논문 제목 : Fully Convolutional Networks for Semantic Segmentation
- Jonathan Long, Evan Shelhammer 등
- 2014
- 논문 링크
세 줄 요약
- Semantic Segmentation이란 픽셀 단위로 물체를 인식/구분하는 것을 말한다.
- FCN은 VGG16의 FC layer를 1x1 convolution로 대체하고, transpose deconvolution으로 upsampling을 수행하여 이미지의 크기에 구애받지 않고 원본과 동일한 크기로 semantic segmentation을 가능하게 한다.
- 또한 이전 출력값을 최종 출력값에 더하는 skip architecture로 성능을 높였다.
Semantic Segmentation

sementic segmentation이란 위 그럼과 같이 이미지 상에 어떤 물체가 있는지 여부만을 판단하는 것이 아니라 어떤 물체가 어디에 어떻게 있는지 픽셀 단위로 구분하는 것을 말한다. 물체의 위치를 범주화하여 보여주는 것이 아니라 최소 단위인 픽셀 수준에서 구분한다는 점에서 dense prediction이라고도 한다.
논문에서는 Semantic Segmentation의 방법으로 Fully Convolutional Netwrok(FCN)를 제시하고 있다. FCN은 과거 방법론과 비교해 비약적으로 높은 성능을 보여주었고, 결과적으로 이후 나오게 되는 다른 알고리즘에도 많은 영향을 미쳤다.
Fully Convolutional Networks
FCN의 장점은 크게 두 가지로, 픽셀 단위의 segmentation이 가능하다는 점과 이미지 사이즈에 구애받지 않는다는 점이다. 즉 FCN은 어떠한 이미지를 넣어도 해당 이미지와 동일한 사이즈의 이미지로 semantic segmentation 결과를 출력한다. FCN의 이러한 장점은 1x1 convolution과 deconvolution이라는 두 가지 구조적 특성에서 나온다. 두 가지 외에 FCN은 VGG16을 사용한다는 점과, Skip Architecture를 이용해 성능을 높이는 점 등의 특징이 있다.
1. VGG16
FCN은 기본적으로 image classification에서 높은 성능을 보인 VGG16을 사용하며, 이를 fine-tuning하는 방식으로 학습한다. 이를 통해 이미지가 가지고 있는 특징을 잘 추출하고, 학습의 효율성을 높인다.
참고로 AlexNet, GoogLeNet 에 대해서도 실험을 진행했지만, VGG16의 성능이 가장 좋았다고 한다.
2. 1 x 1 Convolution
하지만 VGG16을 사용하게 되면 마지막에 붙어 있는 Fully Connected Layer(FC) 때문에 (1)이미지의 크기에 제약이 발생하고, (2)출력값의 위치 정보가 소실된다는 두 가지 문제점이 발생한다. 단순 classification의 경우 FC layer로도 충분하지만 segmentation과 같이 위치 정보가 중요한 경우에 FC layer는 적합하지 않다.
이러한 문제를 해결하기 위해 논문에서는 1x1 convolution, 즉 1x1 사이즈의 kernel(filter)을 사용하는 convolution layer로 FC layer를 대체한다. 1x1 convolution은 수학적으로 FC와 동일하다는 것이 증명되어있다. GoogLeNet, Overfeat 등과 같이 classification, object detection 분야에서 많이 사용되어왔지만 Semantic Segmentation 분야에서는 FCN에서 처음 사용되었다고 한다.
구체적으로 1x1 Convolution은 다음과 같은 장점을 갖는다.
(a) arbitrary input size
FC layer의 경우 입력의 크기와 출력의 크기가 고정적이다. 따라서 VGG16에서 FC layer 이전에 위치하고 있는 CNN layer의 값도 정해진 크기만 가능하며, 이는 곧 모델로 한 번에 다룰 수 있는 이미지의 크기가 고정적이라는 것을 의미한다. 다양한 크기의 이미지가 있다면 각각의 크기에 따라 새로운 모델을 학습해야 한다는 것은 매우 비효율적이다.
하지만 1x1 convolution은 일반적인 CNN과 마찬가지로 입력값의 크기에 구애받지 않는다. 따라서 FC layer를 CNN layer로 바꾸게 되면 모델이 다룰 수 있는 이미지의 크기 또한 자유로워지게 된다.
(b) control channel size
kernel의 사이즈가 1x1 이므로 출력값은 입력값과 동일한 크기를 가지는 것으로 보인다. 하지만 1x1 convolution 또한 출력값의 사이즈를 바꿀 수 있는데, 바로 channel size를 줄이거나 늘리는 것이다. channel의 사이즈를 조절해가며 image의 특징을 잡아낼 수 있고, 이미지의 크기를 바꾼다는 점에서 연산량 또한 조절할 수 있다.
(c) computational efficiency
1x1 convolution은 보다 큰 kernel을 갖는 convolution에 비해 gradient 계산 등에 있어 연산량이 적다. 왜냐하면 1x1 convolution을 사용하면 reception field(한 출력값에 영향을 미치는 입력값의 범위)가 겹치는 범위가 크게 줄어들기 때문이다.
3. Upsampling - Deconvolution
convolution과 pooling 과정을 거치게 되면 입력값보다 출력값의 크기가 줄어든다. FCN 또한 VGG16을 사용하므로 이미지가 줄어들게 되는데, 픽셀 단위로 segmentation 하기 위해서는 이를 원래 이미지 크기대로 늘리는 과정이 필요하다. 이를 Upsampling이라고 하는데, 구체적으로 FCN에서는 deconvolution(backwards convolution)을 사용한다. Deconvolution에는 여러 종류가 있는데, 여기서 말하는 방법은 transpose convolution으로, convolution을 일반적인 행렬로 나타냈을 때 이를 전치한 것을 곱하는 방식으로 upsampling을 달성한다.
4. Skip Architecture
그런데 convolution과 pooling의 과정에서는 어쩔 수 없는 정보의 손실이 발생한다. 따라서 convolution layer를 여러 번 통과한 이미지를 다시 upsampling하여 원본 이미지로 키우면 위치에 따른 특징은 남아있더라도 뭉뚱그려져 나오게 된다. 따라서 픽셀 단위의 정확한 물체 구분을 위해서는 특별한 방법을 도입할 필요가 있는데, FCN에서는 convolution layer 사이사이의 출력값들을 활용한다. 이렇게 사이의 출력값들은 다른 뒤의 layer들은 통과하지 않는다는 점에서 skip이라고 부르며, 이와 같은 구조를 skip architecture라고 한다.
여기서 활용한다는 것은 각각의 출력값을 더해 이를 최종 출력값으로 활용하겠다는 것이다. 하지만 어느 위치에서 가지고 왔는가에 따라 출력값의 크기가 다르기 때문에 바로 더할 수 없다는 문제가 있다. 따라서 논문에서는 뒤에서 나타난 출력값(크기가 작다)에 bilinear interpolation으로 upsampling을 진행한 후 더해준다. deconvolution은 이렇게 더해진 값에 대해서 실시하게 된다.
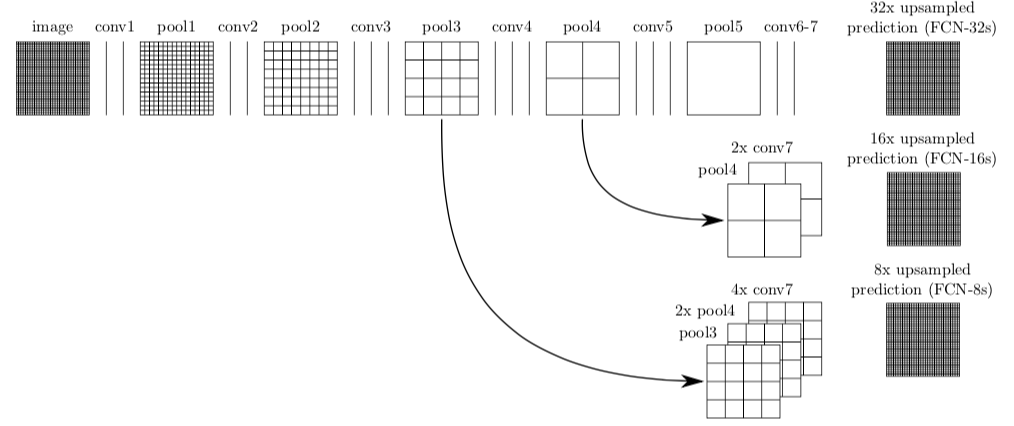
- FCN-32 : Conv7의 출력값 X 32 upsampling
- FCN-16 : Conv7의 출력값 + pooling4의 출력값 X 16 upsampling
- FCN-8 : Conv7의 출력값 + pooling4의 출력값 + pooling3의 출력값 X 8 upsampling
논문에서는 deconvolution upsampling을 얼마나 크게 진행했는가에 따라 FCN-32, FCN-16, FCN-8 세 가지로 나누고 있다. 32배를 한 FCN-32는 출력값 간의 더하기 없이 최총 출력값 하나만 사용한 것이고, FCN-8는 총 3개의 출력값을 더한 것에 deconvolution 연산을 적용한 것이다. 성능은 FCN-8이 가장 좋으며, segmentation이 선명하게 나타나는 것을 확인할 수 있다.