Lee, K., Tung, Z., Pasupat, P. and Chang, M.-W. (2020). REALM: Retrieval-Augmented Language Model Pre-Training.
- Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., Van Den Driessche, G., Lespiau, J.-B., Damoc, B., Clark, A., De, D., Casas, L., Guy, A., Menick, J., Ring, R., Hennigan, T., Huang, S., Maggiore, L., Jones, C. and Cassirer, A. (n.d.). Improving language models by retrieving from trillions of tokens