Dense Text Retrieval based on Pretrained Language Models: A Survey
Summary
- Dense Retriever 의 학습에는 Constrative Learning 에서 자주 사용되는 InfoNCE 와 유사한 loss function 이 사용된다.
- Negative 를 샘플링하는 방법, 다량의 데이터를 확보하는 방법, Informational Retriever Task 에 맞게 Pre-Training 하는 방법 등에 대한 연구가 있어왔다.
Introduction
Dense Retrieval 이란 pretrained language model(PLM)을 활용하여 Query에 맞는 적절한 Answer 를 찾아내는 것이다.
- 딥러닝의 발전은 Text를 latent space에 잘 매핑하게 해주었고, 이를 통해 Query 와 의미론적으로 매칭이 되는 Answer를 더욱 잘 찾을 수 있게 되었다.
- 이때 Dense Vector(embedding)를 활용하기 때문에 기존의 방식과 구별되며 이를 Dense Retrieval 이라고 한다.
Trainer: Loss function
Query \(q_i\) 가 주어졌을 때 Positive Text \(d_i^+\) 가 선택될 확률은 높이고, Negative Text인 \(d_i^-\) 가 선택될 확률은 낮추도록 loss function 을 설정해야 한다. 이와 같은 목적에 부합하도록 다음과 같이 Negative Log Likelihood function 형태로 loss function을 설정할 수 있다.
\[\mathcal{L}(\langle q_i, d_i^+ \rangle) = -\log \frac{e^{f(\phi(q_i), \psi(d_i^+))}}{e^{f(\phi(q_i), \psi(d_i^+))} + \sum_{d' \in \mathcal{D}^-} e^{f(\phi(q_i), \psi(d'))}}\]이러한 loss function 은 Constrative learning 에서 많이 사용되는 InfoNCE(Information Noise-Contrastive Estimation) loss function 과 유사하다.
\[\sigma(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{N} e^{z_j}}\]또한 구조적으로는 softmax 식과 유사한데, 일반적인 Softmax 식은 모델의 logit 이 들어가는 반면 여기서는 유사도 점수(similarity score, \(f\))가 입력으로 주어진다는 점에서 차이가 있다.
Similarity Measure
Query, Text 임베딩 간의 유사도를 측정하는 함수\(f\)로는 Inner Product, Cosine similarity, Euclidean Distance 등이 있다. 다양한 연구를 통해 세 가지 방법 중 무엇을 사용하더라도 성능에 큰 차이가 없다는 것이 확인되었다. 따라서 연산이 가장 쉬운 Inner Product 를 많이 사용한다.
Trainer: Major Training Issues
논문에서는 PLM-based Dense Retriever 를 학습하는 데에 있어 다음 세 가지 문제가 있음을 언급한다.
Issue 1: Large-Scale candidate space
- 큰 데이터셋을 확보하더라도 제한된 query 에 대한 positive가 될 수 있는 text는 제한적일 수 밖에 없다.
- 학습에 사용할 수 있는 자원이 무한한 것도 아니므로 Negative Sample 을 잘 뽑아서 학습에 사용하는 것이 중요하다.
- Negative Sample 을 어떻게 뽑아내느냐가 검색 성능을 높이는 데에 중요하게 작용한다는 점이 실험적으로도 입증되었다.
Issue 2: Limited relevance judgement
- Query와 그에 맞는 Answer로 구성된 데이터셋을 확보하기 어렵다.
- 이와 같은 구조로 만들어진 데이터셋이 있지만, Large model을 학습시키기에는 매우 부족하다.
- 또한 False Negative 로 인해 잘못된 데이터를 학습할 가능성이 매우 높다.
Issue 3: Pretraining discrepancy
- PLM은 일반적으로 retrieval task 가 아닌 다른 task 로 pre-training 된다.
- 따라서 Informational Retrieval Task에 맞춰 파인튜닝 하더라도 Sub-Optimal 에 머무를 가능성이 높다.
이와 같은 문제들과 관련된 연구로는 Negative Selection, Data augmentation, Pretraining for Dense Retrieval Models 등이 있다. 지금부터는 이들 각각을 자세히 살펴보자.
Trainer: Negative Selection
Dense Retriever의 업데이트 식에서도 보았듯이 학습에는 다수의 Negative Sample 이 필요하고, 이를 어떻게 구성하느냐가 학습 성능에 많은 영향을 미친다. 특히 논문에서 Dense Retriever 학습에 있어 첫 번째 Issue 로 제기된 Large-Scale candidate space 문제를 해결하기 위해서는 좋은 Negatives 를 효율적으로 샘플링하는 방법이 요구된다.
In-Batch Negatives
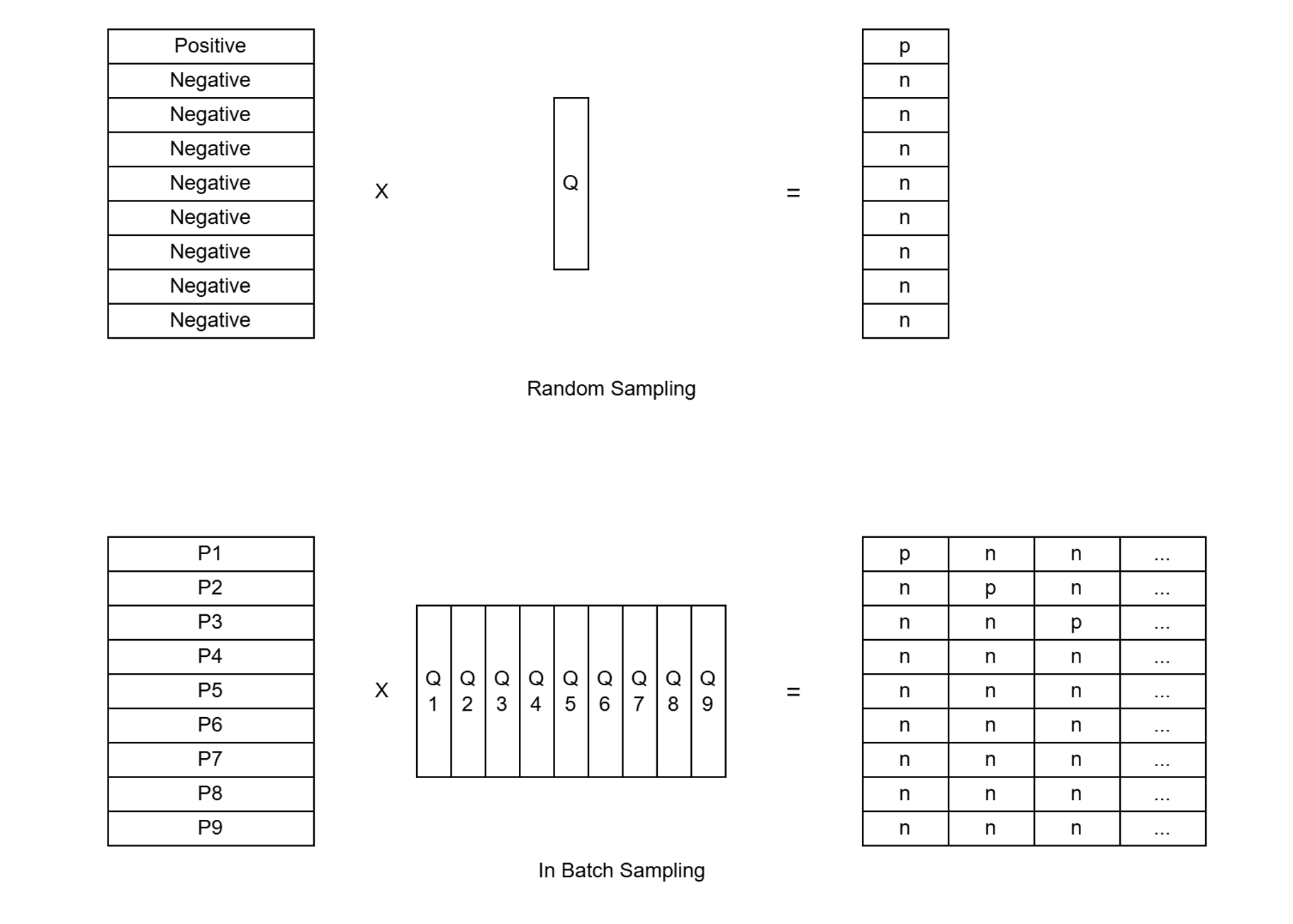
가장 쉬운 방법은 어떤 한 Query 에 대해 매번 Negative Sample 들을 랜덤하게 추출하는 것이다. 하나의 Query 에 대한 Positive Sample 하나와 다수의 임의 추출된 Negative Samples 로 Batch 를 구성하는 것이다. 하지만 이 방법은 한 배치당 하나의 Query 에 대해서만 학습할 수 있다는 점에서 비효율적이다.
In Batch Negative Sampling 은 Query/Positive text Pair를 Batch Size 만큼 샘플링하고, 각 Query 에 매칭되는 Positive Text 이외에는 모두 Negative text 로 취급하여 학습하도록 하는 방법이다. 이렇게 하면 배치마다 batch size - 1 만큼의 Negative Sample을 배치마다 확보할 수 있다는 점에서 Ramdom Sampling 방법과 동일하지만, 하나의 Batch 로 Batch Size 만큼의 학습을 진행할 수 있다는 점에서 메모리 효율적이다.
실험을 통해 In-Batch Sampling 에서 Negative Sample 의 갯수가 많아질수록, 즉 Batch 의 크기가 커질수록 성능이 좋아지는 경향을 보이기도 했다.
Cross-Batch Negatives
멀티 GPU 환경에서는 In-Batch Negatives 의 효율성을 더욱 높일 수 있다. 즉, 각각의 GPU 마다 할당된 Batch 들을 연산하여 embedding 을 계산한 뒤, gpu 끼리 통신하며 이를 공유하면 한 번에 n x (b - 1) 개 만큼의 Negative Sample 을 확보할 수 있다. 이를 Cross-Batch Negatives 라고 한다.
Hard Negatives
Hard negative 란 구별하기 어려운 Negatives, 즉 의미적으로는 유사하나 query와 무관한 텍스트를 뜻한다. 앞선 두 가지 방법은 Ramdom Sampling 을 통해 Negatives 를 구성하기 때문에 Hard Negatives 를 적절하게 처리하지 못한다는 한계를 가지고 있다. Hard negatives 를 골라 이를 집중적으로 학습에 사용하는 방법들에 대한 실험들이 있었고, 이를 통해 Retrieval 성능이 높아지는 것을 보여주기도 했다.
하지만 Hard Negatives 를 선정하는 것 또한 쉬운 문제가 아닐 것인데, 이와 관련하여 논문에서는 그 방법들에 대해 다음 세 가지로 분류하고 있다.
Static hard negative
- training 내내 고정된 negative selector 를 사용하는 방법
- lexically similar texts(e.g. BM25)를 사용하여 유사하지만 정답을 포함하지 않는 text 를 샘플링한다.
Dynamic hard negative
- training 과정에서 모델 성능에 따라 negative selector 를 동적으로 업데이트하는 방법
- 즉, 모델이 업데이트됨에 따라 어려워하는 Negative Sample 이 달라질텐데, 그에 맞춰 selector 도 업데이트해주는 것이다.
- Training - Test Discrepancy 문제, 즉 학습 시에 보지 못한 보다 복잡하고 비슷한 의미를 지니는 Negative의 처리에 강점을 보인다.
Denoised hard negatives
- Negative의 신뢰도와 난이도 등을 계산하고 이를 고려하여 Negative 를 샘플링하는 기법
- Hard Negatives를 찾아 학습에 사용하는 방법의 단점 중 하나는 False Negative 일 가능성이 높다는 점이다.
- Query와 유사도가 높지만 Positive로 라벨링되지 않은 Text를 Negative로 하여 학습에 사용하다보니 Positive 이지만 Negative 로 학습이 이뤄질 수 있다.
- 이러한 문제를 해결하기 위해 신뢰도를 별도로 측정하거나(RocketQA), 모호한 샘플을 배제(SimANS)하는 방법 등이 제안되었다.
Trainer: Data augmentation
Query-Answer 구조로 되어 있는 데이터는 사람의 판단이 들어가야 한다는 점에서 확보하기 어렵다. 특히 일반적인 도메인이 아닌 특수한 지식을 요구하는 경우에는 더욱 그러한데, Large Model 을 안정적으로 학습시키기 위해 필요한 데이터를 전문가들이 모두 레이블링하도록 하는 것은 제한된 자원으로는 불가능에 가깝다. 여기서는 Issue 2 와 관련하여 Dense Retriever 학습에 사용할 데이터 셋을 확보하는 방법을 다룬다.
Auxiliary Labeled Dataset
데이터가 부족하다면 다른 데이터셋을 추가하여 함께 학습에 사용하는 것을 쉽게 생각해 볼 수 있다. 이렇게하면 데이터 양이 늘어나는 것 뿐만 아니라 다양성도 높아져 모델의 일반화 성능 또한 높일 수 있다. Karpukhin et al에 따르면 여러 데이터셋으로 함께 학습한 경우 성능이 높아졌고, 본래의 데이터 셋의 크기가 작을수록 다른 데이터 셋을 함께 학습했을 때 성능 증가의 폭이 커지는 것을 확인할 수 있었다고 한다.
Knowledge distillation
잘 학습된 teacher network 로 unlabeled data 에 대한 pseudo label 을 생성하면 이를 student network 가 학습하는 방법을 말한다. Student Network가 label 을 학습하는지, score 를 학습하는지에 따라 Hard Label 과 Soft Label 로 나뉜다.
hard label distillation
- 특정 query에 대해 teacher가 높은 점수를 주면 positive, 낮은 점수를 주면 negative 로 분류하여 이를 학습함
- 애매한 점수의 text 는 모호하므로 학습에서 제외하여 false positive / negative 의 가능성을 줄임
soft label distillation
- teacher network 가 판단하는 Query와 Text 간의 상관성(relevance score) 자체를 Student network 가 학습하도록 하는 방법
- 다음과 같이 다양한 distillation function을 고려해 볼 수 있음. 이 중 KLD가 실험적으로 가장 좋았다고 함
- Mean Square Error
- KL divergence
- Max-margin
- Margin-MSE
Advanced Distillation method
Knowledge Distillation 의 문제점 중 하나는 teacher 와 student 간의 capacity 차이가 크면 학습이 잘 되지 않는다는 점이다. 이를 이를 해결하기 위해 Progressive distillation, dynamic distillation 등이 제안되었다.
Progressive distillation
- Teacher 모델의 성능과 capacity 를 점진적으로 늘려나가는 방법
- student 를 학습하면서 teacher 도 함께 학습함
- 대표적인 방법
- PROD: 학습이 진행됨에 따라 teacher 의 capacity 를 늘려나감
- teacher: 12 layer bi-encoder -> 12 layer cross-encoder -> 24 layer cross-encoder
- student: 6 layer bi-encoder
- CL-DRD: Curriculum learning 도입
- 처음에는 쉬운 문제를, 학습이 진행됨에 따라 어려운 문제를 학습할 수 있도록 하는 방법
- 여기서 쉬운 문제란 쿼리 - 텍스트 간 유사도가 낮은 샘플을 의미함
- PROD: 학습이 진행됨에 따라 teacher 의 capacity 를 늘려나감
dynamic distillation
- RocketQA-v2 에서 제안된 방법으로, retriever(student)와 reranker(teacher)가 상호 개선하며 학습하는 방식
- KLD를 사용하여 student의 분포와 teacher 의 분포가 크게 달라지지 않도록 만듦
Trainer: Pretraining for Dense Retrieval Models
대량의 데이터에 대해 unsupervised learning 으로 Pretraining model 으로 학습하여 다양한 Task 에 대해 높은 일반화 성능을 보이는 pre-training model을 기초로 하여 Fine-Tuning 을 통해 특정 Task 를 잘 수행하는 모델을 만드는 것은 Language Task 를 다루는 일반적인 방법론 중 하나이다. 하지만 많은 경우 task-specific optimization 이 부족하고, 이로 인해 sub-optimal performance 에 머무르는 문제가 자주 발생한다.
이러한 문제를 해소하기 위해 Task와 연관이 높은 Pre-Training 을 도입하는 방법들이 발전해왔다.
Task Adaptive Pretraining
가장 쉽게는 Retrieval task 에 보다 효과적인 task 들로 pretraining 하는 방법을 생각해 볼 수 있다. 하지만 대량의 labeled data 를 구하기는 현실적인 어려움이 많으므로 pseudo labeled data 를 생성하는 방식으로 해결한다. 대표적으로는 아래 두 가지가 있다.
- ICT(Inverse Cloze Task): 텍스트에서 임의로 한 문장을 쿼리로, 나머지를 매칭 텍스트로 간주하고 이를 학습하는 방법
- BFS(Body First Selection): 위키에서 첫 번째 body의 임의 문장을 query로, 이후 body 에서 임의로 추출하여 매칭 텍스트로 간주하고 학습하는 방법
Generation-Augmented Pretraining
Task adaptive pretraining은 원본 텍스트에서 임의로 query-text 를 추출하고 이를 학습하는 방식으로 이뤄진다. 하지만 label의 정확성과 관련해 문제가 있어 보인다. Generation-Augmented Pretraining 는 이에 대한 대안으로 직접 적절한 data 를 생성하고, 이를 모델이 학습하도록 한다.
Generation-Augmented Pretraining 에는 pipeline, end-to-end 두 가지 방법이 있다. 모두 large text 데이터에서 question-answer pair 를 추출 및 생성해내는 방법에 관한 것이다.
pipeline
- 단계적으로 Question-Answer Pair 를 생성하는 방법.
- 세 가지 단계
- answer extraction
- 전체 문서에서 핵심이 되는 문장을 뽑고, 이 핵심 문장을 질문으로 만들었을 때 답변이 될 만한 단어를 추출함
- question generation
- 핵심 문장과 답변이 될 단어를 seq2seq 모델에 입력으로 전달하여 답변에 맞는 질문을 생성함
- roundtrip filtering
- 생성된 질문 - 답변 쌍을 검증하고 필터링함
- answer extraction
- 성능이 올라가는 것을 실험적으로 검증함
end-to-end
- pipeline이 여러 단계를 나누었다면 end-to-end 는 단계를 나누지 않고 한 번에 처리함
- 하나의 seq2seq 모델이 있고, 문맥을 입력 받으면 그에 맞는 question, answer pair 를 생성함
Retrieval-Augmented Pretraining
Retriever를 사용하여 Context를 수집한 뒤, 이를 Pre Training 에 사용하는 방법도 있다. 대표적으로 REALM 이 있는데, 마스킹된 단어를 알아내는 테스크(MLM, masked language modeling)에 대해 Pre-Trianing 을 진행하면서, External Retriever 로 검색하여 얻은 문맥도 함께 활용하고, 단순히 단어를 맞추는 것 뿐만 아니라 문맥이 단어를 맞추는 데에 도움이 되었는지 여부를 Pretraining model 이 학습할 수 있도록 하는 방법이다.
Representation Enhanced Pretraining
Text의 Representation을 잘 뽑아내도록 Pre-Training 을 학습시키는 방법 또한 Informational Retriever를 위한 Pre-Training 모델을 만드는 데에 유효한 방법 중 하나이다.
Autoencoder
Auto Encoder 를 활용하여 CLS embedding 에 전체 텍스트 정보를 압축하도록 학습하는 방법이다. text 전체의 의미를 잘 내포하는 embedding 을 잘 만다는 것만으로도 Informational Retriever에 큰 도움이 되기 떄문이다. Condenser, TSDAE, RetroMAE 와 같은 방법들이 대표적이다.
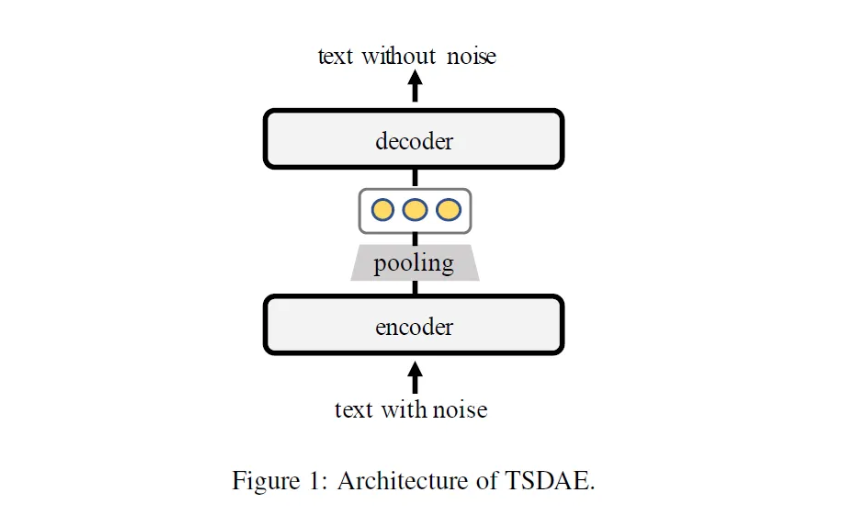
TSDAE 에 대한 간략한 설명을 덧붙이면 다음과 같다.
- Sentence Embedding 을 잘 추출해내는 방법에 관한 연구
- Informational Retrieval 문제를 타겟으로 하는 논문은 아님
- Transformer + Denoising Auto Encoder 구조
- Training time 에는 noise input 을 넣어 original output 을 복원
- Inference time 에는 encoder 만 사용하여 sentence 의 embedding 을 추출할 수 있음
Contrastive learning
contrastive learning 은 Image 도메인에서 주로 발전한 학습 방법으로, 유사한 특성을 가지는 input 들은 서로 가깝게 representation 을 생성하고, 다른 특성을 가지는 input 들은 represenation이 서로 멀리 위치하도록 학습하게 된다.
Contrastive learning은 augmentation 과 discrimination 두 가지 단계로 주로 구성된다. augmentation 단계는 Positive sample 을 만들어내는 단계로 crop, rotation 을 통해 기존 이미지와 유사한 이미지를 생성하게 된다. 이어지는 discrimination 단계에서는 original 및 이를 바탕으로 새로이 생성한 positive sample 들과, 랜덤 샘플링된 negative sample 을 구별하도록 모델을 학습하게 된다.
이미지에서는 crop, rotation 등을 통해 Positive sample 을 만드는 것이 가능했지만 언어에 대해서는 유사한 방법을 곧바로 적용하기 어렵다. 왜냐하면 문장에서 한 단어만 가리거나 바꾸어도 완전히 다른 의미를 가질 수 있기 때문이다. 언어 도메인에서 Constrative Learning 을 적용한 사례로는 대표적으로 다음 두 가지가 있다.
- SimCSE: sample text 에 서로 다른 drop out 을 적용하여 다양한 embedding 을 생성, 이를 positive 로 보고 학습 진행
- ConSERT: 토큰 셔플링, 어휘 삭제, 드롭아웃 등 조금 더 다양한 방법으로 positive 생성
Reference
- Zhao, W.X., Liu, J., Ren, R. and Wen, J.-R. (2022). Dense Text Retrieval based on Pretrained Language Models: A Survey. arXiv:2211.14876 [Accessed 12 Dec. 2022].
- Wang, K., Reimers, N. and Gurevych, I. (2021). TSDAE: Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning. 2022