Instruct GPT: Training language models to follow instructions with human feedback
Summary
- SFT(Supervised Fine-Tuning)과 RLHF(Human Feedback + PPO Algorithm)을 적용하여 사용자가 보다 선호하는 출력을 만들어내는 Langunage Model 을 만들 수 있다.
- SFT에서는 사람이 직접 작성한 응답을 생성하도록 학습하고, RLHF에서는 생성된 출력 값 중 사람이 직접 선호를 매기고, 긍정적인 응답을 강화하도록 학습한다.
- RLHF의 강화학습 업데이트 시 Pre-Training 에 사용된 데이터에 대해서도 학습을 진행하여 Benchmark 성능이 저하되는 Alignment Tax 를 줄일 수 있다.
Alignment Problem
GPT-3과 같은 Language model 의 문제점 중 하나는 때때로 사용자의 의도에서 벗어난 결과를 생성한다는 것이다. 이를 Alignment Problem 이라고 하는데, 대표적인 에시로는 다음과 같은 것들이 있다.
- 잘못된 사실을 지어내기
- 편향되거나 나쁜 단어 사용하기
- 사용자의 의도와 반대되는 결과 출력하기
- 사용자가 제공한 제약 사항 지키지 않기
이러한 문제가 발생하는 근본적인 원인은 Language Model 을 학습시키는 데 있어 단순히 Next Token 을 잘 예측하도록 Objective Function 이 구성되어 있기 때문이다. 즉, 사용자의 의도를 잘 따라 출력하도록 만드는 부분은 학습에 전혀 반영되지 않는다. 게다가 학습에 사용되는 데이터들 중 다수는 인터넷에서 가져온 것들이라는 점은 이러한 문제를 더욱 심화시키는 원인이 된다.
Instruct GPT 는 이러한 문제를 해결하는 데에 도움이 되는 한 가지 방식을 제안한다. 보다 구체적으로 GPT-3 을 RLHF(Reinforcement Learning from Human Feedback)으로 파인튜닝하여 사용자의 의도에 맞는 출력을 할 수 있도록 만들 수 있는지에 대해 실험한 결과라 할 수 있다.
Fine-Tuning with RLHF
RLHF(Reinforcement Learning from Human Feedback)란 사람이 직접 Trajectory 들에 대한 선호를 평가하고, 이를 학습에 사용하는 방법으로, OpenAI의 2017년 논문 ‘Deep Reinforcement Learning from Human Preferences’에서 제안되었다. 결과물들에 대한 사람의 선호를 학습하도록 하여 사람이 선호하는 결과물을 산출해내도록 만들겠다는 것이다.
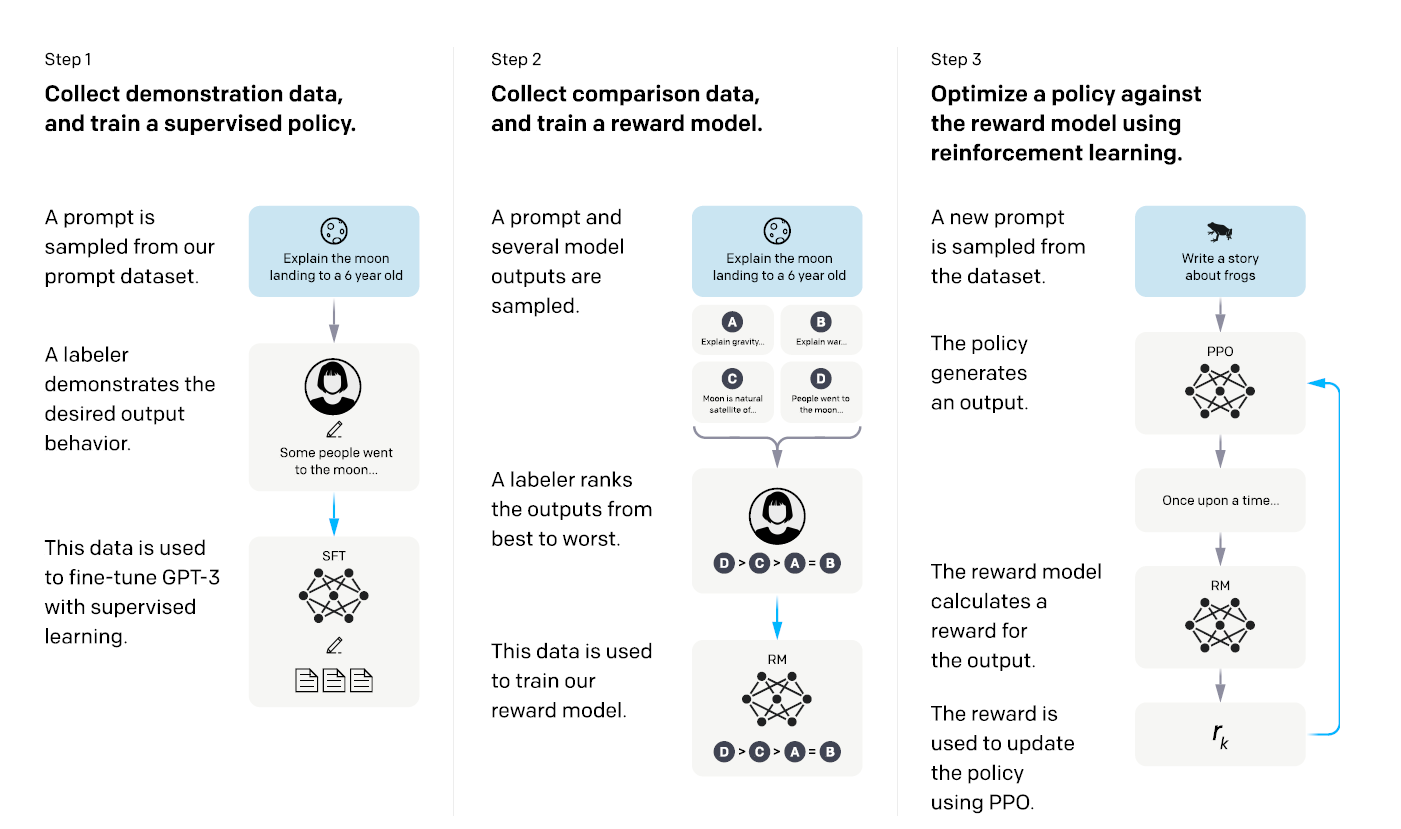
Language Model 에 이를 적용하기 위해 논문에서는 다음 3개의 step 을 구성하였다.
Step1: Supervised Fine-Tuning(SFT)
- Sample a Prompt: 프롬프트 데이터셋에서 프롬프트를 샘플링한다.
- Create demonstration: 사람(labeler)이 직접 프롬프트에 대한 응답(desired behavior)을 작성한다
- Fine-Tune GPT-3: 확보된 응답을 사용하여 Supervised-Learning 을 진행한다.
Step2: Training Reword Model(RM)
- Sample a Prompt: 프롬프트를 샘플링한다.
- Create responses: 동일 프롬프트에 대해 생성된 여러 출력 값을 생성한다.
- Rank responses: 여러 출력 값에 대해 사람이 선호도에 따라 순위를 매긴다.
- Train Reword model: 강화학습에 사용할 Reward model 을 선호 순위에 따라 학습을 진행한다.
Step3 Reinforcement Learning(RL)
- Sample a Prompt: 프롬프트를 샘플링한다.
- Reinforcement Learning: Step2 에서 확보한 Reward Model을 적용한 PPO 알고리즘으로 강화학습 모델 학습을 진행한다.
Dataset
위의 Step 1,2,3 을 보게 되면 모든 단계에서 Prompt Sampling 이 이뤄진다. 즉 좋은 프롬프트들이 많이 필요한 상황인데, 이를 위해 OpenAI Playground 를 활용하고, Labeler 가 직접 만들기도 하였다고 한다.
OpenAI Playground 에서는 model training 으로 사용될 것이라는 고지를 받은 사용자들을 대상으로 프롬프트를 수집하였다. 이때 아이디 당 200개로 수집 갯수를 제한하고, Training 데이터셋에 속한 아이디의 경우 Validation, Evaluation 데이터 셋에는 포함되지 않도록 하여 데이터의 편향을 줄이고, 일반화 성능을 잘 측정할 수 있도록 구성했다고 한다. 또한 개인 정보가 학습에 사용되지 않도록 필터링도 거쳤다.
위와 같은 방법들로 수집된 프롬프트들은 각 Step에 활용되었으며, 구체적으로 SFT 에는 13K개, RM 에는 33K개, 그리고 RL 에는 31K개를 사용했다.
SFT: Supervised Fine-Tuning
16 epoch 만큼 진행하였고, Residual Dropout(p=0.2)과 Cosine LR Scheduler 를 학습에 적용하였다. Residual Dropout 이란 identity branch에는 적용하지 않고, residual branch에 대해서만 dropout 을 적용하는 방법을 말한다. Cosine LR Scheduler 는 2017년 논문 “SGDR: Stochastic Gradient Descent with Warm Restarts”에 적용된 방법으로 다음 식에 따라 Learning Rate 를 업데이트하게 된다.
\[\eta_t = \eta_{\text{min}}^i + \frac{1}{2} \left( \eta_{\text{max}}^i - \eta_{\text{min}}^i \right) \left( 1 + \cos\left(\frac{T_{\text{cur}}}{T_i} \pi\right)\right)\]이러한 과정을 통해 확보된 모델은 RM 과 RL 단계에서 초기 모델로 사용된다.
RM: Reword Model
Reward Model은 SFT Model에서 Final Layer 를 제거한 상태로 초기화하여 학습을 시작하게 된다. Reward Model 의 Objective는 프롬프트와 그에 대한 응답이 주어졌을 때, 이에 대한 선호를 Scalar 값으로 계산하는 것이라 할 수 있다.
\[\text{loss}(\theta) = -\frac{1}{\binom{K}{2}} \mathbb{E}_{(x, y_w, y_l) \sim D} \left[ \log \left( \sigma \left( r_\theta (x, y_w) - r_\theta (x, y_l) \right) \right) \right]\]Objective Function을 뜯어보자. 우선 Dataset에서 \(x, y_w, y_l\)를 샘플링한다. 이때 \(x\) 는 프롬프트를, \(y_w\) 는 선호하는 출력 문장을, 그리고 \(y_l\)은 상대적으로 선호하지 않는 출력 문장을 의미한다. 그리고 \(r_\theta\) 는 reward function, \(\sigma\) 는 sigmoid function 이다.
그럼 Expectation 안의 수식 \(\log \left( \sigma \left( r_\theta (x, y_w) - r_\theta (x, y_l) \right) \right)\) 은 선호하는 답변에 대한 reward 와 그렇지 않은 reward 간의 차이가 크면 클수록 커지게 된다. 이때 맨 앞에 음수 기호가 있고, 이를 최소화하는 방향으로 \(\theta\)에 대한 업데이트가 이루어질 것이므로 선호하는 답변에 대한 reward 값은 크게, 그렇지 않은 답변은 작은 reward 가 나오도록 Objective Function 을 구성했음을 알 수 있다.
마지막으로 \(\frac{1}{\binom{K}{2}}\)가 남았다. 여기서 \(K\) 는 프롬프트로부터 생성한 출력의 총 갯수이다. RM 학습은 동일 프롬프트로 출력된 복수의 출력 값들에 대한 Labeler 의 선호 순위를 데이터 셋으로 이뤄지는데, 이때 \(K\) 개 중 2개씩 짝을 짓게 되면 상대적으로 선호하는 것과 그렇지 않은 것을 구별할 수 있게 된다. 즉, \(K\) 개의 요소에 대한 선호 순위는 \(\binom{K}{2}\) 개의 (\(x, y_w, y_l\)) 조합에 대한 개별 선호와 동일해진다.
이러한 관점에서 보면 \(\frac{1}{\binom{K}{2}}\) 는 출력 값이 많은 프롬프트가 학습에 너무 많은 영향을 끼치는 것을 조절해주는 텀이라고 할 수 있다. 이는 단순히 모든 프롬프트와 그 출력 값에 대한 조합들을 모두 Random sampling 하여 Mini-Batch 를 구성하지 않고, 동일 프롬프트로 나온 조합들은 함께 Mini-Batch 에 모두 포함시켜 학습을 진행한다는 점을 암시하는 것이기도 하다. 실제로 Random Shuffling 을 하였더니 Overfitting 문제가 있었고, 비용의 측면에서도 여러 번 \(x\)를 inference 해야한다는 점에서 불리했다고 한다.
끝으로 모델은 6B 사이즈의 모델을 선택했다. 175B 모델이 validation loss 측면에서는 보다 탁월했으나, 175B의 경우 PPO 적용 시 학습의 안정성이 떨어지고, PPO 업데이트를 할 때 비용이 너무 많이 드는 것을 고려했다고 한다.
이렇게 만들어진 Reward Model은 Reinforcement Learning 페이즈에서 활용된다.
RL: RLHF fine-tuning
RLHF 또한 Reward Model과 마찬가지로 SFT Model을 베이스로 한다. 이때 RL 모델은 PPO 알고리즘(Proximal Policy Optimization Algorithms)으로 업데이트하며, 이때 앞선 페이즈에서 업데이트 한 Reward Model을 사용하게 된다.
PG 계열의 PPO 알고리즘을 적용하였으므로, 학습의 단위는 Trajectory와 그에 대한 Return 이 된다. 여기서는 프롬프트를 입력 State로 삼고, Autoregressive 하게 생성되는 개별 Token 을 step 별 Action 으로 본다면, 강화학습의 관점에서 이 문제는 전체 Trajectory에서 단 한 번 Reward를 받는 문제가 된다.
\[\text{objective}(\phi) = \mathbb{E}_{(x, y) \sim \mathcal{D}_{\pi_{\phi}^{\text{RL}}}} \left[ r_{\theta}(x, y) - \beta \log \left( \frac{\pi_{\phi}^{\text{RL}}(y | x)}{\pi^{\text{SFT}}(y | x)} \right) \right] + \gamma \mathbb{E}_{x \sim \mathcal{D}_{\text{pretrain}}} \left[ \log \left( \pi_{\phi}^{\text{RL}}(x) \right) \right]\]여기서도 Objective Function 을 뜯어보자. 두 개의 항으로 이뤄져 있는데, 앞선 항을 PPO Gradient, 뒤의 항을 Pretraining Gradient 이라 한다. 학습은 이 둘의 합을 Maximize 하는 방향으로 이뤄진다.
PPO Gradient
\[\mathbb{E}_{(x, y) \sim \mathcal{D}_{\pi_{\phi}^{\text{RL}}}} \left[ r_{\theta}(x, y) - \beta \log \left( \frac{\pi_{\phi}^{\text{RL}}(y | x)}{\pi^{\text{SFT}}(y | x)} \right) \right]\]첫 번째 항은 \((x, y) \sim \mathcal{D}_{\pi_{\phi}^{\text{RL}}}\), 즉 어떤 프롬프트 \(x\)와 그에 대한 강화학습 모델 \(\pi\)로 생성한 출력 \(y\)의 샘플링에서 시작된다. Expectation 내의 첫 번째 항은 두 조합에 대한 Reward를 의미하는데 선호가 크면 클수록 값이 커진다. Reward Model의 출력 값이자, 강화학습 모델이 사용자의 선호에 더 맞는 출력 값을 만들어내도록 가이드하는 역할을 하게 된다.
Expectation 의 두 번째 항은 KL Penalty 항이다. 즉 두 개의 분포가 일정 수준 이상으로 벌어지는 것을 막는 역할을 하게 된다. SFT 모델의 성능이 우수한 만큼, 그것과 너무 동떨어진 방향으로 학습이 이뤄지는 것을 제한하는 것으로도 이해할 수 있다.
\[D_{\text{KL}}(p || q) = \sum_x p(x) \log \left( \frac{p(x)}{q(x)} \right)\]지금까지 Language Model 의 입장에서 바라보았다면 강화학습의 관점에서 Objective Function 을 이해해보자. PPO 알고리즘은 TRPO 알고리즘(Trust Region Policy Optimization)을 효율적으로 만든 알고리즘이다. 즉 ‘Trust Region’ 을 계산하는 방법을 간소화한 것인데, Clipping 과 KL Penalty 두 가지 방법으로 주로 구현된다.
\[\begin{equation} L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right]\end{equation}\] \[\begin{equation} L^{KL}(\theta) = \mathbb{E}_t \left[ r_t(\theta) \hat{A}_t - \beta \, \text{KL}\left[ \pi_{\theta_{\text{old}}}(\cdot | s_t) \,||\, \pi_\theta(\cdot | s_t) \right] \right]\end{equation}\]여기서는 두 번째 구현, KL Penalty 구현 방법을 적용하였다. 그리고 Trust Region 을 계산할 때 사용되는 기준 Policy 로는 SFT 모델을 사용한 것으로 볼 수 있다.
Pretraining Gradient
\[\gamma \mathbb{E}_{x \sim \mathcal{D}_{\text{pretrain}}} \left[ \log \left( \pi_{\phi}^{\text{RL}}(x) \right) \right]\]처음에는 첫 번째 항으로만 Objective Function 을 구성하였으나, SQuADv2, DROP 과 같은 일부 Public NLP Dataset 에 대해 성능 저하가 나타나 추가된 항이다. GPT-3 학습에 사용된 데이터 셋에서 Random Sampling 하여 Pretrained Dataset에 대한 분포도 잊지 않도록 만들어주는 역할을 수행한다.
Evaluation
Criteria: Aligned Model
Alignment problem 을 해결하기 위해 제안된 모델인 만큼 그 평가 또한 그에 맞춰 진행하였다. 우선 논문에서는 aligned model 을 다음 두 논문을 인용하여 다음과 같이 정의하고 있다.
- models that act in accordance with user intentions(Leike et al.(2018)).
- models to be aligned if they are helpful, honest, and harmless(Askell et al. (2021)).
쉽게 말해서 사람 말 잘 듣고, 안전하며 정직한 모델이라는 것이다. 두 번째 정의를 차용하여 다음 세 가지 요소들 각각에 대한 테스트 방법을 다음과 가이 고려하였다고 한다.
helpful
- 주관이 개입될 수 밖에 없는 영역으로, labeler의 판단으로 평가한다.
- labeler 또한 prompt를 작성한 사람은 아니기 때문에 실제 작성한 사람의 의도와 평가자의 판단 결과 간에는 divergence 가 존재할 수 있다.
honest
- closed domain task 에 대한 결과물들의 경향성(hallucination)과 Benchmark dataset(TruthfulQA) 으로 평가한다.
- 신뢰, 솔직함은 모델이 가지고 있는 ‘믿음(belief)’에 관한 문제인데, model 은 그 자체로 big black box 이기 때문에 들여다 볼 수 없기 때문에 어렵고 모호한 부분이 있다.
harmless
- Honest와 유사하게 어려움이 있다.
- 주관이 개입될 수 밖에 없는 영역으로, labeler의 판단으로 평가한다. 또한 RealToxicityPrompts, CrowS-Pairs 를 사용하여 객관적인 점수도 도출한다.
Evaluations by Human
사용자들은 InstructGPT의 출력 값을 보다 선호한다
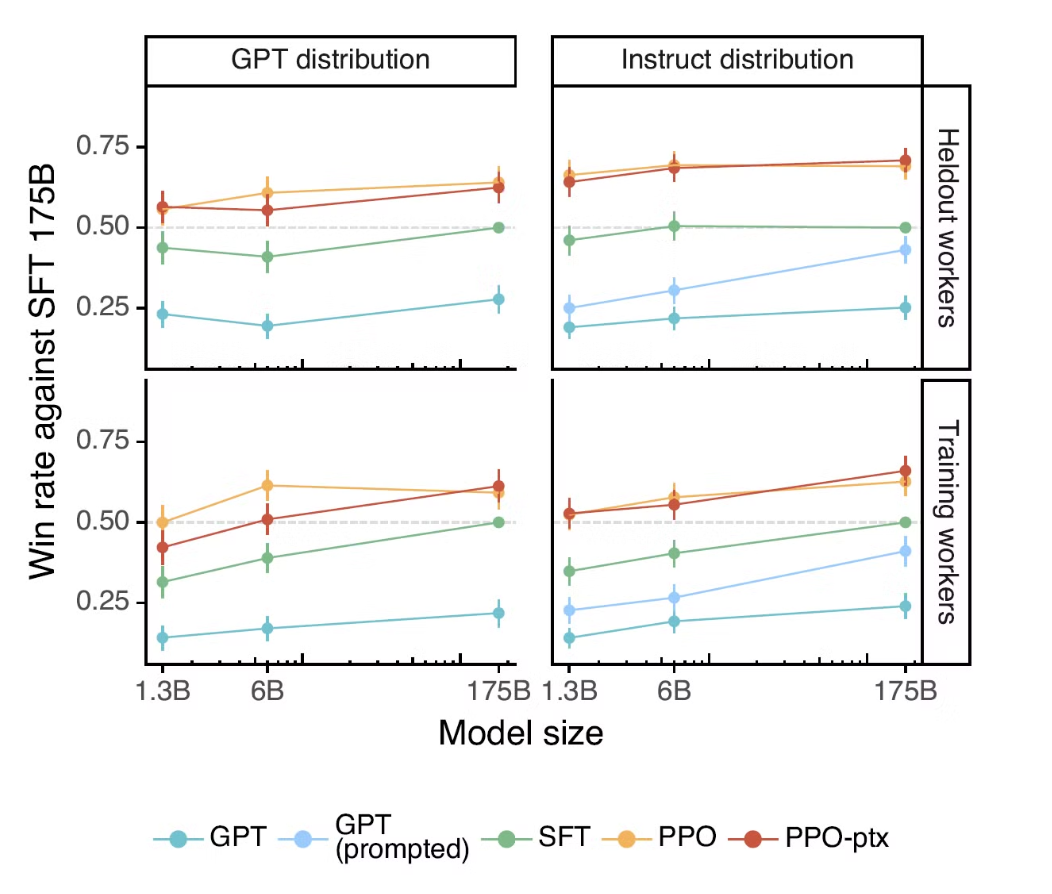
위 이미지는 GPT-3 SFT 175B 모델을 기준으로 Labeler가 직접 출력 값에 대한 선호도를 평가한 것이다.
- 전체적인 선호도는 GPT-3 < GPT-3 + few-shot prompt < SFT < PPO < PPO-ptx 순으로 좋았다.
- PPO, PPO-ptx 간의 선호도 차이는 크지 않았다.
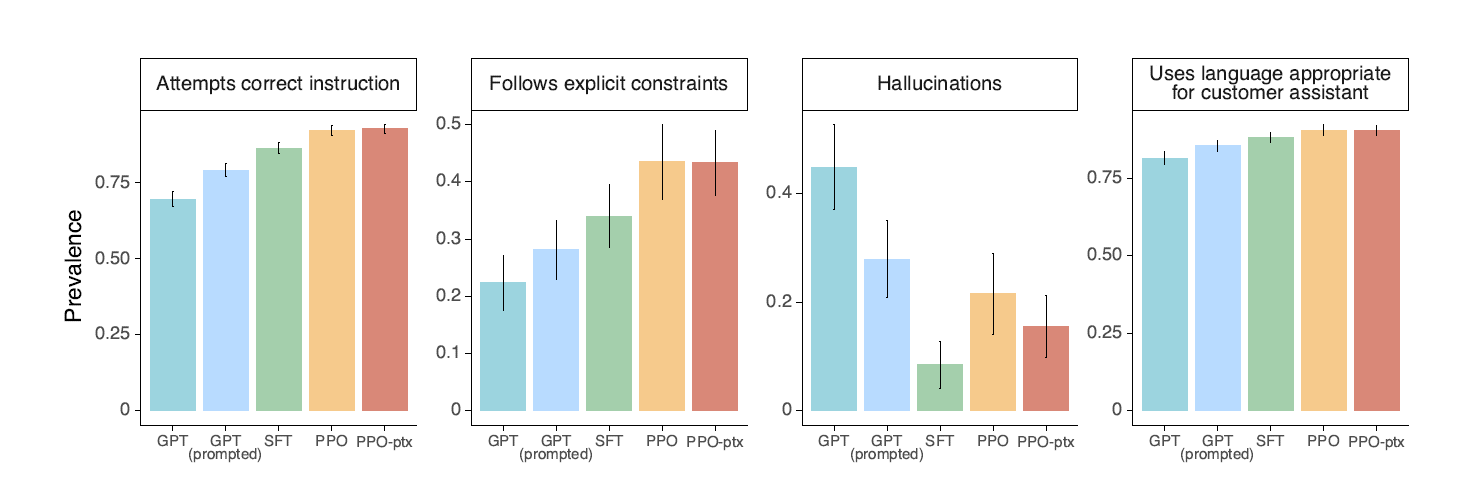
위 이미지는 개별 항목에 대한 선호도를 평가한 것이다.
- GPT-3 에 비해 사용자의 지시에 더욱 잘 따르게 되었음을 알 수 있다.
Held-out labeler 에 대한 평가 또한 GPT-3 보다 더 좋았다.
여기서 말하는 Held-out labeler 란, Training dataset 을 만들 때 참여하지 않은 사람들을 의미한다. 이들에 대한 선호도 평가로 일반화 성능을 확인할 수 있는데, 성능은 유사하게 나왔다. 이를 통해 training dataset 에 오버피팅되지는 않았음을 알 수 있다.
Evaluations by Benchmarks
trustfulQA 데이터셋 기준으로 GPT-3 보다 성능이 좋았다.
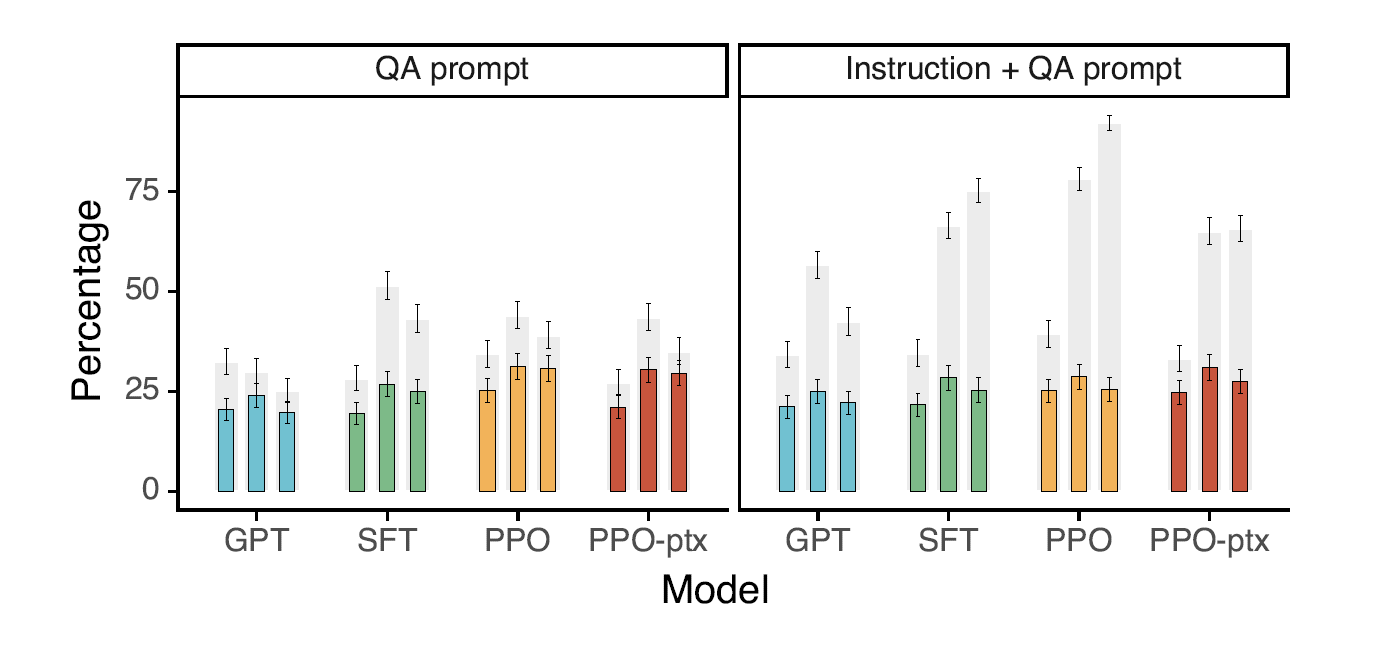
카테고리 셋은 차례대로 1.3B, 6B, 175B의 모델 크기를 나타낸다. 또한 회색 그래프는 truthfulness 결과를, truthfulness + informativeness 결과를 의미한다. 전반적으로 GPT-3에 비해 성능이 높아졌음을 알 수 있다.
참고로 Instruction + QA prompt 이란 정답을 모르는 경우 ‘I have no comment’로 응답하도록 instruction 을 제공했을 때의 결과를 뜻한다.
toxicity 를 기준으로 약간의 성능 향상이 있었으나, bias 에 대해서는 그렇지 못했다.
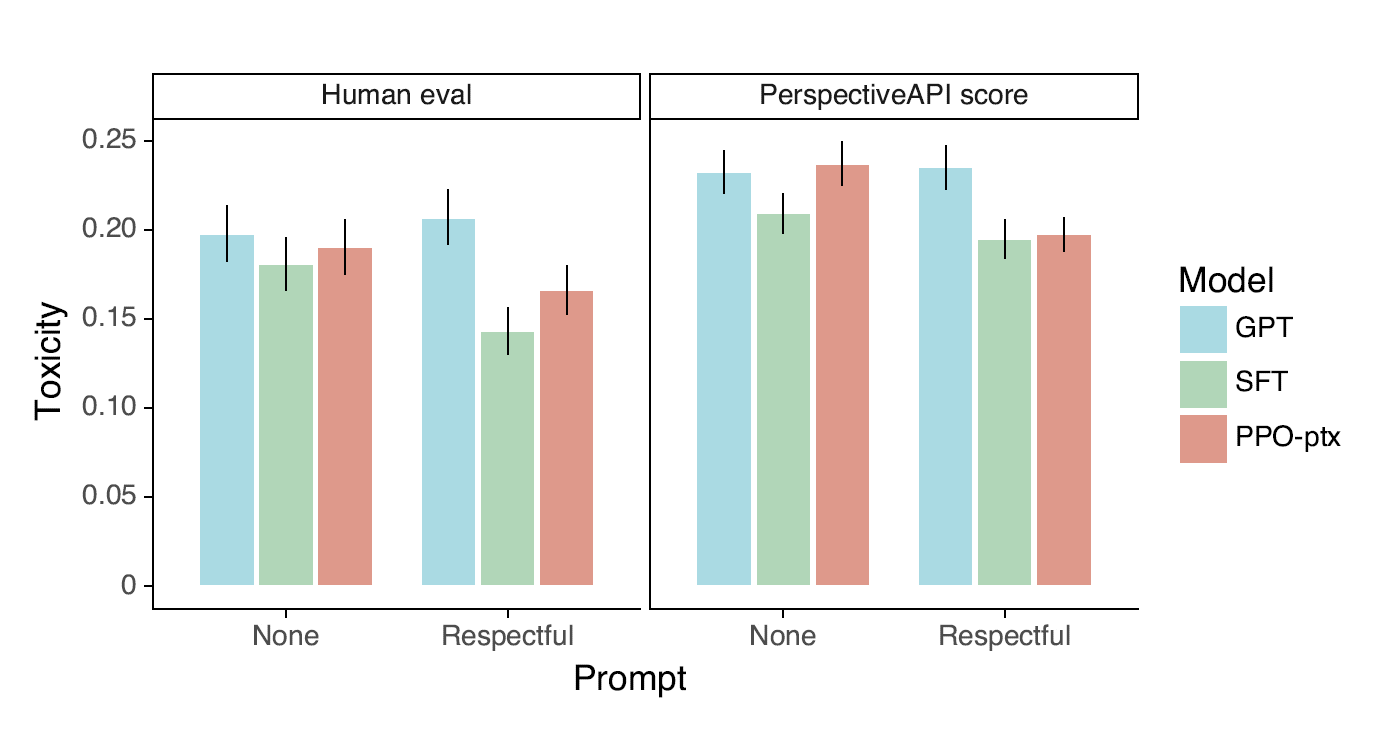
위의 subplot 중 오른쪽이 RealToxicityPrompts Benchmark로 산출한 결과를 보여준다. Benckmark 를 기준으로 일반 프롬프트에 대해서는 성능이 크게 차이가 없고, 오히려 SFT 모델의 성능이 가장 좋았다. 반면 Respectful 프롬프트에 대해서는 성능이 향상되었다.
theWinogender (Rudinger et al., 2018) and CrowS-Pairs (Nangia et al., 2020) datasets 을 사용하여 Bias 에 대한 평가도 진행하였는데, GPT-3에 비해 좋아졌다고 보기는 어려웠다고 한다.
RLHF fine-tuning procedure 를 개선하여 NLP dataset 에 대한 성능 저하 문제를 개선할 수 있다.
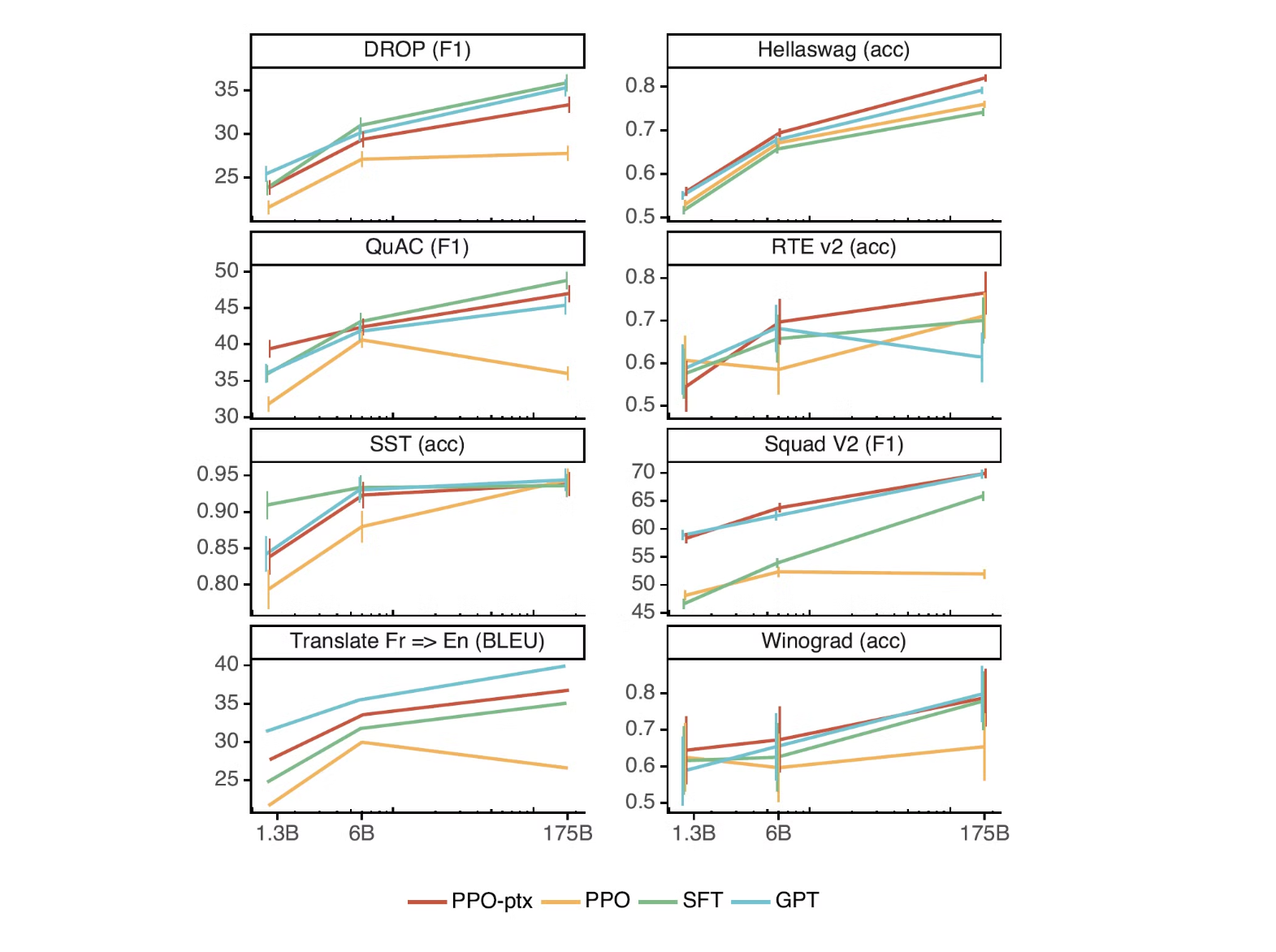
Alignment 를 진행한 후에 Benchmark 성능은 오히려 저하되는 것을 소위 Alignment Tax 라고 부른다. RL 업데이트에서 PPO Gradient 항과 더불어 Pretraining Gradient 항을 더한 것(PPO-ptx)이 이러한 문제를 해소하기 위해서인데, PPO-ptx가 PPO에 비해 실험한 모든 benchmark dataset에서 성능이 좋아졌음을 확인할 수 있다.
하지만 여전히 성능 저하는 존재하며, 이러한 부분들에 대해서는 개선이 필요하다.
Qualitative results
RLHF fine-tuning distribution 에서 벗어나는 데이터에 대해서도 잘 했다.
‘non-English language’, ‘code summarization’, ‘QA for code’ 등과 같이 학습에 사용되지 않은 데이터들에 대해서도 높은 일반화 성능을 보였다.
여전히 실수는 한다.
때때로 거짓 전제를 주었을 때, 이를 곧장 받아들인다거나, 많은 제약 사항을 잘 처리하지 못하는 등의 한계를 보였다.
Discussion
alignment research 관점에서 정리하자면, Instruct GPT 를 통해 다음 네 가지 결과를 도출할 수 있었다고 한다.
- pretraining 에 비해 model alignment 비용은 저렴한 편이다
(학습량 기준이지 labeler 고용 비용은..?) - aligned model 도 일반화 성능이 크게 저하되지는 않는다.
- fine-tuning 에 pretrained data 를 적용하여 Benchmark 성능 저하 문제를 줄일 수 있다.
- real world 문제에 대해서도 성능 향상을 보였다.
Reference
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J. and Lowe, R. (2022). Training language models to follow instructions with human feedback..
- Christiano, P., Leike, J., Brown, T.B., Martic, M., Legg, S. and Amodei, D. (2017). Deep reinforcement learning from human preferences.
- Loshchilov, I. and Hutter, F. (2016). SGDR: Stochastic Gradient Descent with Warm Restarts. -Schulman, J., Wolski, F., Dhariwal, P., Radford, A. and Klimov, O. (2017). Proximal Policy Optimization Algorithms.
- Leike, J., Krueger, D., Everitt, T., Martic, M., Maini, V. and Legg, S. (2018). Scalable agent alignment via reward modeling: a research direction.
- Askell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Kernion, J., Ndousse, K., Olsson, C., Amodei, D., Brown, T., Clark, J. and McCandlish, S. (2021). A General Language Assistant as a Laboratory for Alignment.
- Lin, S., Hilton, J. and Evans, O. (2021). TruthfulQA: Measuring How Models Mimic Human Falsehoods.