- Published on
[CoVe] Chain-of-Verification Reduces Hallucination in Large Language Models
Introduction
Hallucination 은 언어 모델이 그럴싸하지만 틀린 답변(incorrect fuctual information)을 내놓는 문제를 가리킨다. 거대 모델들은 Reasoning 등에서 높은 성능을 보여주었지만, training 시에 보지 못한 데이터들(torso and tail)에 대해서는 틀린 답변을 내놓는 문제를 보인다. 특히 복수의 문장을 생성하는 등 출력의 길이가 길면 길수록 exposure bias 등으로 인해 이러한 문제는 더욱 심화되는 경향을 보인다. Chain-of-Verification(CoVe) 은 Meta AI 에서 2023 년에 발표한 논문으로, 좋은 initial thought 와 reasoning chain 을 구성하면 언어 모델의 hallucination 문제를 줄일 수 있을 것이라는 가정에서 출발한다.
Head-Torso-Tail distribution: Corpus에서 자주 등장하는 개념을 Head, 중간 빈도로 등장하는 개념을 Torso, 드물게 등장하는 개념을 Tail 이라고 한다. Torso and Tail 이라 하면 Training set 에서 자주 등장하지 않는 개념을 의미한다.Exposure bias: 추론 과정에서 중간에 작은 오류가 발생하면 이것이 점점 더 큰 오류로 이어지면서 잘못된 답을 내놓을 가능성이 커지는 문제를 말한다. Hallucination 의 대표적인 원인 중 하나이다.
Related work
Hallucination 을 줄이는 방법들은 크게 다음 세 가지 카테고리로 나누어 볼 수 있다.
1. Training time correction
Hallucination 을 줄이는 방향으로 언어 모델의 학습을 진행하는 방법을 말한다.
2. Generation time correction
생성 결과에 대한 검증을 통해 hallucination 을 줄이는 방법을 말한다.
- Token Probability Analysis: paper
- 생성된 토큰의 확률의 크기를 통해 모델이 얼마나 자신감을 가지고 생성했는지 평가하는 방법
- Multiple Sampling: SELF CHECK GPT
- 여러 개의 샘플 생성 후 일관성이 떨어지는 부분을 Hallucination 으로 판단하는 방법
- Confidence Score: paper
- 신뢰도가 낮은 부분을 식별하고 추가적인 검증을 진행하는 방법
- Consistency Check: paper
- 모델에게 직접/간접적인 방식으로 여러 번 질문하고, 확보된 여러 개의 응답 샘플을 비교하는 방법
논문에서 제안하는 CoVe 는 여기에 속하는 방법으로, 구체적으로 보면 자기 일관성(self-consistency)을 검증하는 방식이라고 할 수 있다.
3. Augmentation
외부의 정보 및 도구들을 활용하여 응답을 검증하는 방법을 말한다.
- Retrieval Augmented Generation: Retrieval Augmentation, Active RAG, Chain-of-Though Verification
- 외부 문서를 검색하고 이를 생성에 활용하는 방법
- Fact Check: FACT TOOL
- Fact Check 와 관련된 도구를 활용하는 방법
- Link to external docs with Attribution: paper, RARR
- 참조한 외부 문서의 출처를 명확히 표시하도록 하는 방법
Chain-of-Verification
논문에서 제안하는 CoVe는 '언어 모델이 응답을 생성하는 것 뿐만 아니라 그것에 대해 검증할 수 있는 검증 계획을 세우고, 이를 직접 실행하여 검증하는 것도 잘할 수 있을 것이다'를 가정한다. 이를 검증하기 위해 다음과 같이 검증 계획을 생성하고, 그것을 실행하는 과정을 담은 CoVe Pipeline을 다음과 같이 제안한다.

1. Generate Baseline Response
Query에 대한 언어 모델의 응답을 생성하는 단계다. 논문에서는 일반적인 LLM 응답 생성과 동일하며 특별한 점은 없다(no special trick)고 언급한다.
2. Plan Verification
Query와 Baseline Response 를 입력으로 하여 이를 검증할 List of Verification Questions 를 생성하게 되는데, 이를 Verification Plan 이라고 한다. 관련 질문들을 적절하게 생성할 수 있도록 적절한 프롬프트와 몇 개의 예시(few-shot)들을 함께 제공한다. 다만 Verification Question 자체에 대해서는 템플릿 등을 제공하지 않고 최대한 자유롭게 생성하도록 한다.
3. Execute Verifications
Query, Baseline Response와 함께 Verification Questions 에 대한 응답을 생성하고 불일치(inconsistency)하는 부분을 찾아내는 과정을 검증을 수행한다고 표현한다. Retrieval Augmentation을 활용할 수도 있지만 모델이 스스로의 응답을 자체 검증하는 능력을 가지는지 검증하는 것이 목표로 하는 만큼 논문의 실험에서는 사용하지 않았다고 한다.
Planning 과 그것에 대한 Execution 을 어떻게 수행하느냐에 따라 논문에서는 구체적으로 네 가지 방법론을 제시하고, 각각에 대한 비교 실험을 진행하고 있다.
Joint
Planning 과 Execution 을 한 번에 수행하는 방법이다. 즉, Query와 Baseline Response 를 입력으로 하여 Verification Questions 와 그에 대한 응답을 차례대로 함께 생성하도록 하는 것이다. 이를 위해 별도의 프롬프트 없이 few-shot 으로 예시를 제공한다.
2-Step
Joint 방식의 단점은 likelihood of repetition, 즉 언어 모델이 Baseline Response 를 그대로 반복하는 식으로 동작할 수 있다는 점이다. 이전 step의 출력 토큰이 다음 step의 입력 토큰이 되는 현재의 언어 모델의 특성상 검증 대상(baseline response)을 입력으로 받고, 검증 결과(verification answer)를 출력으로 생성하는 꼴이 된다. 따라서 검증 결과가 검증 대상에 conditioned 되고, likelihood of repetition이 커지게 된다. 그 결과 이로인해 baseline response 에 할루시네이션이 있다 하더라도 제대로 검증하지 못하고 반복할 가능성이 높아진다.
이러한 문제를 없애기 위해서는 planning 과 execution 이 분리되어야 하는데, 이를 2-Step 방법으로 이름 붙이고 있다. Step 1 에서는 Query 와 Baseline Response 를 입력으로 받아 생성하고, Step 2에서는 Step 1에서 생성한 Verification Question 만 입력으로 하여 검증을 수행하게 된다.
Factored
2-Step 또한 구조적인 단점이 있는데, 복수의 Verification Questios 를 한꺼번에 모델이 입력으로 전달받아 검증을 진행하기 때문에 Verification Answer Context 간에 서로 영향을 줄 수 있다는 점이다. Factored 방법은 Verification Question을 하나씩 쪼개어 언어 모델에 넣고 검증한다. 수행하는 추론의 갯수가 늘어나 연산량이 많아진다는 단점이 있지만, 병렬 처리가 가능해 상쇄할 수 있다.
Factor + Revise
끝으로 Factor + Revise 는 baseline response, verification question, verification response 가 query 의 내용과 일치하는지 검증하는 단계를 하나 더 추가하는 방법을 말한다. 이때 Cross Check 프롬프트를 few-shot 과 함께 넣어준다.
4. General Final Verified Response
최종 응답을 생성하는 단계로, 특징이 있다면 query, baseline response, verifiaction response and answer pair 등 지금까지 사용된 모든 쿼리와 응답을 few shot 예시와 함께 모두 넣어준다는 점이다. 이는 단순히 새로운 응답을 생성하는 것이 아니라, 기존 Baseline Response 에서 불일치하는 부분을 확인한 뒤 수정하도록 하기 위함이다. 이때 Factor Revise 방법이라면 교처 검증 결과로 불일치하다고 판단했더라도 함께 넣어주게 된다.
Exeperiment
Task & Dataset
논문의 실험으로는 두 가지 종류의 Task 를 다루고 있다. 첫 번째는 Set of Entity 를 맞추는 문제로, '1990년대에 개봉한 한국 영화의 이름을 대시오'와 같이 질문에 대한 답이 단순하지만 복수 개가 될 수 있는 문제들이다. 구체적으로는 다음과 같은 데이터 셋을 활용하여 생성하였다고 한다.
- Wikidata: 600개 이하의 정답을 갖는 56개의 test questions 를 추출
- QUEST(Wiki-Category List): 각 8개의 정답을 갖는 55개의 test questions 를 추출
- 논리 연산을 필요로 하지 않는 질문들을 추려내어 구성
- 카테고리의 이름 앞에 "Name some" 을 붙이는 식으로 질문 형태로 만듦
- Name some Mexican animated horror films
- Name some Endemic orchids of Vietnam
- MULTISPAN QA: 최대 3개의 토큰 길이를 갖는 짧은 답변을 정답으로 가지는 418개의 questions 추출
- MULTISPAN QA 는 reading comprehension 을 평가하는 데에 사용되는 벤치마크, 일부분을 추출하여 test questions 를 생성함
- Q: Who invented the first printing press and in what year?, A: Johannes Gutenberg, 1450.
두 번째 유형의 Task 는 longform sentence 를 생성하는 문제이다. 여기서는 'Tell me a bio of [entity]'와 같은 질문을 주고 어떤 인물에 대한 biography 를 생성하는 실험으로 평가한다. 메트릭으로는 FACTSCORE에 나오는 벤치마크를 활용했으며, 인간의 평가 결과와 높은 유사성을 가지는 것으로 알려져 있는 Retrieval augmented LM: Instruct-Llama ("Llama + Retrieval + NP")를 사용했다고 한다.
Model
기본적으로 greedy decoding 을 적용한 Llama 65B 모델을 사용하였고, Task의 유형에 맞게 그에 맞는 few shot 을 제공하여 Baseline 모델들과의 성능 비교를 진행하였다. CoVe의 경우 Baseline response 는 동일하게 진행하되, 검증 질문과 검증 질문 및 최종 응답을 포함하는 demonstration 을 few-shot 으로 추가 제공하여 그 결과를 비교하도록 했다.
또한 Instruction tuned model 인 Llama2와의 성능을 비교했다. Instruction tuned model의 특성에 맞게 zero-shot, zero-shot + CoT 방식으로 실험을 진행했고, few-shot 에 대한 실험도 추가적으로 진행했다.
끝으로 Longform biography 를 생성하는 Task에 대해서는 InstructGPT, ChatGPT2, PerplexityAI 와 같은 모델들과 성능을 비교해 보았다.
Results
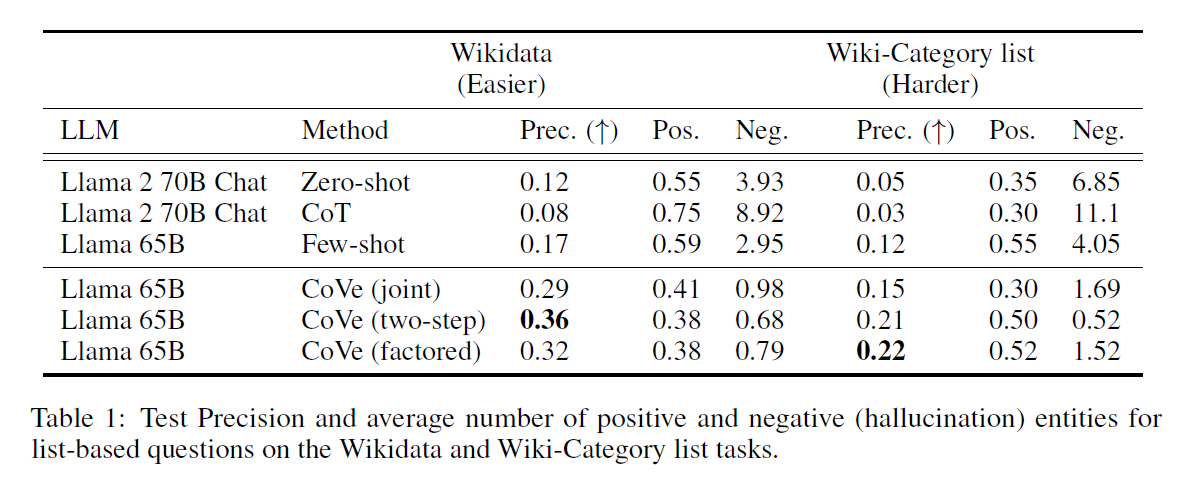
두 가지 종류의 List based Answer Task 에서 베이스라인이 되는 Llama 65B와 비교해 볼 때 세 종류의 CoVe 방법들이 Precision 에서 모두 더 우수한 Precision 을 보여주었다. 특히 Hallucination이라고 할 수 있는 Negative의 평균 갯수가 2.95(Baseline)에서 0.68(2-step)으로 줄어들었다는 것을 알 수 있다.
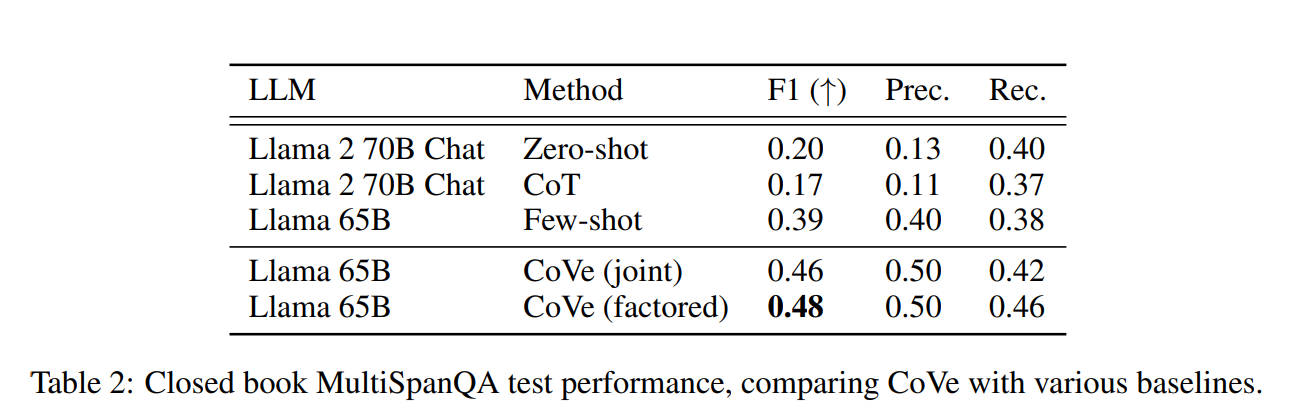
Closed Book MultiSpanQA 실험에서도 위와 동일하게 Baseline 보다 CoVe 를 적용하였을 때 F1, Precision, Recall 모두에서 더 높은 점수를 기록하였다.
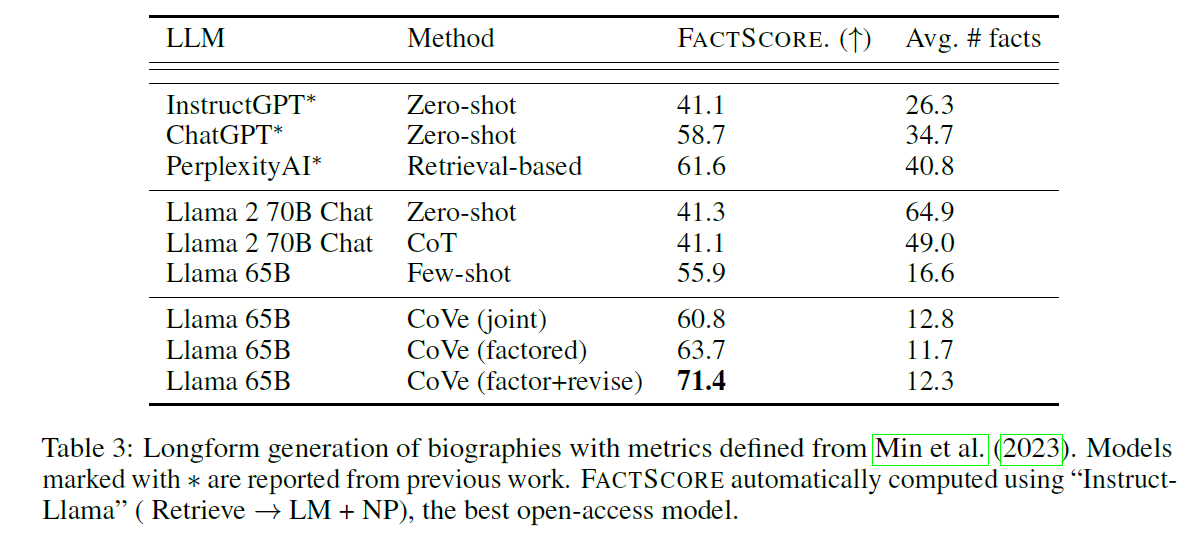
FACTSCORE를 기준으로 측정하는 Longform generation Task에서도 Baseline 보다 세 가지 CoVE 방법을 적용하였을 때 그 결과가 더 좋게 나왔다.
위의 세 테이블에서는 Instruction tuning 을 적용한 모델(Llama 65B Zero-shot, CoT) 와도 비교를 진행하고 있는데, 모든 경우에 CoVe를 적용한 것보다 결과가 좋지 못했다. 이러한 점에서 Instruction tuning 기법은 Hallucination 을 해소하는 데에 효과적이지 못하다는 것을 알 수 있다.
CoVe 의 네 가지 방법(Joint, 2-step, Factored, Factor+Revise)들에 대해서도 다소 일관된 결과들을 확인할 수 있었는데, 2-step, Factored 가 Joint 에 비해 확실히 높은 점수를 기록했다. 이는 repetition likelihood 로 인한 문제가 발생할 수 있다는 가정이 옳았음을 보여주는 결과라고 할 수 있다.
또한 FACTORSCORE 를 기준으로 factor + revise 가 다른 방법들에 비해 더 좋은 점수를 기록했다. 이는 Cross-Check로 불일치 여부를 검증하는 것과 같이 명확한 검증을 수행하고 그 결과를 활용하면 Hallucination 을 더욱 줄일 수 있다는 것을 의미한다.
InstructGPT, ChatGPT and PerplexityAI 와의 비교에서도 CoVe를 사용한 일부 모델들이 더 좋았다. 특히 PerplexityAI 는 Retrieval Agumentation 을 사용한다는 점에서 주목할 만한 결과라고 할 수 있다.
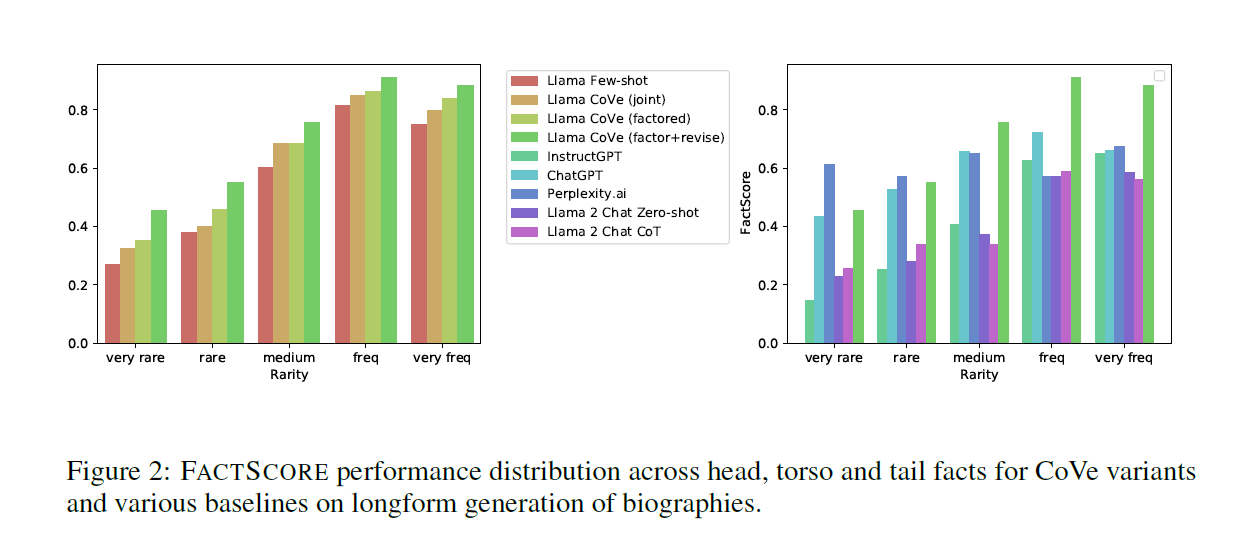
하지만 PerplexityAI 는 very rare 와 rare 한 fact 들에 대해서는 Cove를 비롯한 다른 모든 방법들보다 더 높은 점수를 기록했다.
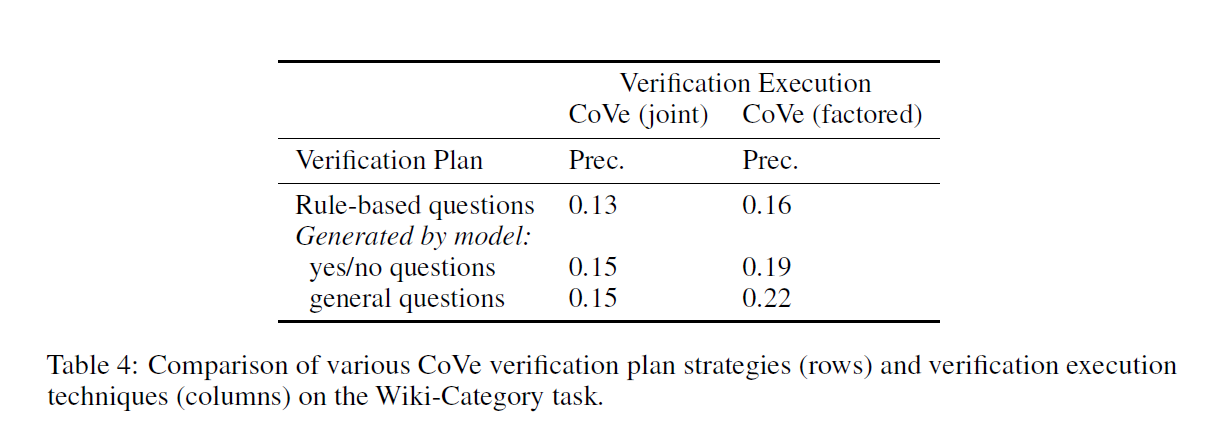
끝으로 Question 을 언어 모델로 생성하는 것과 단순한 규칙(heuristic)으로 생성하는 것 또한 비교해보았는데, 언어 모델을 사용할 때에 CoVe에서 Precision이 높게 나왔다. 또한 Open verification 이 yes/no 질문보다 효과적이었다.
Limitation
CoVe의 한계로 우선 (1) Hallucination 을 완전히 제거하지는 못한다는 점을 들고 있다. Hallucination 의 원인은 CoVe가 주로 다루고 있는 사실에 대한 정확성 외에도 다양하게 존재하는데, CoVe가 이를 모두 해결하지는 못하기 때문이다.
또한 (2) Baseline 방법에 비해 언어 모델에 추가적인 질의를 하게 되므로 연산 비용이 늘어나는 것 또한 한계로 지적한다.
끝으로 (3) CoVe는 전적으로 언어 모델의 성능에 기대어 문제를 해결하는 접근 방법이기 때문에, 결국 언어 모델의 성능에 따라 CoVe의 성능 또한 그 상한이 정해지게 된다는 점이다. 이를 극복하기 위해 외부 데이터를 사용하거나 새로운 정보를 탐색하여 접목시키는 방법 등이 매우 유용할 것으로 보인다.