- Published on
[FACTSCORE] Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
Introduction
Long-Form Text Generation Task 에 대한 정확한 평가는 (1) 정확한 정보와 부정확한 정보가 혼재되어 있어 True/False 의 이진 판단이 어렵고 (2) 사람이 평가하도록 만드는 것은 비용과 시간이 많이 들기 때문에 쉽지 않은 문제이다. FACT SCORE는 이러한 문제를 해결하기 위한 방법을 제시한다.
Ideas
Atomic Fact
다양한 정보들이 혼재되어 있는 Long-Form Text는 진실 혹은 거짓과 같은 이진 판단이 가능한 원자적 사실(Atomic fact)들로 쪼갤 수 있다. 문장 단위로 쪼개는 연구들도 있었지만 문장 역시도 여러 정보들이 혼합되어 구성될 수 있다. 따라서 더욱 잘개 쪼개어 하나의 단순한 지식만을 가지는 문장(a short sentence conveying one piece of information)으로 재구성하는 것이 더욱 바람직하다.
Factual precision based on Knowledge Source
기존 연구들은 어떤 정보에 대해 평가하고자 할 떄, 일반적(Global)인 관점에서 참과 거짓 여부를 판단하려했다. 하지만 어떤 지식 원천(Knowledge Source - 문서, 사전 등)을 기준으로 하느냐에 따라 그 결과가 달라질 수 있다. 따라서 절대적인 참과 거짓(True/False)보다는 지식의 원천에 따라 지지되는지, 지지되지 않는지(Supported/Non-supported)를 판단하는 것이 보다 현실적인 것으로 본다.
Problem Definition

- : 프롬프트 (질문)
- : 모델 이 에 대해 생성한 답변
- : 에서 추출한 원자적 사실들(atomic facts)
- : 개별적인 원자적 사실
- : 신뢰할 수 있는 지식 원천 (fact-checking을 위한 참고 자료)
수식의 의미를 풀어보면, 어떤 질문 에 대한 언어 모델의 응답 이 있을 때, 여기서 추출한 원자적 사실들 각각이 어떤 지식 원천 에 의해 지지되는지 여부로 신뢰도를 측정하겠다는 것이라 할 수 있다.
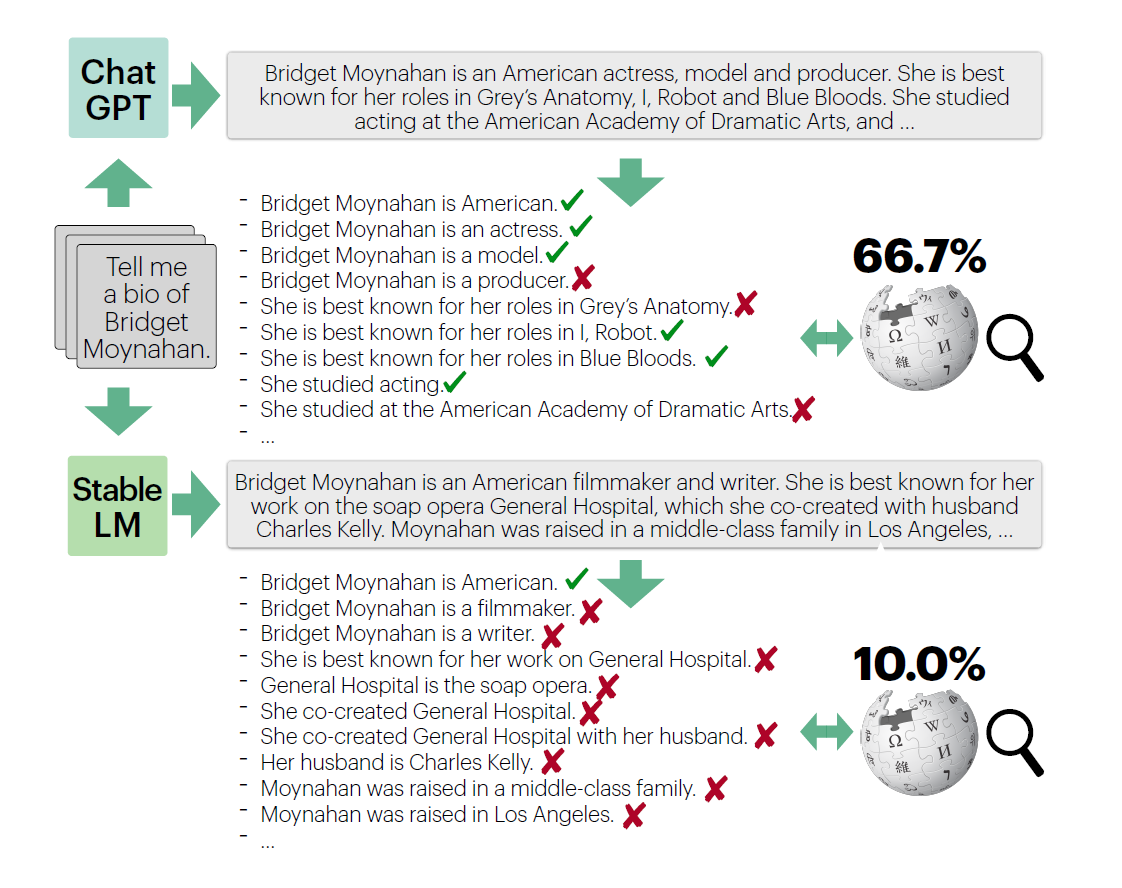
Methodology 1. Human Evaluation
논문에서는 FACTSCORE를 측정하는 방법을 (1) 사람이 직접 수행하는 방법과 (2) 언어 모델을 사용하는 방법 두 가지로 나누어 보고 있다. Task는 어떤 사람의 일대기(Biography)를 작성한 뒤, 위키피디아를 지식 원천으로 하여 산출하는 것으로 하였는데, 일대기가 비교적 객관적이면서도 다양한 내용을 포함할 수 있다는 점을 고려했다고 한다.
Human Annotator들은 두 개의 그룹으로 나누어 실험에 참여하였다. 첫 번째 그룹은 언어 모델의 응답을 구성하는 원자적 사실들을 추출해내는 역할을 맡았고, 두 번째 그룹은 원자적 사실 각각을 판단하는 작업을 하도록 했다. 이때 각 원자적 사실에 대한 레이블은 'Irrelevant', 'Supported', 'Non-supported' 세 가지로 구성했다.
평가 대상 언어 모델로는 InstructGPT, ChatGPT, PerplexityAI 를 사용했다.
Results
1. 모든 언어 모델들이 사실적 정확성(facual precision) 오류를 겪음
InstructGPT(42.5%), ChatGPT(58.3%), PerplexityAI(71.5%) 모두 FACT SCORE가 크게 높지 않았다. 특히 검색 기능이 추가되어 있는 PerplexityAI의 경우 지식 원천인 Wekipedia에 접근 가능했음에도 만점과는 거리가 멀었다.
2. 학습에 사용된 빈도가 낮을수록 오류율이 높아짐
모든 모델이 자주 접하지 못한 인물을 다룰 때 더욱 많이 틀리는 경향을 보여주었다. PerplexityAI 또한 유사한 경향을 보였으나 상대적으로 성능의 감소 폭이 적었다. 이는 사전 훈련 데이터에서의 등장 빈도가 낮을수록 QA 문제에서의 정확도는 낮아진다는 점과 Retriever를 사용하면 이러한 문제를 완화할 수 있다는 기존 연구들(Kandpal et al. (2022), Mallen et al. (2023))과 유사한 결과이다.
3. 생성된 문장에서 뒤쪽에 위치한 사실일수록 오류율이 증가함
전체 생성 응답 중에서 뒷부분에 위치한 문장들에서 추출한 원자적 사실들이 오류율이 높게 나왔다. 이것의 원인으로 응답의 초반부에 등장하는 정보들이 상대적으로 잘 알려진 정보들일 가능성이 높다는 점과, 오류 전파로 인한 문제 등을 꼽고 있다. 또한 이러한 점에서 짧은 답변으로만 언어 모델의 성능을 평가하는 것이 위험하다는 점을 지적한다.
4. 출처 제공을 하는 것이 사실적 정확성에 미치는 영향은 미미함
출처를 함께 제공하는 PerplexityAI 의 실험 결과를 분석해보면 사실적으로 지지되는 문장 중 36.0%가 출처를 포함하였고, 사실적으로 지지되지 않는 문장들은 37.6%가 출처를 포함하고 있었다. 즉, 출처를 함께 생성했다고 해서 사실적 오류가 적다고 하기 어렵다(관련 연구).
Methodology 2. Automatic Evaluation
사람이 직접 평가에 참여하는 방법은 비용과 시간이 매우 많이 드는 방법이다. 따라서 사람과 유사하게 FACT SCORE를 계산하는 방법 또한 함께 제안한다.
가장 먼저 언어 모델의 생성 결과를 여러 개의 원자적 사실로 쪼개는 과정은 InstructGPT 모델을 사용하여 해결한다. Chen et al., 2022)의 연구에 따르면 이와 같은 Decomposition 작업은 언어 모델들이 충분히 잘 수행할 수 있다고 한다.
생성된 원자적 사실들에 대한 판단은 다음 네 가지로 나누어 실험을 진행했다. ChatGPT와 같이 상용 언어 모델의 경우 logit에 직접 접근하는 것이 불가능하여 "True/False"를 포함하는지 여부로 판단하도록 했다.
1. No-Context LM
<atomic-fact> True or False?만을 프롬프트로 언어 모델에 제공하는 방법
2. Retrieve→LM
- 지식 원천에서 검색한 뒤, 검색 결과를 함께 붙여
[concatnated k doc] True or False?형태로 언어 모델에 제공하는 방법
3. Nonparametric Probability (NP)
- Non-parametric masked LM 으로 개별 토큰의 likelihood 를 계산하여 평가하는 방법
- 예를 들어,
미국의 수도는 워싱턴 D.C.이다.라는 원자적 사실이 주어진 경우,미국의 수도는 [MASK] D.C.이다.,[MASK]의 수도는 워싱턴 D.C.이다.처럼 Masked 된 문장을 만들고, Masked 된 토큰을 정확히 채워넣을 확률을 구한 뒤, 이들의 평균을 내어 최종적인 신뢰도를 평가하는 것
4. Retrieve→LM + NP
- 2번과 3번을 앙상블하는 방법, 즉 두 가지 방법에서 모두 'Supported'로 응답한 경우만 'Supported'로 평가하는 방법
Results
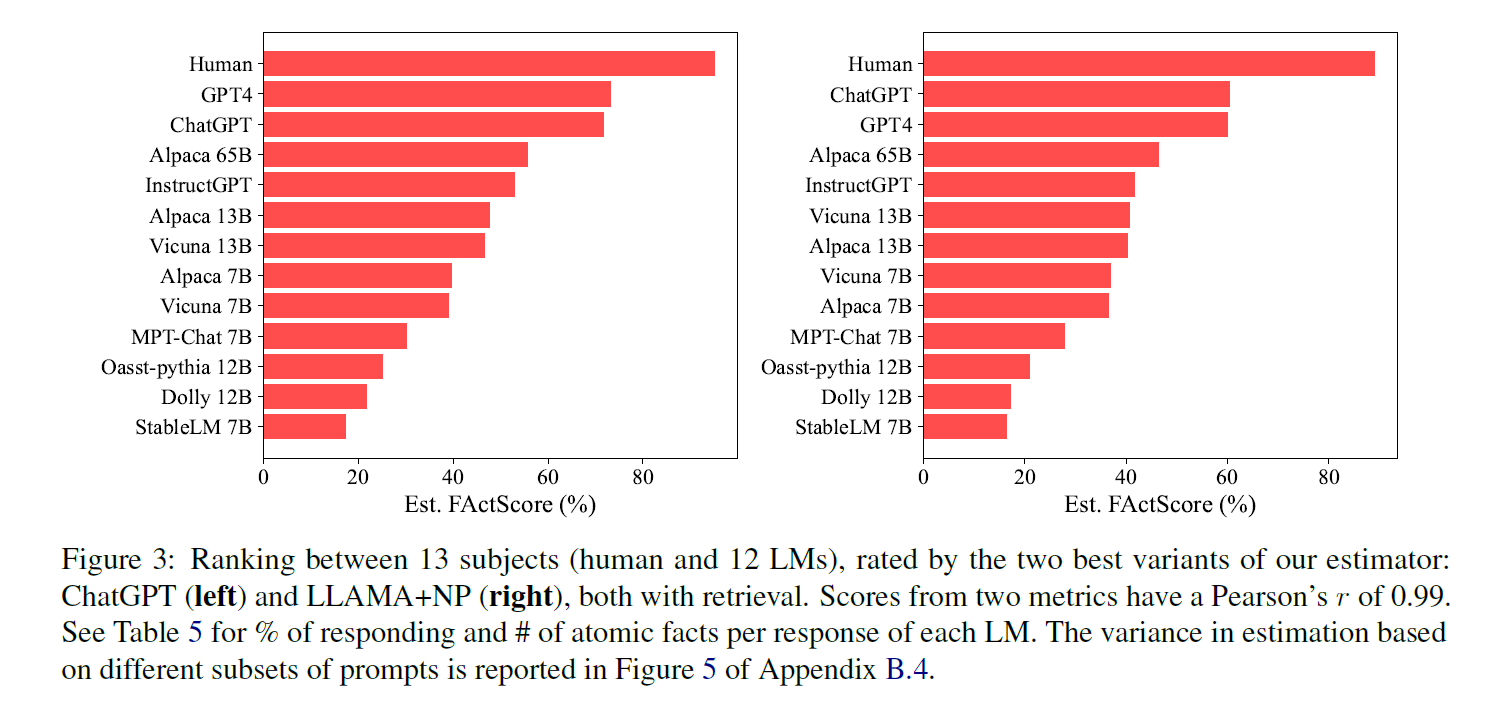
실험은 논문을 작성할 당시 가장 최근 모델 10개를 선정하여 진행하였다. 여기에는 GPT-4, Alpaca, Vicuna, Dolly 등이 포함된다. 이에 대한 실험 결과는 다음과 같다.
1. 모든 언어 모델이 사람보다 사실적 정확성이 낮음
FACTSCORE 기준으로 실험에 사용된 모든 언어 모델들이 사람과 비교해 낮은 점수를 보여주었다.
2. 모델의 크기가 크면 클수록 높은 점수를 보임
같은 모델 계열에서 크기가 클수록 FACTSCORE 가 높아지는 경향을 보였다. 즉, 모델 크기와 사실적 정확성은 양의 상관 관계를 보이는데, 큰 모델일수록 학습에 사용된 데이터가 많아서 그런 것으로 추측한다.
3. ChatGPT, GPT-4가 공개 모델보다 성능이 좋았으며, 공개 모델 간에도 성능 차이가 꽤 있었음
비슷한 7B 크기의 모델들 간에도 Alpaca (40%) > Vicuna (40%) > MPTChat (30%) > StableLM (17%) 순으로 성능 차이를 보였다. 베이스 모델, 학습 데이터, 학습 방법 등이 영향을 미친 것으로 보인다.