OpenAI o1
Introduction
2024년 9월 12일 OpenAI에서 기존 GPT-4o와 비교해 추론(Reasoning) 성능을 크게 높인 새로운 모델 o1을 발표했습니다. 추론 성능이 뛰어난 만큼 논리적인 인과 관계가 중요시되는 수학과 과학, 코딩 분야에서 특히 높은 성능을 보였습니다.
- 물리, 화학, 생물학 분야에서 박사 과정생과 유사한 수준의 추론 능력
- 국제 수학 올림피아드 수준의 수학 문제 해결 능력
- 기존 모델보다 훨씬 높은 성능의 코딩 능력
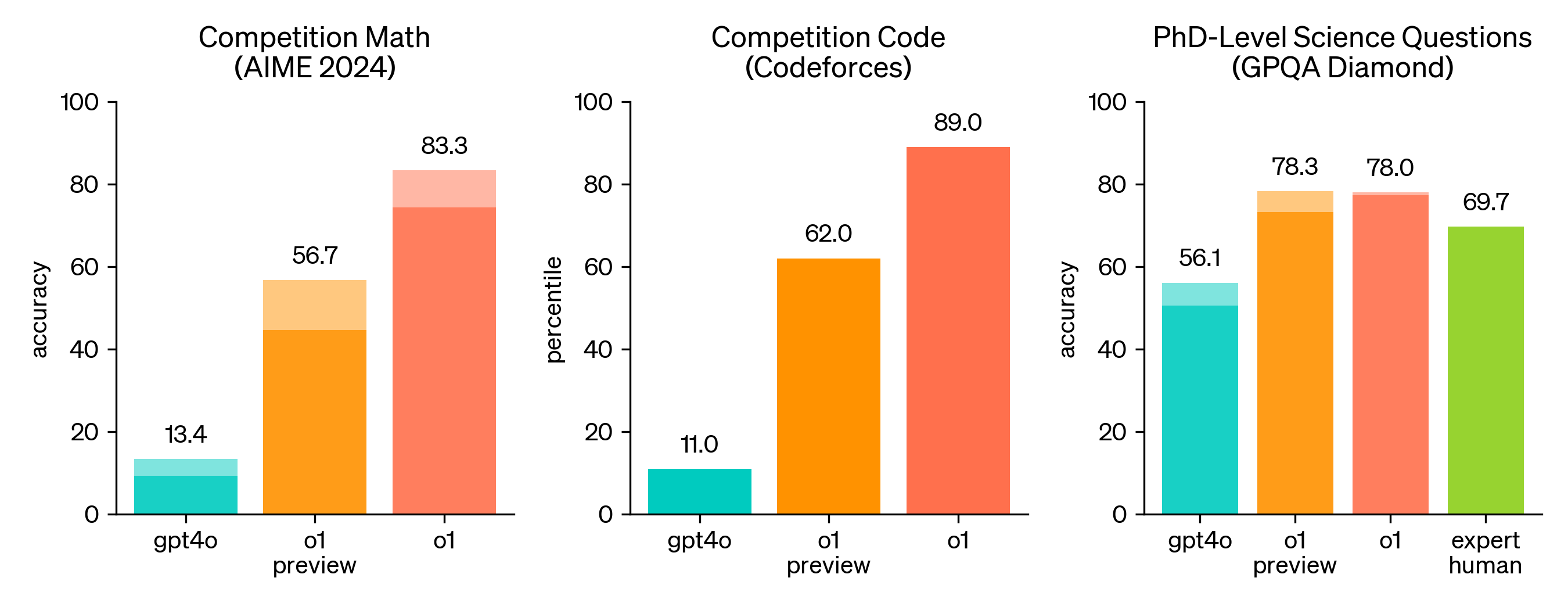
위의 그래프는 왼쪽부터 각각 수학, 코딩, 과학 분야와 관련된 벤치마크들에 대한 성능을 나타냅니다. 수학과 코딩 분야에서는 기존 모델인 gpt-4o 보다 크게 성능이 개선되었고, 과학 분야 벤치마크에서는 실제 전문가들보다 높은 수준의 성능을 보여주었습니다.
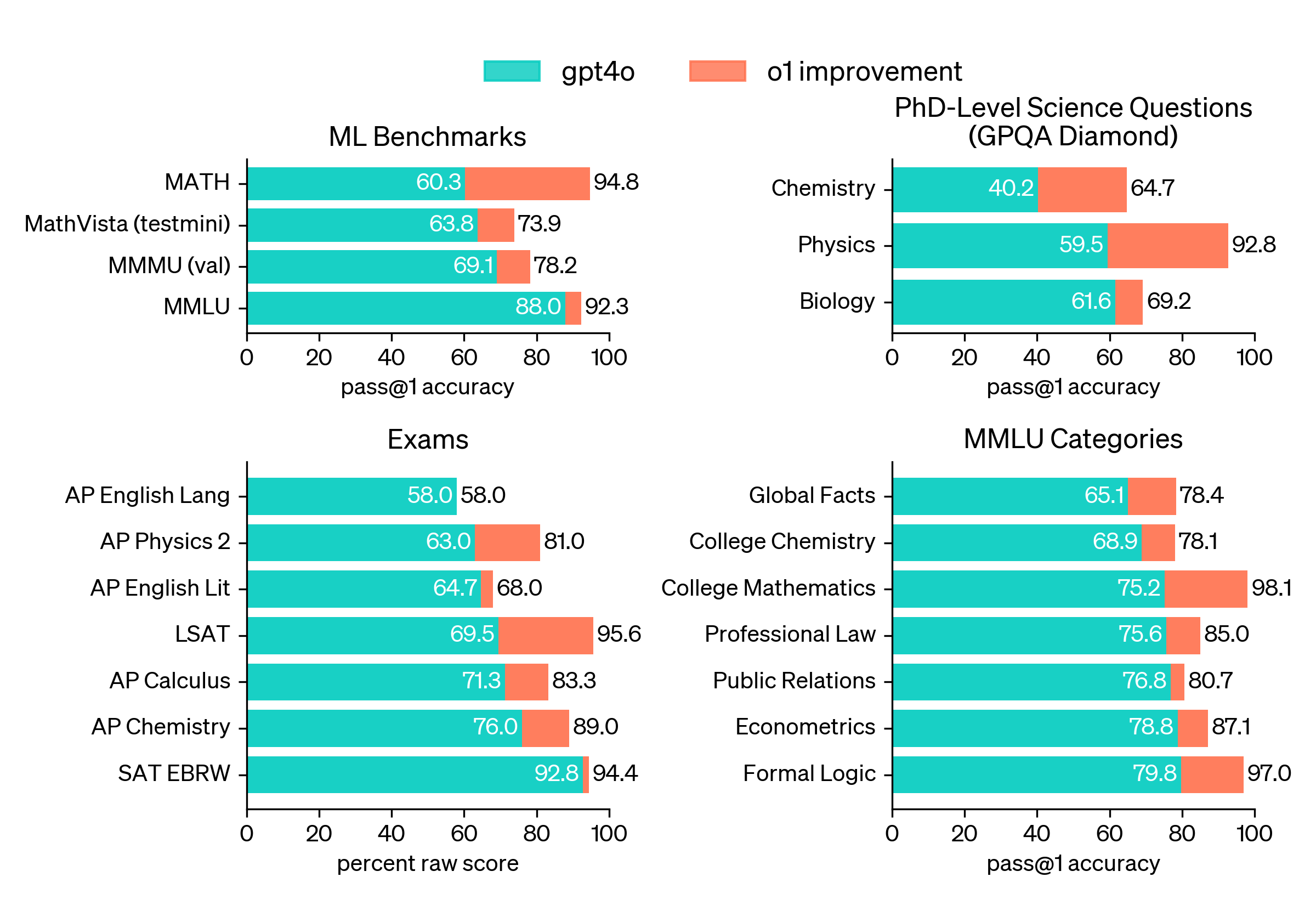
또한 머신러닝 모델의 성능 측정을 위한 목적으로 만들어진 벤치마크가 아닌 실제 사람을 위한 시험들에서도 기존 GPT-4o 모델보다 성능이 크게 개선되었습니다.
Our large-scale
reinforcement learningalgorithm teaches the model how to think productively using itschain of thoughtin a highly data-efficient training process. OpenAI - Learning to Reason with LLMs
아쉽게도 기존의 GPT 시리즈들은 논문 등을 통해 학습 방법을 공개하였지만 o1에 대해서는 구체적인 구현과 학습 방법을 공개하지 않고 있습니다. 단지 공식 홈페이지에서 강화학습(Reinforcement learning)과 Chain-of-Thought를 사용했다는 점만 언급하고 있습니다. 이와 관련하여 Reddit, X 등의 SNS 에서는 다음과 같이 o1의 학습 방법에 대해 다양한 추정을 내놓고 있습니다.

이미지 출처 - Reddit @r/LocalLLaMa, TechnoTherapist
Reinforcement Learning for LLM
강화학습과 Chain-of-Thought는 서로 다른 목적을 가지고 LLM 학습에 도입되었습니다. 강화학습은 OpenAI의 2022년 논문 Training language models to follow instructions with human feedback(Instruct GPT)에서 RLHF(Reinforcement Learning from Human Feedback)이라는 이름으로 언어 모델의 학습에 본격적으로 사용되었습니다.
RLHF는 from Human Feedback 이라는 표현에서 유추해 볼 수 있듯, 강화학습을 통해 사람이 선호하는 출력을 생성해내도록 언어 모델을 학습시키는 방법입니다. 언어 모델이 사용자가 원하지 않는 출력을 생성해내는 문제를 Alignment Prooblem 이라고 하는데, 이를 해결하기 위해 강화학습을 도입하였다고 할 수 있습니다.
Instrut GPT에 대한 자세한 설명은 다음 논문 리뷰 포스팅에 정리해 두었습니다.
Chain of Thought
반면 Chain of Thought는 추론(reasoning) 능력을 높이기 위한 방법입니다. 실제 인간이 추론이 필요한 문제를 해결하는 방법에서 착안하여 도입되었는데, 쉽게 말해 어려운 하나의 문제를 여러 개의 중간 문제들로 쪼개어 단계적인 추론을 유도하는 방법입니다.
Chain-of-Thought는 논문 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 에서 제안되었으며, 이에 대한 보다 자세한 설명은 여기에 정리해 두었습니다.
Additional Hints for o1
How reasoning works
OpenAI에서 제공하는 모델들과 API 등을 사용하는 데에 도움이 되는 문서들을 모아둔 OpenAI Platform에는 Reasoning 파트에서 o1에 대한 약간의 기술적인 설명들을 다음과 같이 덧붙이고 있습니다.
OpenAI o1 series models are new large language models trained with reinforcement learning to perform complex reasoning. o1 models think before they answer, and can
produce a long internal chain of thought before responding to the user. @OpenAI Platform
- o1은 강화학습을 사용하여 복잡한 추론을 할 수 있도록 한 모델이다.
- 사용자에게 응답하기 전 긴 internal chain of thought 를 생성한다.

The o1 models introduce
reasoning tokens. The models use these reasoning tokens to “think”,breaking down their understanding of the promptandconsidering multiple approaches to generating a response. After generating reasoning tokens, the model produces an answer as visible completion tokens, and discards the reasoning tokens from its context. @OpenAI Platform
- 하나의 큰 문제를 쪼개고, 여러 접근 방법들을 활용하여 다양한 답을 생성한다.
- 이 과정을 Reasoning Token 이라고 한다.
- 이렇게 생성된 답은 입력 프롬프트와 함께 다시 모델의 입력으로 전달한다.
- 이를 Context Window에 도달할 때까지 반복한다.
Guess
강화학습은 입력으로 주어진 상태에서 최적의 액션을 선택하도록 모델을 학습시키는 방법입니다. 이때 ‘최적 액션’의 기준은 현재 step에서의 Reward가 아닌 전체 Trajectory의 Return이 됩니다.
이를 위의 Hint와 연관지어 생각해보면 매 Turn 이 하나의 Step 이 되고, Input은 State라고 할 수 있습니다. 이때 각 Turn의 Input은 이전 Turn의 Input과 Output을 합한 것이므로 State는 매 Turn마다 지속적으로 바뀌게 되는 상황으로 가정해 볼 수 있습니다. 이렇게 되면 강화 학습을 위한 가장 기본적인 특성 중 하나인 Markov Property 도 만족하는 것으로 보입니다.
그렇다면 이때 Action은 어떻게 정의할 수 있을까요. 개인적인 추측으로는 내부적으로 매 Step 마다 전체 문제를 해결하는 데에 도움이 될 만한 질문과 그 답을 생성해내고, 그 중에서 하나를 선택하는 것이 Action이 될 수 있을 것 같습니다.

예를 들어 어떤 이미지를 입력으로 받으면, 이미지에서 Text의 위치를 찾아내어 반환하는 OCR 프로그램을 코딩하는 문제가 있다고 가정해 보겠습니다. 문제에 대한 정의를 입력 프롬프트로 받으면 모델은 가장 먼저 해당 문제를 해결하는 데에 도움이 될 만한 질문들과 그에 대한 해답을 생성합니다.
Turn 1
-------------
Input: 이미지를 입력으로 받으면, 이미지에서 Text의 위치를 찾아내어 반환하는 OCR 프로그램을 코딩해줘.
-------------
Question 1: 입력 받은 이미지를 어떤 순서로 처리하면 좋을까.
Answer 1: 일반적으로 Text를 찾아내는 Detection 을 먼저 수행하고 Recognition 을 다음으로 수행한다.
-------------
Question 2: 입력 받는 이미지의 타입으로는 어떤 것이 있을까.
Answer 2: 일반적으로 많이 사용되는 이미지 타입으로는 png, jpg, jpeg 등이 있다.
-------------
Question 3: 논문 리뷰 끝나고 뭐 먹을까.
Answer 3: 그냥 먹자는 거 먹자.
-------------
위의 질문과 답 세트 중 주어진 문제를 해결하는 데에 가장 도움이 될 만한 것은 1번 페어로 보입니다. 그럼 강화 학습 모델이 해당 페어를 선택했다고 가정하고, 다음 Turn은 다음과 같이 진행될 것으로 보입니다.
Turn 2
-------------
Input: 이미지를 입력으로 받으면, 이미지에서 Text의 위치를 찾아내어 반환하는 OCR 프로그램을 코딩해줘. 일반적으로 Text를 찾아내는 Detection 을 먼저 수행하고 Recognition 을 다음으로 수행한다.
-------------
Question 1: Image 데이터는 어떻게 구성되어 있을까.
Answer 1: 보통 이미지는 3 또는 4 채널로 구성되어 있다.
-------------
Question 2: Detection 시에 모델은 어떤 걸 쓰는 게 가장 좋을까.
Answer 2: Object Detection은 R-CNN, YOLO, SSD 등으로 구현이 가능하다.
-------------
Question 3: 저녁은 뭐 먹을까.
Answer 3: 점심부터 먹고 생각하자.
-------------
이와 같이 꼬리에 꼬리를 물며 적절한 질문과 그 답을 찾아나가다 보면 최종 정답을 찾아낼 수 있지 않을까 싶습니다. 끝으로 Reward Function 은 어떻게 정의하는 것이 가장 좋을지에 대한 생각을 덧붙이며 추측을 마무리합니다.
- Context Window 가 종료될 때까지 최종 정답을 내놓지 못하는 경우 논리적으로 줄 수 있는 최고의 Negative Reward를 부여한다.
- 최종 정답에 도달하는 데에 필요한 Step 수에 반비례하여 Reward를 부여한다.
- 최종 정답에 대한 Reward는 사람의 선호를 일부 포함하여 결정한다.
Reference
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J. and Lowe, R. (2022). Training language models to follow instructions with human feedback
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q. and Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models.
- OpenAI - introducing openai o1 preview
- OpenAI - learning-to-reason-with-llms
- Reddit - LocalLLaMA