Large Language Models meet harry potter
Summary
- 소설 속 캐릭터의 특성과 대화가 이뤄지는 맥락을 고려한 응답을 생성하는 것은 쉽지 않다.
- 적절한 추가 정보가 제공되면 이러한 어려움을 완화할 수 있다.
Align agent with specific character
ChatGPT와 같은 dialogue style 의 LLM 모델들이 많이 개발되었지만 캐릭터의 특성과 상황에 맞춰 답변하도록 만드는 것은 여전히 어려운 문제다. 예를 들어 소설 해리 포터의 4권, 불의 잔에서는 가장 친한 친구인 해리와 론이 반목하는 장면이 자주 등장하고, 이에 맞춰 갈등을 겪는 내용의 대화들이 주를 이루지만 LLM 모델들은 이러한 대화 내용을 생성하는 것에 자주 어려움을 겪는다.
보다 구체적으로 소설의 특정 캐릭터에 맞춰 LLM이 대화 내용을 생성하도록 만드는 것이 어려운 이유는 다음과 같다.
- LLM은 pre-training 과정에서 소설의 설정과 부합하지 않는 real-world knowledge를 이미 다수 습득한 상태이다. 이로 인해 소설의 특성이나 개별 캐릭터 만의 고유한 특성을 반영한 응답을 잘 생성하지 못한다.
- 복잡한 인간 관계, 특히 여러 관계를 동시에 갖는 경우가 흔한데 이를 활용하여 적절한 응답을 생성하는 것을 어려워 한다.
- 시간의 흐름에 따른 소설의 설정과 등장 인물 간의 관계의 변화를 잘 이해하지 못한다. (이는 기존에 관련 테스크를 수행하기 위한 목적으로 만들어진 데이터셋들이 가지고 있는 한계이기도 하다)
논문에서는 대화 생성에 도움이 될 만한 추가 정보(extensive annotation)를 제공하는 방법으로 이러한 어려움을 완화할 수 있다고 보고 있으며, 이를 실험적으로 보여주고 있다.
Task Definition
상황에 맞는 적절한 응답을 생성하도록 만들기 위해 중요한 정보들로는 다음 세 가지를 생각해 볼 수 있다.
- Conversation History(\(h\)): 앞선 대화의 내용
- Scene(\(S\)): 대화가 일어나는 상황에 대한 묘사
- Participant’s information(\(P\)): 참여자들에 대한 정보
논문에서는 위의 내용들에 맞게 Dataset을 구성하고, 논문의 주된 기여로서 이를 HPD(Harry Potter Dialogue)라는 이름으로 공개하였다.
Dataset Construction
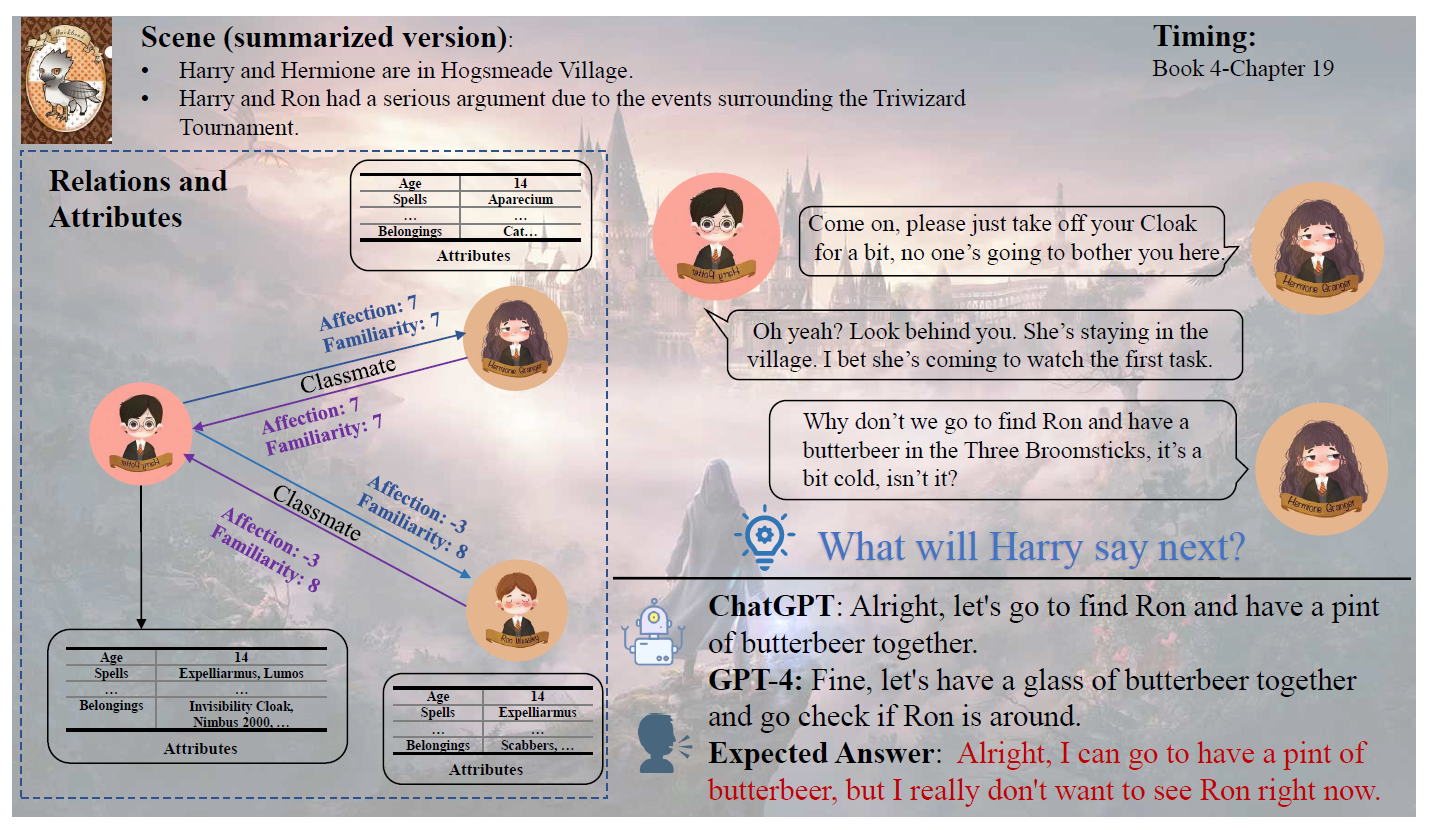
우선 해리의 응답을 적절히 생성하는 것을 목표로 설정하고, 이를 위해 소설 상에서 해리가 참여하는 모든 대화들을 수집하여였다. Training Set의 경우 해리가 참여하는 대화 중 multi-turn 으로 구성되어 있는 경우에 대해서만 수집하였고 이때 발화자가 누구인지 발화 단위로 레이블링 했다.
소설 속 대화들을 토대로 Test set 을 구성하면 정답이 확실하기 때문에 평가가 확실해지는 장점이 있지만 Knowledge Leakage Problem, 즉 Pre-training 단계에서 이미 해당 대화들을 학습했을 가능성이 존재한다. 이러한 문제를 없애기 위해 논문에서는 (1) 단 한 명의 발화자만 존재하는 대화 (2) 마지막 질문에 대한 답이 없는 채로 끝나는 대화, 두 가지 유형의 대화들을 모두 수집하고, 이들에 대한 해리의 예상 답변을 직접 생성하는 식으로 Test set 을 구성하였다.
이때 해리포터 전문가들로 구성된 Annotator 들이 직접 개별 예상 답변을 만드는 방법보다는 GPT-4를 사용하여 복수의 답변을 생성하고, 그것들 중 가장 적절해 보이는 것을 고르는 방식을 사용했다. 이를 통해 positive 뿐만 아니라 negative 샘플도 확보할 수 있었다고 한다.
Scene Construction
데이터 셋에서 제공하는 추가 정보 중 Scene 은 대화의 배경이 되는 상황들을 의미한다. Annotator 들이 직접 배경 묘사와 관련된 구문들을 직접 수집하였고, GPT-4 를 통해 한 번 요약한 뒤, 다시 Annotator 들이 교정하는 방식으로 이 부분을 채워 넣었다고 한다. 수집된 소설 속 구문들을 직접 모두 넣는 방식은 input limit 을 넘어가는 경우가 생길 수 있어 이를 해결하기 위한 방안이라고 할 수 있다.
Attribute and relations construction
마지막으로 대화 참여자들에 대한 정보는 크게 참여자 개인의 특성(Attribute)과 참여자 간의 관계(Relation) 두 가지로 나누어 보고 있으며, 참여자 특성 정보는 13개로, 참여자 간 관계 정보는 12개로 나누어 수집하였다. 구체적인 내용은 아래와 같다.
Attribute
- Inborn: Gender, Age, Lineage, Talents, and Looks
- Nurture: Achievement, Title, Belongings, Export, Hobby, Character, Spells and Nickname
Relations
- Binary Relations : Friend, Classmate, Teacher, Family, Lover, Opponent, Teammate, Enemy
- Discrete Relations:
- (1) Harry’s Familiarity with someone
- (2) Harry’s Affection for someone
- (3) someone’s Familiarity with Harry,
- (4) someone’s Affection for Harry.
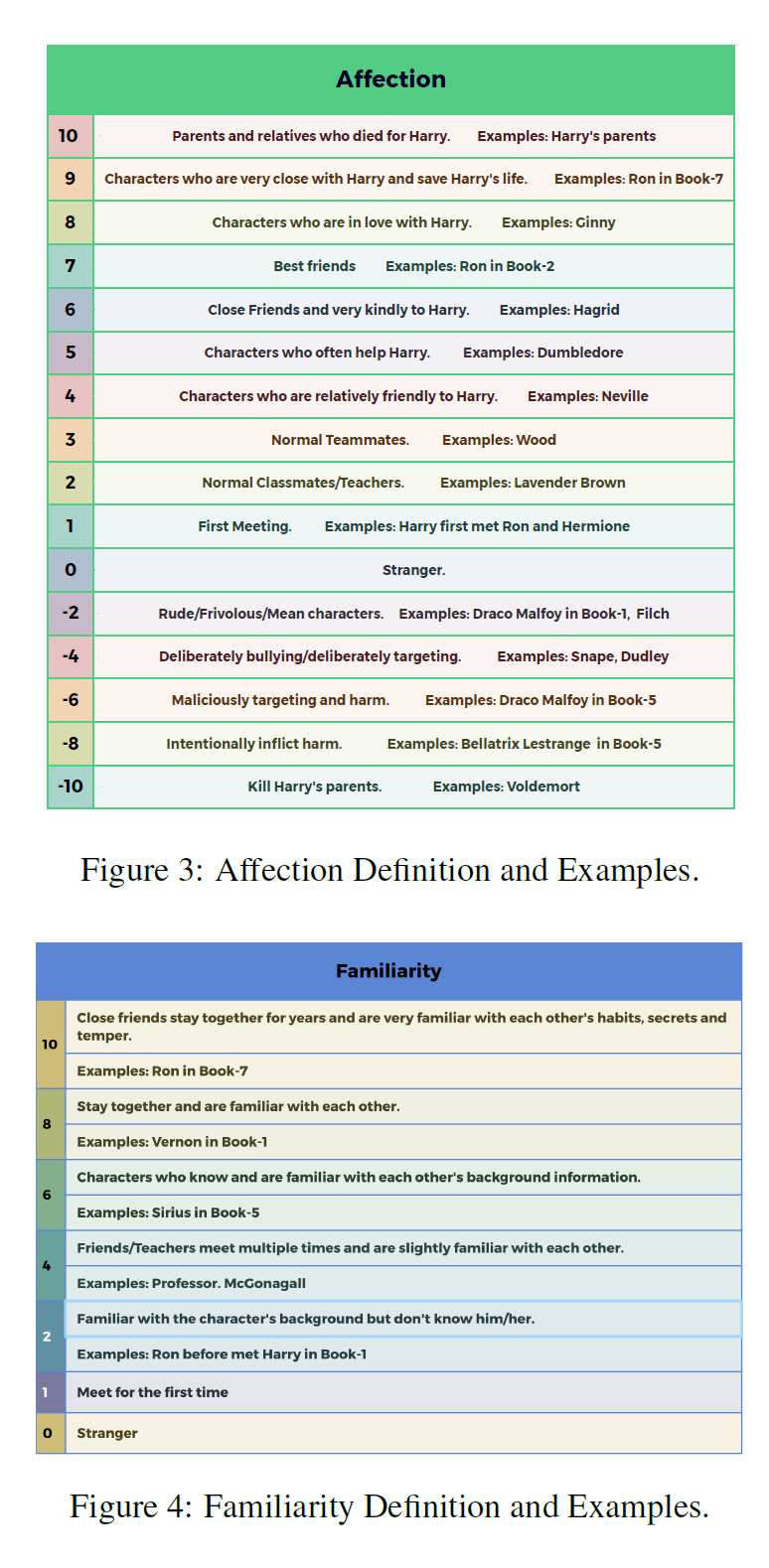
여기서 discrete relation 의 Familiarity 는 -10 에서 10까지 21 단계로, Affection은 0에서 10까지 총 11 단계로 구성된다. Familiarity 와 Affection 의 차이는 아래 두 가지 예시를 보면 쉽게 이해할 수 있다.
- Draco 는 Harry 를 잘 알지만(familarity), 해리를 적대시한다(Affection)
- Dumbledore 는 Harry 를 잘 알고, 애정을 가지고 있지만, 반대로 Harray 는 Dombledore 에 대해 잘 알지 못한다.
Experiments
수집한 데이터셋을 활용하여 Fine-Tune 방법과 In-Context Learning 방법 두 가지로 실험을 진행했다. 이때 사용한 모델들은 다음과 같다.
- Fine-tune: Alpaca(6B), ChatGLM-6B
- In-context: GPT3, ChatGPT(gpt3.5-turbo), ChatGLM(chat-glm-130B)
소설 속 개별 대화들이 가지는 특성들에 대한 정보들을 추가적으로 제공하는 경우 LLM 모델이 보다 캐릭터스럽게 답변할 것이라는 점이 논문의 주요 가정이므로, 이를 검증하기 위해 다음 두 가지 셋팅으로 실험을 진행했다.
- Base settting: Task에 대한 설명, 하나의 대화 예시, 대화 기록만 제공
- Rich-Persona setting(Per-Modl): in-context learning 시 base setting 과 함께 데이터 셋의 모든 정보들을 함께 제공


Evaluation
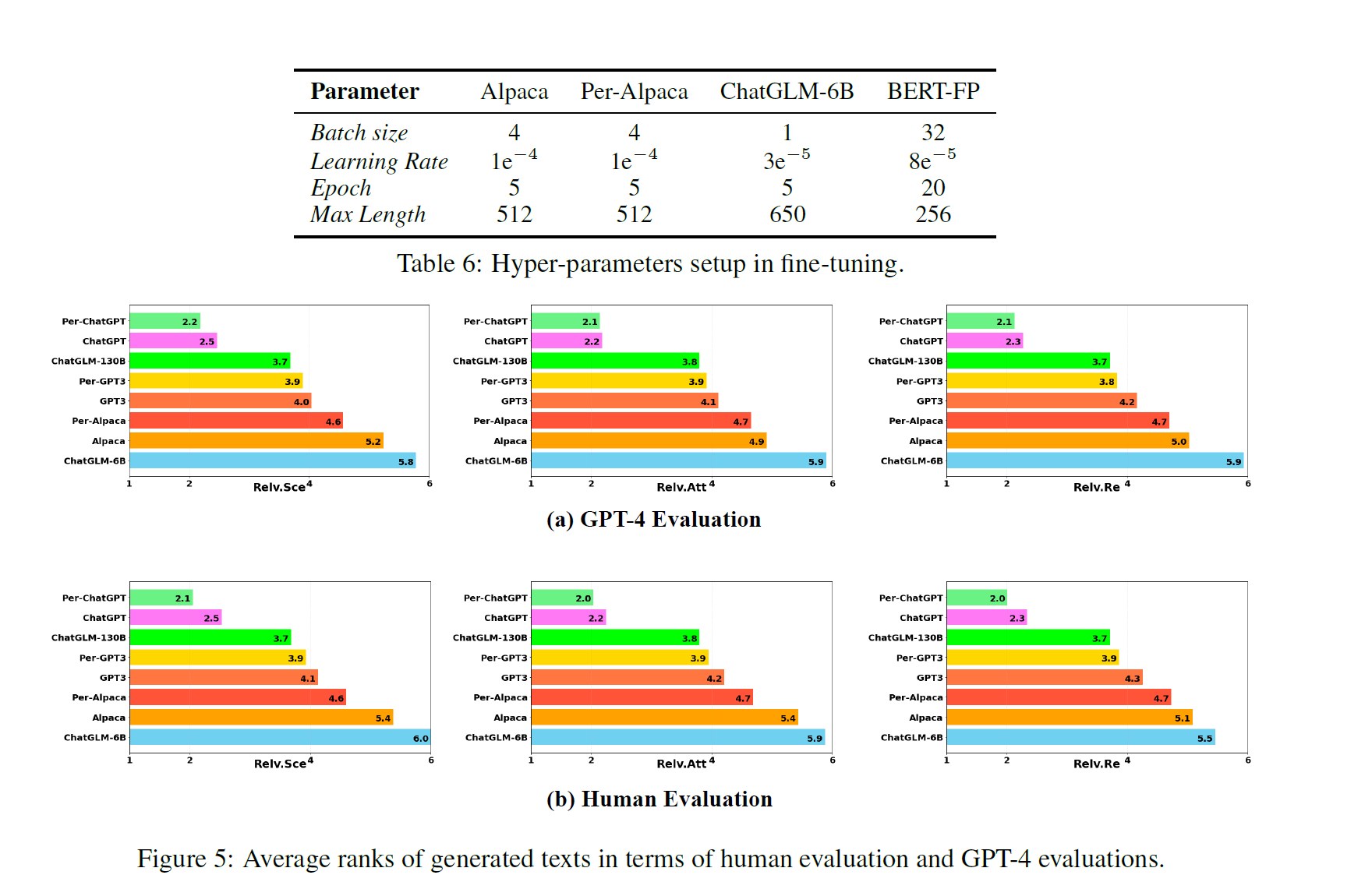
총 세 가지 방법으로 평가를 진행하고 있다.
1. Reference-based
Rough-L, Bleu-1과 같이 벤치마크를 활용한 평가 방법이다.
2. GPT-4 based
generated text 들에 대해 GPT-4로 평가하는 것이 유용하다는 연구 결과가 있는 만큼 GPT-4를 활용한 방법이다. 구체적으로 다음 세 가지 기준에 대해 개개의 답변들에 대한 랭킹을 매기는 방법으로 진행했다.
- Scene과의 연관성(Relevance with the Scene, Relv.Sec)
- Attribute와의 연관성(Relevance with the Attribution, Relv.Att)
- Relation과의 연관성(Relevance with the relations, Relv.Re)
3. Human-based
마지막으로 GPT-4가 매긴 랭크를 전문가들이 확인하고, 일부 수정하여 평가하는 방법이다.
Results
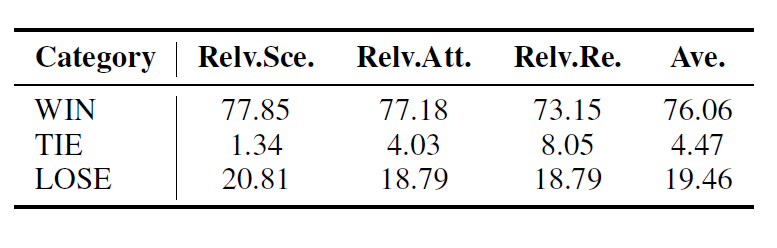
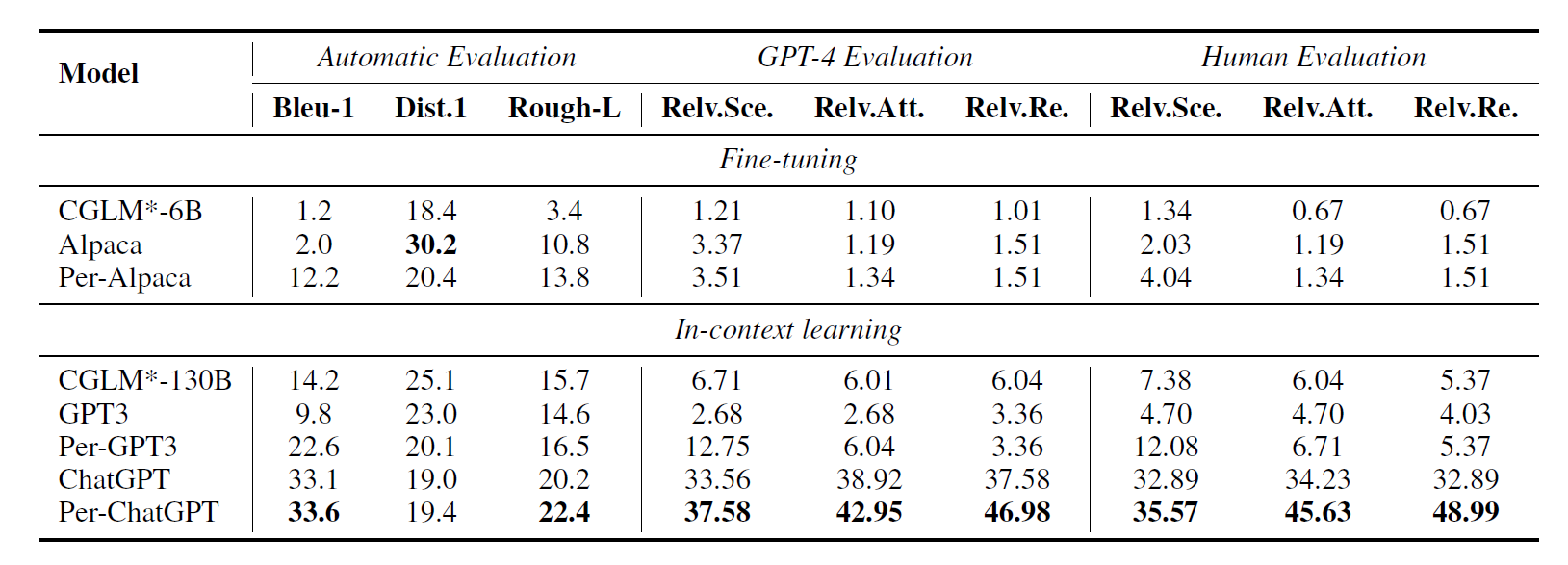
GPT-4와 Human based 평가에서 rich persona 모델들이 base setting 의 모델들에 비해 성능이 더욱 좋게 나왔으나, 사람과의 대결에서는 여전히 사람이 더욱 잘하는 모습을 보였다. 특히 사람보다 잘한 경우는 30%에 그쳤다는 점에서 Specific character 에 align 하도록 만드는 것은 여전히 쉽지 않다는 것을 확인할 수 있었다.