GPT-3: Language Models are Few-Shot Learners
Summary
- Parameter Update 없이 입력 Context 로 Demonstration 을 함께 제공하는 방법을 In-Context Learning 이라고 한다.
- 일반화 성능이 떨어지고, 다수의 labeled data 를 필요로 하는 Fine-Tuning 없이 In-Context Learning 만으로도 높은 성능을 확보할 수 있다. 다만 Fine-Tuning 모델에 비해 성능은 다소 떨어진다.
- 모델의 크기가 크면 클수록, Demonstration 을 많이 제공할수록 모델의 성능이 좋아진다.
Fine-Tuning
자연어 처리 분야에서는 지금까지 다양한 패러다임들이 있어 왔다. 최근에는 pre-training 모델을 Task-agnostic 하게 먼저 학습시킨 뒤, 사용자가 목표로 하는 Task 에 대해 Task-specific 하게 Fine-Tuning 하는 방법이 가장 주도적이다. 이름에서부터 알 수 있듯이 GPT(Generative Pre-trained Transformers)가 이러한 패러다임의 핵심적인 위치에 있다고 할 수 있다.
하지만 이와 같은 Fine-Tuning 방식 또한 여러가지 문제를 안고 있는데, 논문에서는 다음 세 가지를 주로 언급하고 있다.
- 새로운 Task 에 대해 학습을 진행하기 위해서는 그에 맞는 새로운 labeled large dataset 이 필요하다. 현실 세계에는 수없이 많은 종류의 Task 가 있는데, 매번 새로운 데이터셋을 확보하는 것은 분명 부담스럽다.
- Fine-Tuning 방법론은 가짜 상관관계(Spurious correlation)으로 인한 문제의 가능성을 높인다. 특히 Pre-Training 단계에서 거대한 크기의 데이터를 학습하게 되지만, 그것에 비해 Fine-Tuning 에서 사용되는 데이터의 양이 작은 학습 구조는 이러한 문제에 더욱 취약하다. 따라서 Benchmark 성능은 높을지라도 실제 사용자는 그렇지 못하다고 느낄 가능성, 즉 일반화 성능이 떨어지는 문제가 나타날 수 있다.
- 사람이 학습하는 방법과 비교해 볼 때 너무나도 비효율적이다. 사람은 소수의 예제만으로도 Task 의 특성을 파악하고, 그에 따라 해결할 수 있지만 그에 비해 Fine-Tuning 은 너무나도 많은 데이터와 학습을 필요로 한다.
Without Fine-Tuning
이러한 문제를 극복할 방법으로 논문에서는 Learning to learn 을 목표로 하는 Meta Learning 에 관심을 가지게 되었다고 한다. Meta Learning 에서는 다양한 Task들과 동시에 패턴 인식 능력을 함께 학습하여, 여러 Task 에 대해 괜찮은 성능을 보여주도록 Multi tasks 문제를 해결하려 하는데, GPT-3 에서는 이를 언어 모델에도 적용하는 것을 시도해 보겠다는 것이다. 즉, Training Time 에 다양한 NLP Task 의 해결 방법과 더불어 각각의 문제가 가지는 패턴 자체에 대해서도 학습하는 데에 성공한다면, Fine-Tuning 이 없어도 충분히 좋은 모델을 만들 수 있을 것으로 보는 것이다.
물론 다양한 Task 를 한꺼번에 모두 학습하기 위해서는 모델의 성능을 더욱 높아질 필요가 있다. Transformer 모델의 크기를 크게 키우면 키울수록 그 성능이 높아진다는 증거가 있는 만큼 GPT-3 에서는 GPT-2 등과 같은 기존의 모델들과 비교해 그 크기를 크게 키워 175 Billion 개의 파라미터를 가지는 모델을 학습에 사용했다고 한다.
In-Context learning
그렇다면 어떻게 “다양한 Task들과 동시에 패턴 인식 능력을 함께 학습”하도록 만들 수 있을까. 논문에서는 아래의 그림을 통해 설명하고 있다.
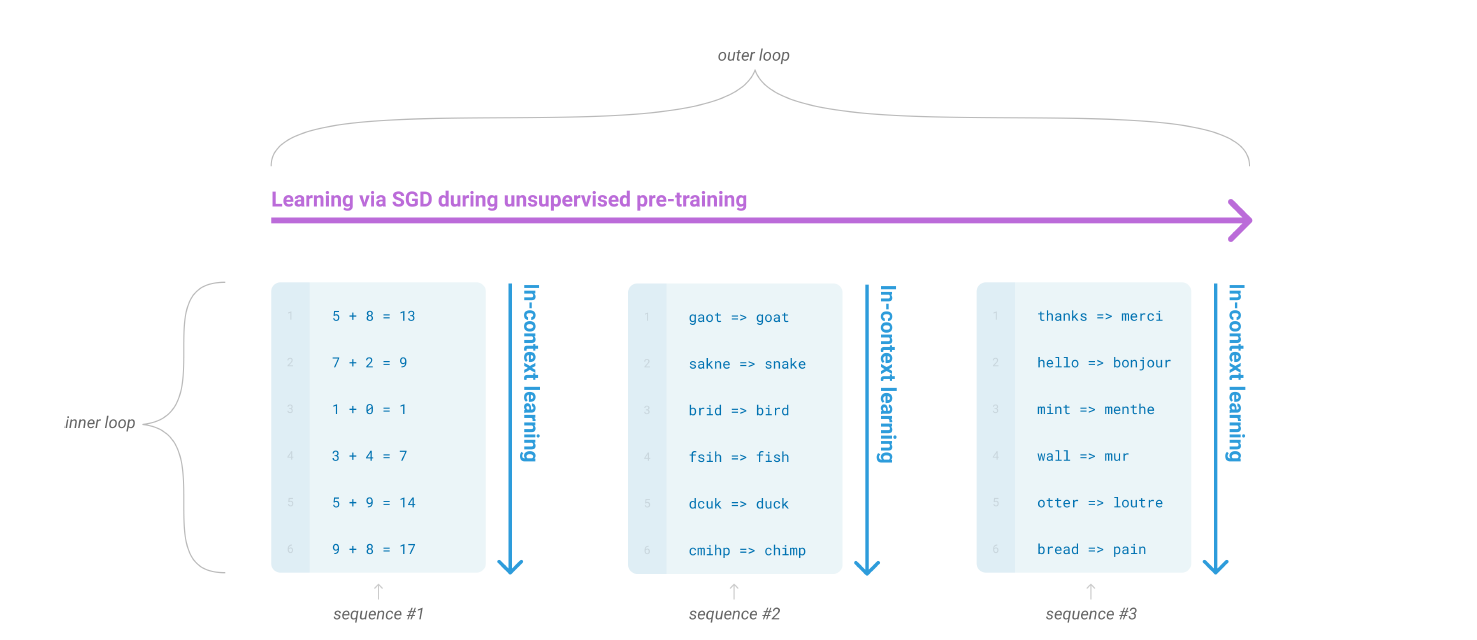
그림을 보게 되면 Inner Loop 와 Outer Loop 두 개의 루프가 있다. Outer loop 는 일반적인 Generative Language Model 의 학습에 사용되는 방법을 지칭하는데, Large Dataset 에 대해 next word prediction, missing word prediction 의 training loss 를 줄이는 방향으로 실제 모델 파라미터를 업데이트하게 된다.
반면 Inner Loop 에서는 Language Model 에 질문할 문제와 동일한 패턴의 문제들의 Sequence 를 입력으로 전달하고 있다. “딸기는 빨간 색이다. 바나나는 무슨 색인가?” 와 같이 예시를 주고 문제를 풀도록 하면 더 잘 풀 수 있는 것과 같은 원리다. 이를 in-context learning 이라고 한다.
in-context learning 은 Inference Time 에 이뤄지며, 따라서 Model Parameter 에 대한 업데이트가 전혀 없다. 하지만 언어 모델이 Inference/Generate 할 때 제공되어지는 Context 를 업데이트하여 결과적으로 Output 의 질을 높이는 학습 방법이라고 할 수 있다.
두 학습 방법을 표로 정리하여 비교해보면 다음과 같다.
| Pre-Training | In-Context Learning | |
|---|---|---|
| Phase | Training Time | Inference Time |
| Objective | 대규모 텍스트 코퍼스에서 일반적인 패턴 학습 | 주어진 Context 사용하여 특정 작업에 학습된 패턴 적용 |
| Data | 방대한 양의 다양한 데이터셋 | 추론 중에 제공된 특정 example 들 |
| Update | SGD 로 모델 파라미터 업데이트 | 모델 파라미터는 고정됨 |
| Learning Method | Unsupervised learning, Next Word Prediction | 주어진 Context를 기반으로 한 적응(Adaptation) |
| Generalization | 다양한 작업에 걸쳐 패턴을 일반화 | Context 를 기반으로 특정 작업에 적응 |
Zero-shot, One-shot and Few-shot
In-Context learning 은 주어지는 Demonstration 의 갯수에 따라 다음과 같이 세 가지로 나누어 볼 수 있다.

Few-Shot
Task 에 대한 설명과 더불어 K 개, 즉 복수 개의 Demonstration 을 context로 제공하는 경우를 말한다. 논문에서는 10개에서 100개 사이의 Demonstration을 제공하였다고 하며, Context window 의 크기에 따라 정했다고 언급한다.
One-Shot
Task 에 대한 설명과 더불어 1개의 Demonstration 을 제공하는 경우를 말한다. 즉, K=1 인 경우이다. 사람 간의 의사소통에 있어서도 설명과 한 개의 예시를 제공하는 경우가 가장 흔하기 때문에 Few-Shot, Zero-Shot 과 구별하여 실험했다고 한다.
Zero-Shot
Task에 대한 설명만 Context 로 제공하는 실험 설정이다. 예시가 전혀 없기 때문에 경우에 따라서는 사람이 수행하기에도 어렵다고 느끼는 Task 가 있기도 했다.
Fine-Tuning
위 이미지에서 알 수 있듯이 논문에서는 이들과 Traditional Fine-Tuning 을 비교하고 있다. Task에 맞춰 추가적인 Weight Update 가 이뤄지는 Fine-Tuning은 높은 성능을 보여줄 수 있지만, Task-Agnostic performance에 논문의 초점을 맞추고 있는 만큼 Fine-Tuning 을 진행하고 모델 성능을 비교해보지는 않았다고 한다.
Training
GPT-3 은 파라미터의 갯수는 175 Billion 으로 크게 증가했지만, 전체적인 모델의 구조나 특성은 GPT-2 와 동일하게 유지하고 있다. 단, 모델 크기에 따른 성능 비교를 위해 다양한 파라미터 크기의 모델들을 학습시키고, 동일한 조건에서 실험을 진행했다고 한다.
데이터 셋의 경우 Common Crawl 데이터 셋을 활용하였다. 하지만 오리지널 버전은 데이터의 양은 충분하나, 그 질이 떨어진다고 판단하여 다음 세 가지의 추가 작업을 진행하였다.
- 고품질의 말뭉치(High-Quality Reference Corpora)와 비교해 유사도가 높은 버전의 filtered Common Crawl 데이터셋을 확보함
- 문서 간, 데이터 셋 간 중복 확인을 통해 중복을 제거하고, Validation set 의 integrity 를 높이기 위해 학습 시 사용된 데이터가 들어가지 않도록 확인함
- 고품질의 말뭉치를 데이터셋에 추가하여 데이터의 다양성을 높임
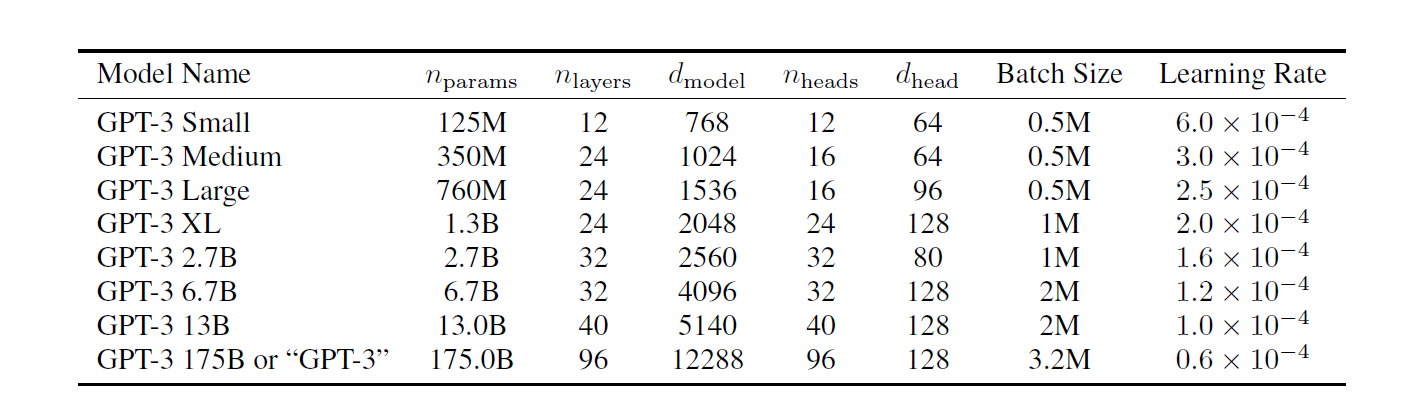
모델의 크기에 따른 성능 평가를 위해 다양한 크기의 모델들을 학습하고, 비교하고 있다. 한 가지 특징이 있다면 모델의 크기가 클수록 Batch Size 는 키우고 Learning Rate 는 줄여가는 경향성을 보인다는 것이다.
Results
Training Loss
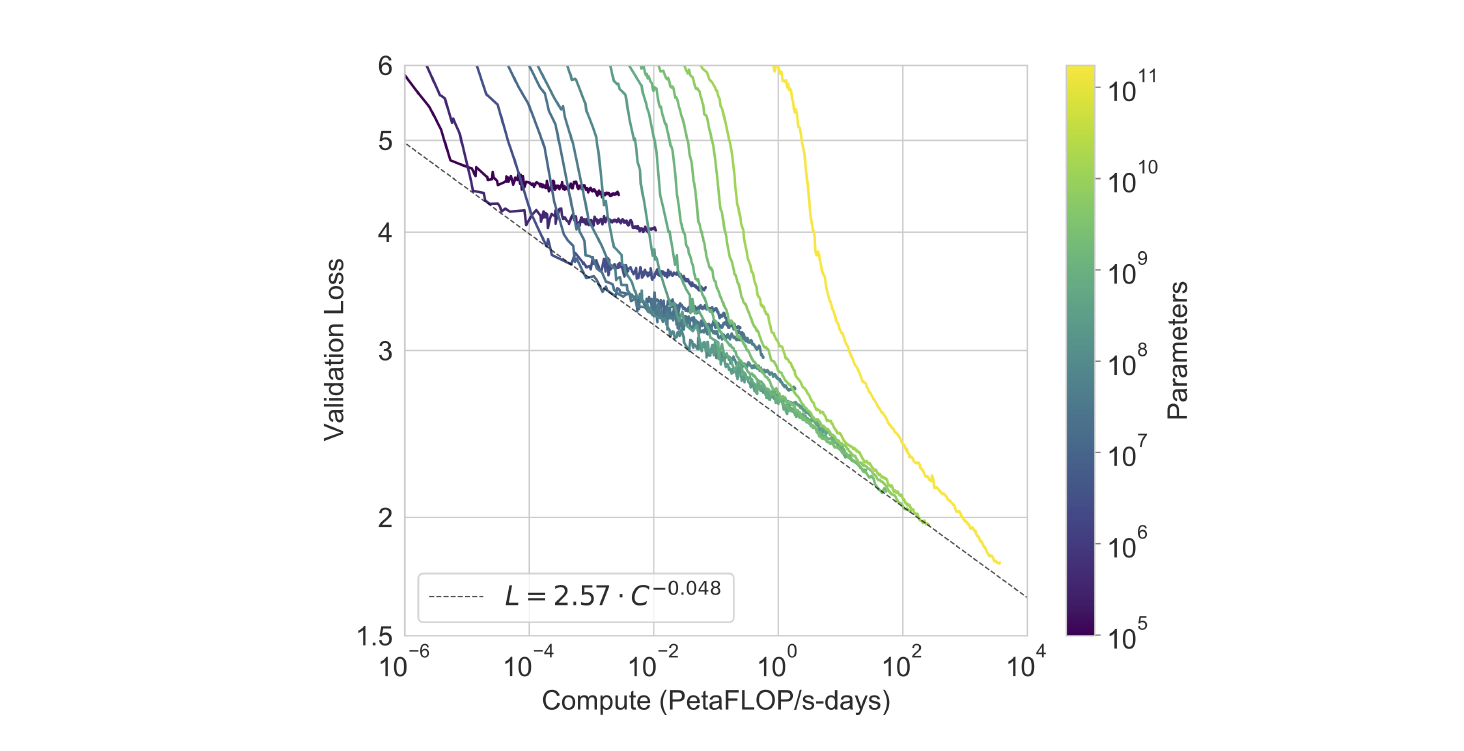
175 Billions 갯수 만큼 파라미터의 크기를 키웠음에도 여전히 모델의 크기, 데이터 셋의 크기, 학습 연산량과 Validation Loss(Cross-Entropy) 간에는 Power-Law 의 관계가 성립함을 실험적으로 보인 Scaling Laws for Neural Language Models 논문의 결과와 유사한 결과를 보이고 있다.
In-Context Learning Performance
아래 Plot 은 논문에서 실험한 42개의 Task 에 대한 통합 스코어를 In-Context Learning 셋팅 별로 분류하여 시각화한 것이다.
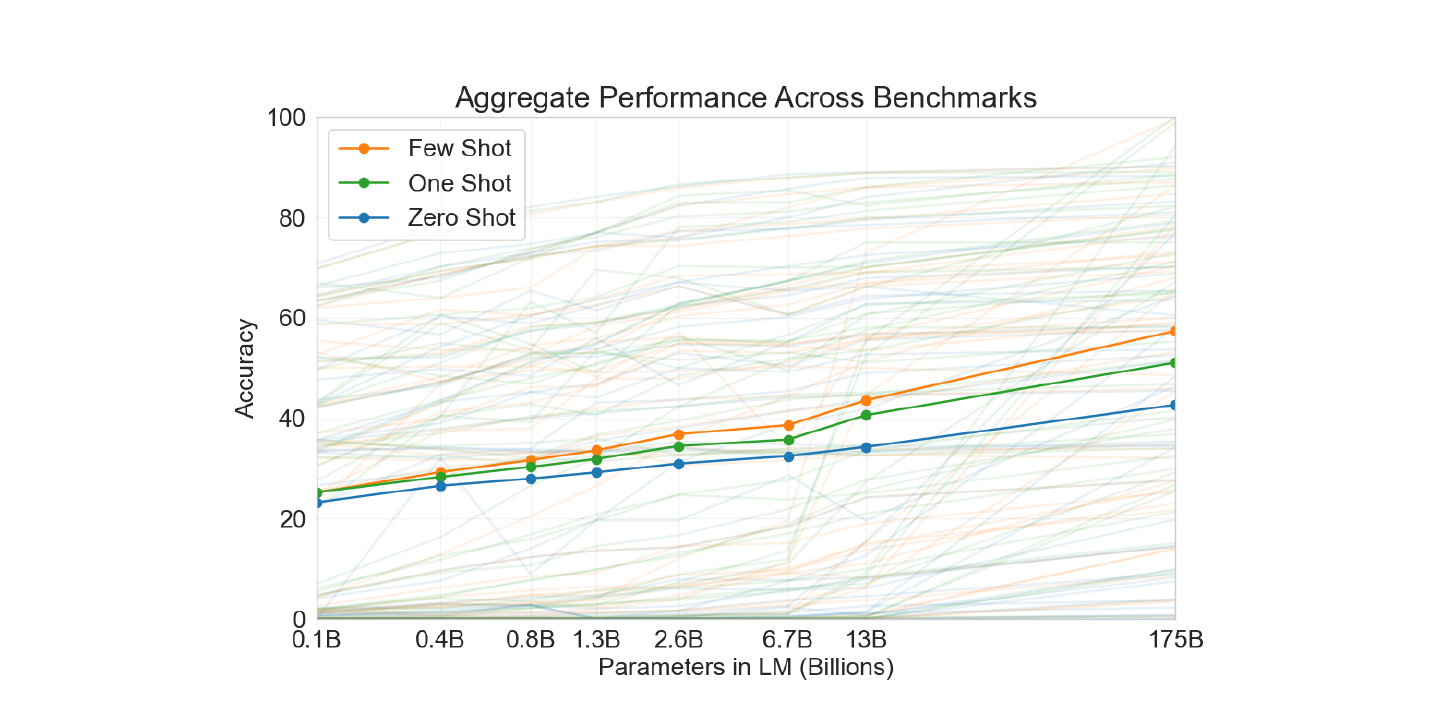
또한 아래 Plot 에서는 모델의 크기와 In-Context Learning 의 상관 관계를 보여주고 있다.
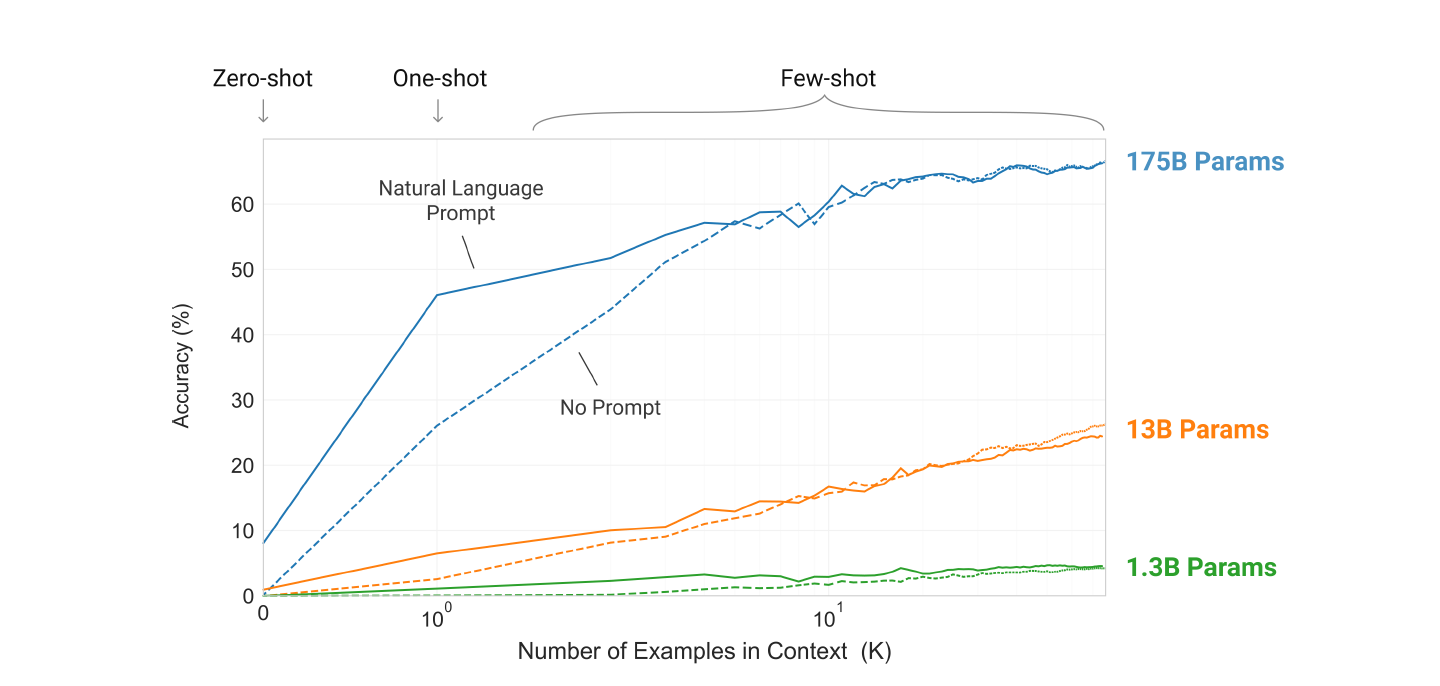
두 Plot 의 결과를 정리하면 다음과 같다.
- 모델의 크기가 클수록 성능이 높아진다.
- Demonstration 의 갯수가 많을수록 성능의 높아진다.
- 모델의 크기가 클수록 Demonstration 의 증가에 따른 성능 증가의 폭은 더욱 커진다.
Cloze and Completion Tasks
Cloze Task란 다음과 같이 빈칸을 채워 넣는 문제다.
| Original Sentence | The cat jumped over the fence. |
| Cloze Sentence | The cat __ over the fence. |
| Correct Answer | jumped |
대표적인 Benchmark Dataset 으로 Lambada 가 있다.

Completion Task 란 다음과 같이 주어진 문장을 완성하는 문제다.
| Type | Text |
|---|---|
| Given Text | The villagers were known for their kindness and… |
| Possible Completion | The villagers were known for their kindness and would often help travelers who passed through. |
대표적인 Benchmark Dataset 으로 StoryCloze와 HellaSwag 가 있다. StoryCloze 는 아래와 같이 문장의 시작 부분이 주어져 있고, 2개의 선지 중 가장 그럴싸하게 문장을 완성하는 선지를 고르는 문제이다.

HellaSwag 도 StoryCloze 와 유사한데, 4지선다 문제라는 점에서 차이가 있다.

아래 실험 결과에 따르면 Lambbada 문제에서는 GPT-3 의 성능의 demonstration 의 갯수에 상관 없이 항상 SOTA 보다 성능이 좋았다. StoryCloze 와 HellaSwag 에서는 SOTA 에 성능이 다소 미치지 못했지만, Fine-Tuning 을 하지 않고도 일정 수준 이상의 성능을 보였다는 점에서 의의를 갖는다.
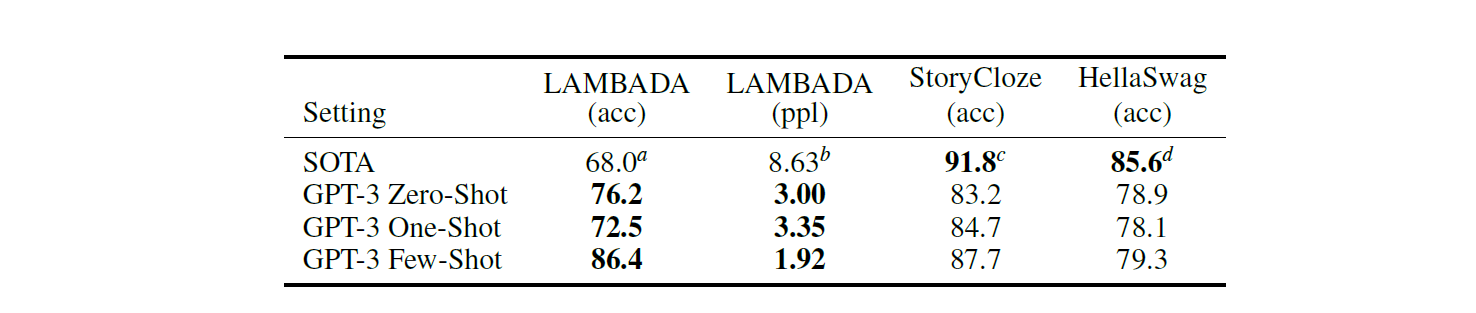
Closed Book Question Answering
질문에 대한 적절한 답을 하는 QA 문제는 Natural Questions, WebQuestions, TriviaQA 세 가지 데이터 셋에 대해 실험을 진행했다. Natural Questions 는 구글에서 만든 데이터 셋으로, 실제 사용자들이 구글에 질문한 내용과 그에 대한 답으로 구성되어 있다. WebQuestions 는 웹 상에서 이뤄진 질문들을 Knowledge Graph 로 저장한 Freebase 를 바탕으로 만들어진 데이터셋이다. 마지막으로 Trivia QA 는 일반 상식에 관한 질문들로 구성된 데이터 셋이다.
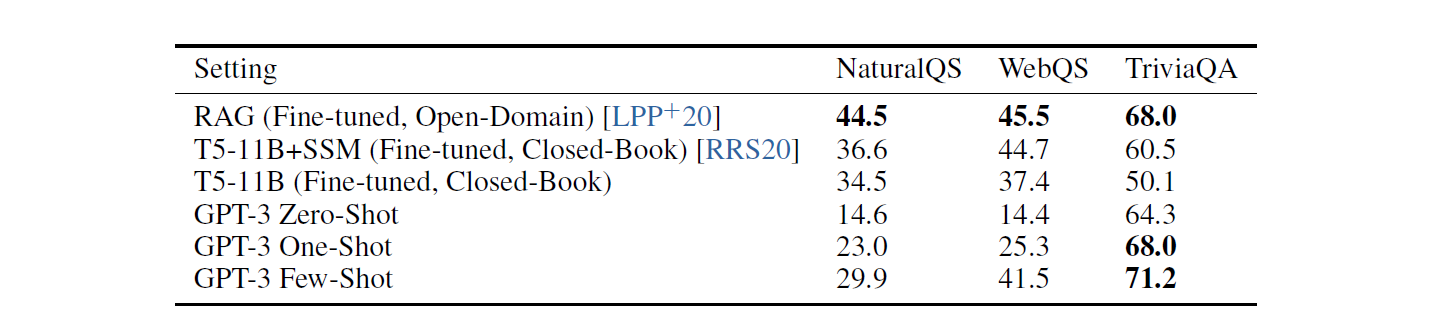
TriviaQA 문제에서만 SOTA 보다 좋은 성능을 보였다. 이외의 셋팅에서는 Fine-Tuning을 사용한 다른 모델들에 비해 성능이 다소 떨어졌다. 참고로 Closed Book 이란 Inference Time 에 외부 정보에 접근할 수 없도록 하는 실험 설정을 말하며, 이를 통해 모델의 정보 저장 능력과 정보 검색 능력을 실험할 수 있다.
Reference
- Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C. and Hesse, C. (2020). Language Models Are Few-Shot Learners. arxiv.org.
- Paperno, D., Kruszewski, G., Lazaridou, A., Pham, Q.N., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G. and Fernández, R. (2016). The LAMBADA dataset: Word prediction requiring a broad discourse context.
- Mostafazadeh, N., Chambers, N., He, X., Parikh, D., Batra, D., Vanderwende, L., Kohli, P. and Allen, J. (n.d.). A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories
- Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., Choi, Y., & Allen, P. (n.d.). HellaSwag: Can a Machine Really Finish Your Sentence?
- Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M.-W., Dai, A.M., Uszkoreit, J., Le, Q. and Petrov, S. (2019). Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics, 7. - Berant, J., Chou, A., Frostig, R. and Liang, P. (2013). Semantic Parsing on Freebase from Question-Answer Pairs. [online] ACLWeb.
- Joshi, M., Choi, E., Weld, D.S. and Zettlemoyer, L. (2017). TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension.