논문 제목 : Dream to Control: Learning Behaviors by Latent Imagination
- Danijar Hafner, Timothy Lillicrap, Jimmy Ba, Mohammad Norouzi
- 2020
- 논문 링크
Summary
- 2020년 기준 Model-Based Algorithm의 SOTA로 알려져 있는 모델 Dreamer를 제시한다.
- Latent Space에서 Trajectory를 Prediction하고 Action을 결정하여 Image에 대해서도 효율적으로 학습이 가능하다. 이를 위해 3개의 모델로 Latent Dynamcis를 학습한다.
- Actor-Critic 구조의 알고리즘을 사용하여 Latent Space 상에서 Value를 극대화할 것으로 예상되는 Action을 선택한다. Value를 사용하기 때문에 Horizon의 제약이 없다는 장점을 가지고 있다.
Introduction
Model-Based Algorithm을 사용하면 복잡한 환경 속에서도 동일한 상황을 두 번 이상 반복적으로 경험하고 학습하지 않아도 목표를 달성할 수 있다. 이는 Agent가 World(Environment)에 대해 정보를 가지고 있어 어떤 State에서 어떤 Action을 했을 때 Reward는 얼마이며 Next State는 어떻게 되는지 예측하는 것이 가능하기 때문이다. 그런데 이러한 Planning과 관련하여 단순히 예측의 정확도가 낮다는 문제 외에도 여러가지 현실적인 문제가 발생하는데 대표적으로 이미지와 같이 State의 차원 수가 너무 커 예측이 불안정하고 시간과 메모리를 많이 요구하는 경우가 있다.
이와 같은 문제를 해결하기 위해 PlaNet을 비롯해 이미지를 대상으로 하는 많은 Model-Based Algorithm에서는 환경으로부터 받은 이미지를 그대로 사용하지 않고 State를 VAE 등을 활용하여 Latent Space 상에 매핑한 값인 Latent State를 사용한다. 예측 또한 Latent Space에서 이뤄지게 되는데, 이러한 점에서 Latent Dynamics를 배운다고 표현한다. Latent는 원본 이미지와 비교해 볼 때 그 크기가 훨씬 적으므로 이 경우 더욱 멀리 예측하거나, 동시에 여러 예측을 수행하는 것이 가능해진다. 본 논문에서 제시하는 모델 Dreamer 또한 이러한 Latent Dynamics Model을 사용한다.
Agent Components of Dreamer
Dreamer의 Agent는 두 부분으로 나눠지는데, Latent Dynamics Model은 Latent Space 상에서 이뤄지는 작용들을 학습하는 부분이고, Action & Value Model는 Planning의 과정 상에서 Value와 Action을 예측하기 위해 사용되는 부분이라고 할 수 있다.
Latent Dynamics Model
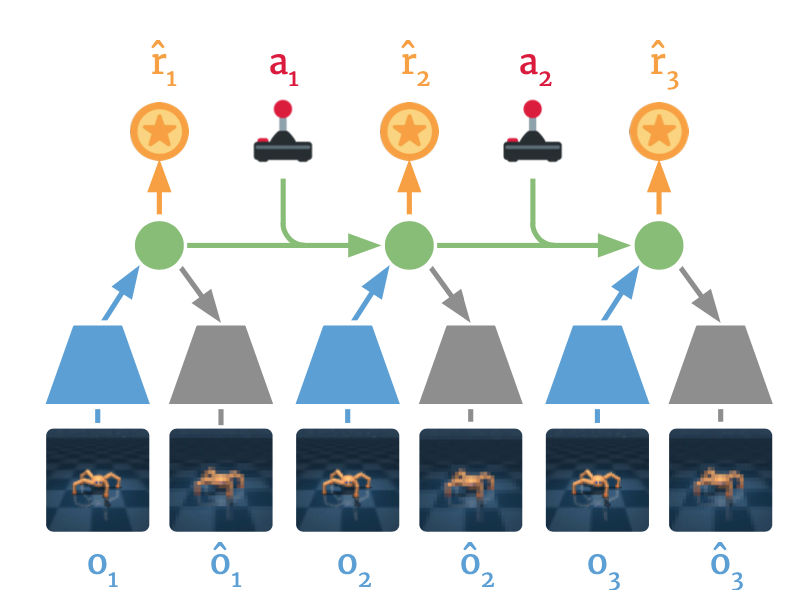
Latent Dynamics Model은 현재의 Policy가 실제 Environment와 상호작용하며 얻은 Trajectory들을 대상으로 학습한다. 이를 통해 Environment로부터 주어지는 Observation이 어떠한 Latent State로 매핑되는지, Latent State에서 Action이 주어졌을 때 Next Latent State는 어떻게 되는지, 그리고 각각의 Latent State에서 주어지는 Reward는 어떠한지 학습하게 된다. 수식으로 이를 표현하면 아래 세 가지가 된다.
\[\eqalign{ \text{Representation Model: } & p(s_t \lvert s_{t+1}, a_{t+1}, o_t)\\ \text{Transition Model: } & q(s_t \lvert s_{t-1}, a_{t-1})\\ \text{Reward Model: } & q(r_t \lvert s_t)\\ }\]Representation model은 확률 함수가 \(p\)로 표기되어 있지만 Transition Model과 Reward Model은 \(q\)로 되어 있다. 이는 실제 Environment에서 받은 정보를 사용하여 Sample을 만들어내는 역할을 하는지, 아니면 Latent Space 상에서 Planning을 수행하는 역할을 하는지 구분하기 위해서이다.
Action & Value Model
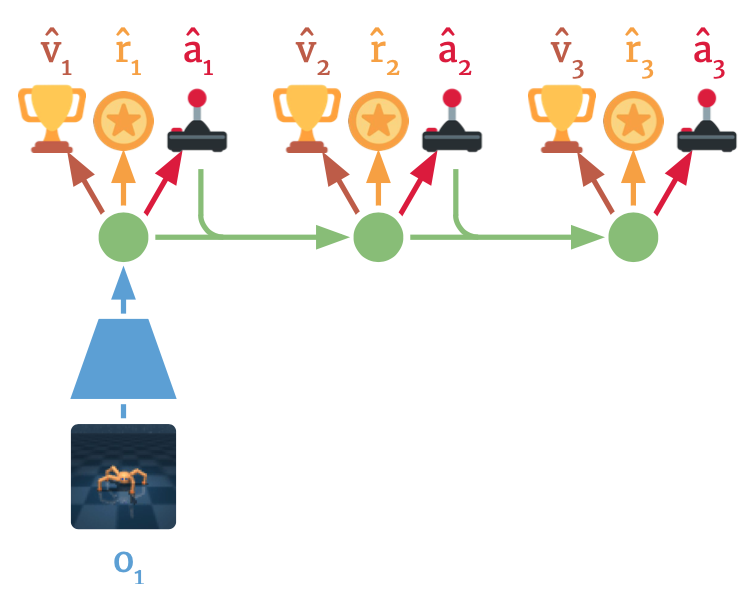
Latent Dynamics Model을 만드는 이유는 결국 좋은 Aciton이 무엇인지 정확히 Prediction 할 수 있는 모델을 만들기 위함이다. Dreamer에서는 이러한 Action을 계산하는 알고리즘으로 Actor-Critic 구조를 사용하고 있으며, 따라서 Action Model과 Value Model 두 모델을 학습시켜야 한다. 구체적으로 Action Model은 Latent Space 상에서 Reward를 극대화할 것으로 예상되는 Action을 선택하는 Policy이고, Value Model은 Latent Space 상에서 Action Model이 선택한 Action과 그에 따라 결정된 다음 Latent Space에서 기대 Reward가 어떻게 되는지 예측하는 역할을 한다.
\[\eqalign{ \text{Action Model: } & a_\tau \backsim q_\phi (a_\tau \lvert s_\tau) \\ \text{Value Model: } & v_\psi(s_\tau) \approx E_{q(\cdot \lvert s_\tau)} ( \Sigma_{\tau = t}^{t+H} \gamma^{\tau-t} r_\tau) }\]Action Model은 \(\tau\)시점에서 Latent State \(s_\tau\)가 주어졌을 때 그에 맞는 Action \(a_\tau\)가 무엇인지 알려준다. Value Model은 이에 대해 알고 있을 때 \(s_\tau\)에서의 Value를 근사하는 역할을 한다. 이렇게 보면 Actor-Critic 구조가 가지는 장점은 Finite Horizon \(H\)를 가정할 때 보다 확실해진다. 왜냐하면 Value Model으로 Horizon 이후에 받을 것으로 기대되는 Reward를 구해 이를 고려하여 Action을 결정할 수 있기 때문이다.
Take Action
Action Model과 Value Model은 각각 \(\phi, \psi\)를 파라미터로 갖는 뉴럴 네트워크 모델이다. Action Model에서 중요한 것은 많이 겪어본 상황에 대해서는 현재 Action이 정말 좋은지 확인해야 하고, 많이 겪어보지 않은 상황에 대해서는 최대한 다양한 Action을 경험해보는 것이다. 이를 위해 Actor Model은 아래와 같이 SAC 논문에서 제시되었던 tanh-transformed Gaussian(Haarnoja et al., 2018) 방법을 사용하여 가우시안 분포에서 샘플링을 하면서도 Back Propagation이 가능한 Reparameterized Sampling의 장점을 취한다. 즉 VAE와 마찬가지로 평균과 분산 값을 모두 학습하여 조절할 수 있으므로 상황에 따라 Action에 대한 신뢰도를 평가하는 것이 가능하다.
\[a_\tau = \text{tanh}(\mu_\phi(s_\tau) + \sigma_{\phi}(s_\tau) \epsilon), \qquad \epsilon \backsim \mathcal N(0, \mathcal I)\]Value Estimation
State Value는 다양한 방법으로 추정할 수 있는데 방법에 따라 Bias와 Variance 간의 Trade-off가 나타난다. 참고로 여기서 말하는 Value Estimation이란 Value Model이 맞춰야 할 Target이라고 할 수 있다. 당연히 이를 어떻게 설정하느냐에 따라 학습의 양상 또한 달라질 수 있다. 논문에서는 아래 세 가지 방법을 제시하고 있다.
\[\eqalign{ V_R (s_\tau) &= E_{q_\theta, q_\phi} (\Sigma_{n=\tau}^{t+H} r_n)\\ V_N^k(s_\tau) &= E_{q_\theta, q_\phi} (\Sigma_{n=\tau}^{h-1} \gamma^{n-\tau} r_n + \gamma^{h-\tau} v_{\psi}(s_h) ) \quad h = \min (\tau+k, t+H)\\ V_\lambda(s_\tau) &= (1-\lambda) \Sigma_{n=\tau}^{h-1} \gamma^{n-\tau} V_N^n(s_\tau) + \lambda^{H-1}V_N^H(s_\tau) }\]첫 번째 \(V_R (s_\tau)\)는 가장 단순하지만 Horizon 이후의 Reward는 고려하지 않는다는 단점이 있다. 두 번째 \(V_N^k(s_\tau)\)는 \(v_{\psi}(s_h)\)를 도입하여 Horizon 이후 \(k\) Step까지의 Value를 고려하도록 하고 있다. Dreamer에서 사용하는 방법은 세 번째 \(V_\lambda(s_\tau)\)로 여러 \(k\)에 따른 Estimation에 대해 exponentially-weighted average를 취하여 Bias와 Variance 간의 균형을 잡는 방법이다. 당연히 성능은 세 번째 방법이 가장 좋았다고 한다.
Update Action Model & Value Model
Action Model의 목표는 Value Estimation \(V_\lambda(s_\tau)\)가 가장 높은 Action을 찾는 것이고 Value Model은 Value Estimate \(V_\lambda(s_\tau)\)를 정확하게 추정(regression)하는 것이다. 따라서 각각의 Objective Function은 다음과 같이 정의된다.
\[\eqalign{ \text{Action Model Obj: }& \max_\phi E_{q_\theta, q_\phi}(\Sigma_{\tau=t}^{t+H} V_{\lambda}(s_\tau) )\\ \text{Value Model Obj: }& \min_\psi E_{q_\theta, q_\phi}(\Sigma_{\tau=t}^{t+H} {1 \over 2} \| v_\psi(s_\tau) - V_\lambda(s_\tau) \|^2 ) }\]Algorithm
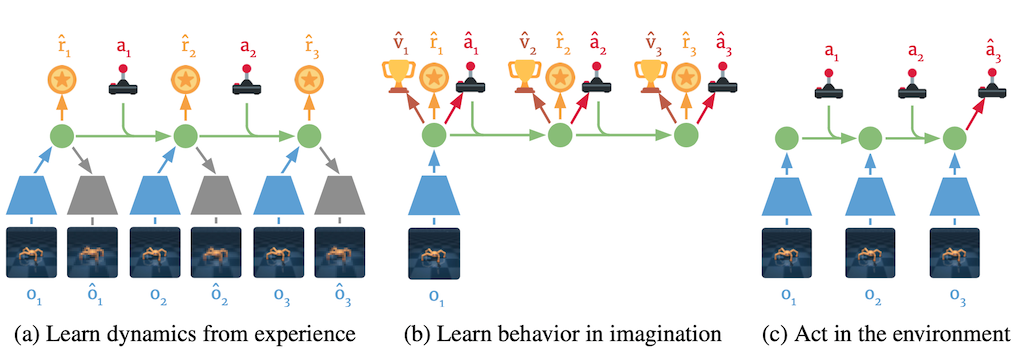
Dreamer의 알고리즘은 위의 그림과 같이 크게 Dynamic Learning, Behavior Learning, Environment Interaction 세 부분으로 구성된다. Dynamic Learning에서는 Latent Dynamics를 정확하게 알기 위해 \(\theta\)를 업데이트하게 되고, Behavior Learning에서는 Trajectory를 예측하고 그에 따라 Action Model과 Value Model을 업데이트하게 된다. 마지막으로 Environment Interaction에서는 학습한 Action Model으로 실제 Environment와 상호작용하며 학습에 사용할 실제 Trajectory를 쌓게 된다.
- Dynamic Learning: Update Representation, Trasition, Reward Model -> Make Prediction Correct
- Behavior Learning: Update Action, Value Model -> Make Policy Correct According to Prediction
