GPT-1 Improving Language Understanding by Generative Pre-Training
Summary
- GPT-1 은 Pre-Trained Generative model 을 적용하여, 다양한 Task에 대해 약간의 Fine-Tuning 만으로도 좋은 성능을 보이는 모델이다.
- Unsupervised learning 을 통해 Language Model Capability 를 높혀, labeled data 가 적은 문제에 대응한다.
- Pre-Trained Model 로는 Transformer 의 Decoder 부분만 사용하였다. 이때 Transformer 의 layer 가 많아질수록, Pre-Trained 모델의 학습이 잘 될수록 Downstream task 의 성능 또한 좋아짐을 확인했다.
Generative Pre-Training and Discriminative Fine-Tuning
GPT는 Generative Pre-Training 의 약자이다. 이름에서 알 수 있듯이 구조적인 특징보다도 모델을 트레이닝하는 방법인 Gerenative Pre-Training 를 강조한다.
그렇다면 논문에서 말하는 Generative Pre-Training 은 무엇을 뜻할까. 구체적으로 논문에서는 GPT-1을 학습할 때, Generative Pre-Training 과 Discriminative Fine-Tuning 두 단계로 나누어 학습을 진행했다고 언급한다. 이를 정확하게 이해하기 위해서는 Generative model 과 Discriminative model 의 차이, 그리고 Fine-Tuning 방법과 그와 반대되는 Feature Based Approach 의 차이를 알아야 한다.
Generative model and Discriminative model
Generatvie model 과 Discriminative model 은 학습 대상에 대한 차이라고 할 수 있다.
- Generative model: \(P(X)\) 또는 joint discribution \(P(X, Y)\)를 학습한다.
- Discriminatvie model: conditional distribution \(P(Y\|X)\)를 학습한다.
Generative model 은 데이터 자체의 분포를 학습하게 되며, Generative model 에서 샘플링한 data point 는 input 과 동일한 공간(\(X\))에 존재하게 된다. Generative model 이 Unsupervised learning 에 적용되면 \(P(x)\)를, Label 이 있는 Supervised learning 에 적용되면 ‘입력이 \(x\)이면서 label이 \(y\) 일 확률’을 의미하는 \(P(x, y)\)를 학습하게 된다. 반면 Discriminative model 은 어떤 입력 \(x\)가 주어졌을 때 이것의 label 이 \(y\)일 확률을 바로 추정한다는 점에서 차이가 있다.
Fine-Tuning and Feature Based Approach
Fine Tuning 과 Feature Based Approach 은 Transfer learning 의 방법들로, 미리 학습한 Pre-Trained model 을 새로운 task 에 적용시킬 때의 학습 전략과 관련있다. 구체적인 차이는 다음과 같다.
- Feature Based Approach: Pre-Trained model 은 고정(Freeze)하고, task 를 위해 새롭게 추가된 layer 에 대해서만 학습을 진행한다. 사실상 Input x 에서 중요한 feature 만 뽑아, 새로운 모델의 입력으로 전달하는 것과 동일하기 때문에 feature extraction 이라고도 한다.
- Fine-Tuning Approach: 새로운 task 를 위해 추가된 layer를 학습시킬 때 Pre-Trained model 또한 함께 학습하는 방법이다. 일반적으로 pre-trained model에 대해서는 비교적 작은 learning rate를 적용하기는 하지만 Pre-Trained model 에도 변화가 생긴다는 점에서 Feature Extraction 과는 차이가 있다.
정리하자면 GPT-1 은 Pre-Training 과 Fine-Tuning 두 가지 단계로 학습을 진행했는데, 이때 Pre-Training 단계에서는 Generative model 이 학습하는 방법, 즉 \(P(x)\)를 학습하였다면, Fine-Tuning 단계에서는 Task 의 특성에 맞게 Discriminative 한 방법으로 학습을 진행하였다. 또한 Fine-Tuning 이라는 표현에서 알 수 있듯 task 에 맞춰서 기존 Pre-Trained model 또한 업데이트했다는 것을 알 수 있다.
Semi-Supervised Learning
자연어와 관련된 Task는 매우 다양하다. 단순히 문장을 분류하는 것에서부터 시작하여 두 문장 간의 관계를 비교하거나, 유사도를 측정할 수도 있고, 수능 문제처럼 다양한 선지 중에서 정답을 찾는 문제도 있다. 한 가지 문제가 있다면 task의 유형 별로 레이블링된 데이터의 갯수에는 한계가 있어 disciminative(또는 supervised learning) 한 방법으로 개별 task 를 학습하기 어렵다는 것이다. 특히 labeling 은 사람이 직접 해야하는 경우가 많아 추가적인 데이터를 만들어내는 것 또한 좋은 해결책은 아니다.
Labeled data 가 적다는 문제를 해결하기 위해 논문에서는 Semi-Supervised Learning 이 대안이 될 수 있다고 언급한다. Semi-Supervised learning 이란 쉽게 말해 Supervised learning + Unsupervised learning 으로, Pre-Training 시에는 Unsupervised learning 을 적용하여 자연어 전반에 대한 특성을 학습하게 하고, Task 에 맞게 Supervised learning 방법으로 추가학습을 진행하는 것을 말한다. 즉, 다량의 unlabeled data 로 상대적으로 적은 양의 labeled data 가 가지는 한계를 보완하는 것이다. 심지어 자연어는 unlabeled data(Task와 관계 없이 단순히 완성된 문장) 가 매우 풍부하다는 점에서 이러한 방법을 사용하기에 매우 적합하다.
물론 Semi-Supervised learning 과 관련해서도 해결해야 할 어려움이 있다.
- Pre-Training 시 Optimization Objective 를 어떻게 설정하는 것이 효과적일지 알기 어렵다.
- Pre-Training 에서 Text Representation 을 잘 학습하였다고 할지라도 다른 Target Task 에 효율적으로 Transfer 하는 방법에 대한 연구가 필요하다.
이와 같은 두 문제를 언급하여 논문에서는 Pre-Training 과 Fine-Tuning 을 다음과 같이 진행했다고 밝히고 있다.
Unsupervised Pre-Training
Pre-Training 의 목표는 자연어의 구조적 특성에 대한 이해를 높이는 것이다. 한국인이 한국어를 전혀 모르는 외국인보다 수능 문제를 더 잘 풀 수 있는 것과 비슷한 이치로, 일단 자연어를 더 잘 하는 모델을 만들어보자는 것이다. Token \(U = \{ u1, ..., u_n \}\) 이 주어져 있다고 할 때 GPT-1 에서는 다음과 같이 Likelihood 를 극대화하는 Objective Function 을 정했다고 한다.
\[L_1(U) = \sum_i \log P(u_i | u_{i-k}, \ldots, u_{i-1} ; \Theta)\]식을 보면 \(u_{i-k}\)부터 \(u_{i-1}\)까지, 총 \(k\) 개의 token 이 주어졌을 때 \(u_i\)가 나올 conditional probability 를 극대화하고 있음을 알 수 있다. 즉 이전 \(k\)개의 단어를 보고 그 다음 단어를 생성하도록 만드는 것이다.
\[\begin{align*} h_0 &= U W_e + W_p \\ h_l &= \text{transformer_block}(h_{l-1}) \; \forall l \in [1, n] \\ P(u) &= \text{softmax}(h_n W_e^T) \end{align*}\]구체적인 모델 수식은 위와 같다. 입력 \(h_0\)는 word embedding token \(UW_e\)와 개별 Token의 위치를 알려주는 Position embedding \(W_p\) 으로 구성되고, 이를 \(n\)개의 Transformer block에 차례대로 통과시켜 \(h_l\)을 구하게 된다. 마지막으로 \(h_l\) 에 linear layer 와 softmax 를 적용하면 최종 출력이 나오게 된다. 이때 이 출력이 실제 다음 단어인 \(u\)일 확률을 극대화시키는 것이다. 이 과정에서 labeled data 는 전혀 사용되지 않았고, 다음 단어를 예측하도록 하였기 때문에 Supervised learning, Generative model 적인 특성을 가진다고 할 수 있다.
Pre-Trained model 은 위의 식에서도 언급되었듯이 Transformer 를 사용하였다. 정확하게는 transformer 에서도 decoder 구조만 떼어내어 사용하였다. 이는 decoder 가 복수의 이전 시점 출력 값들을 함께 받는 구조이기 때문이다. 하지만 encoder 가 없기 때문에 cross attention 은 사용하지 못하고, self-attention 만 사용하게 된다.
Supervised Fine-Tuning
한국어를 잘하는 모델을 만들었으니 다음으로는 수능 문제를 오답노트하여 좋은 대학에 갈 수 있도록 해줘보자. Fine-Tuning 은 Task 별로 달리 진행되지만 기본적인 Objective Function 은 다음과 같다. \(P(y\|x)\)를 학습하므로 discriminative model 이며, labeled data 를 사용하므로 Supervised learning 이다.
\[L_2(C) = \sum_{(x, y)} \log P(y | x^1, \ldots, x^m)\]구현은 다음과 같이 이뤄진다.
\[P(y | x^1, \ldots, x^m) = \text{softmax}(h_l^m W_y)\]Fine-Tuning 을 위해 추가된 \(W_y\) layer에 pre-trained model 의 출력 값을 통과시켰을 때 정답 \(y\) 가 나오도록 학습하겠다는 것이다.
Fine-Tuning 시에는 위 Objective Function 과 함께 Pre-trained model 에 대한 최적화도 함께 진행(auxiliary objective)하면 더욱 수렴이 빠르고 generailization 효과가 좋아진다고 한다. 따라서 최종 Fine-Tuning Objective Function 은 다음과 같다.
\[L_3(C) = L_2(C) + \lambda * L_1(C)\]Task Specific Input Transformation
Pre-Training 은 앞 부분 단어들을 보고 바로 뒤의 단어를 맞추는 구조로 Task 유형이 하나인데다가 문장 간의 구별도 필요하지 않다. 하지만 Fine-Tuning 은 Task 의 종류가 많고, 경우에 따라서는 복수의 문장을 한꺼번에 입력으로 받아야 한다. 따라서 Task의 유형에 따라 입력 구조와 출력을 다루는 방법이 달라지게 된다.
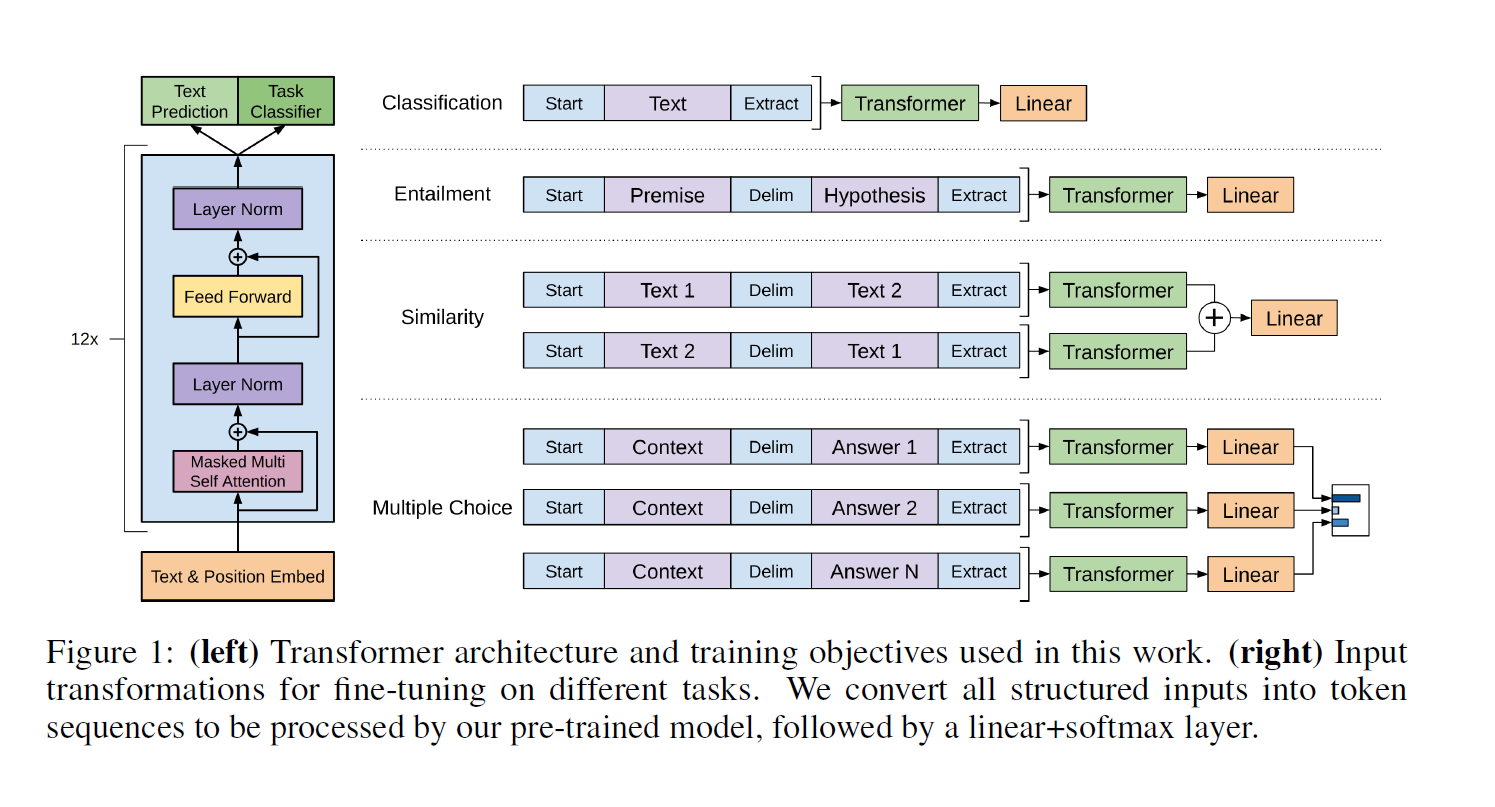
구체적인 Task 유형에 따라 세부적인 부분이 다르지만, 기본적으로는 입력 Sequence 를 Pre-Trained model(Transformer)과, Additional Linear Layer 에 차례대로 통과시키는 구조를 가지고 있다. 즉 어떠한 문제든 Pre-trained model 이 한 번에 처리할 수 있도록 입력(traversal-style)을 만들도록 하여 Task specific 구조를 없애는 것을 목표로 한다.
Text Classification
문장을 class 별로 분류하는 문제. 가장 간단한 방법으로 시작 토큰과 끝 토큰 사에 입력 토큰을 차례대로 나열하면 된다.
Text entailment
전제(premise) 문장과 가설(hypothesis) 문장 간의 관계를 예측하는 문제이다. 두 개의 문장으로 구성되어 있으므로 두 문장을 구분하는 Delimeter 토큰이 추가되었다.
Similarity
문장 간의 유사도를 구하는 문제는 두 문장의 입력 순서가 결과에 영향을 미치지 않는다. 따라서 두 문장의 순서를 바꿔가며 각각의 sequence representation 을 구하고, 이를 element wise 로 더한 뒤 lienar output layer 에 입력으로 전달하여 예측하도록 했다.
Question Answering, Commonsence Reasoning
이들 유형의 문제는 context, question, possible answer set 들을 모두 입력으로 전달해야 한다. context + question + one of possible answer 로 가능한 정답 만큼의 sequence 를 만든 뒤 softmax layer에 통과시켜 각 answer 의 정답 확률을 구한다.
Analysis
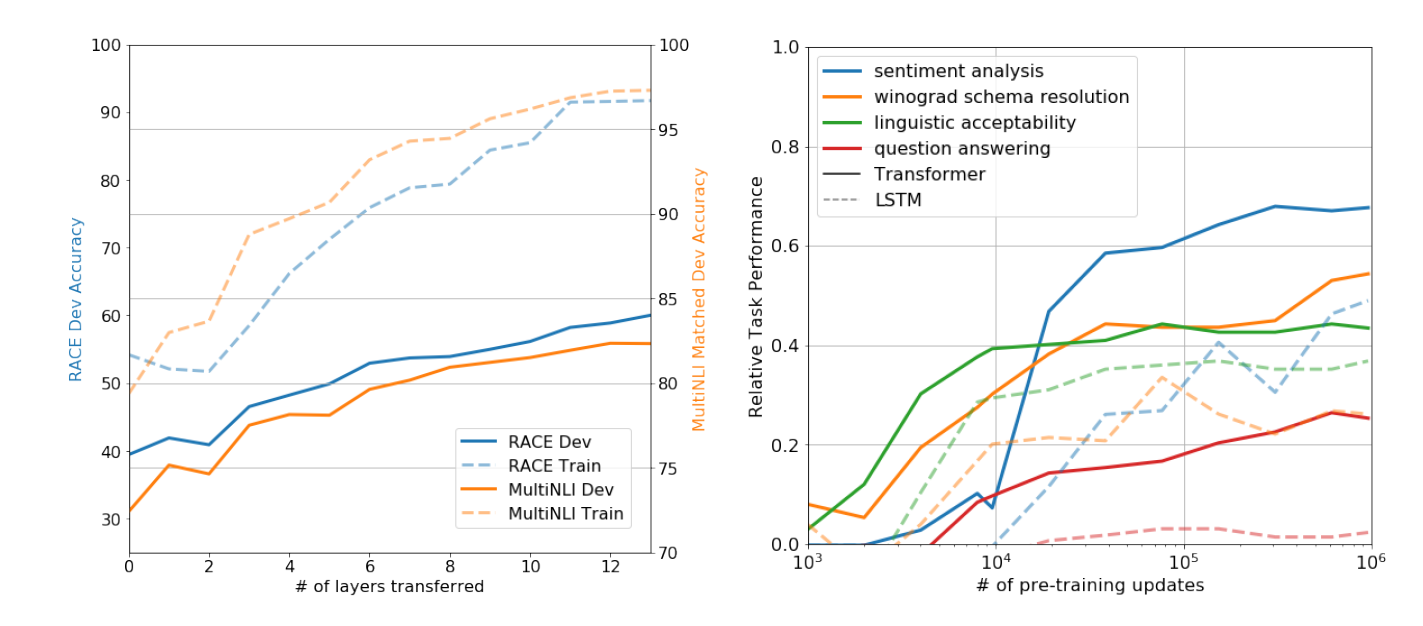
Number of layers
pre-trained model 의 layer 수를 바꿔가며 supervised target task 에 대한 실험을 진행하였고, layer의 갯수가 하나씩 늘어날 때마다 성능이 9% 정도씩 늘어나는 것을 확인할 수 있었다고 한다(MultiNLI). 이는 각각의 layer 가 target task 를 해결하는데 있어 유용한 기능을 가지고 있다는 것을 의미한다.
Performance of Pre-Trained model
논문의 저자는 다음 두 가지 가정을 가지고 있었다고 한다.
- Generative model 이 다양한 taks 를 수행하는데 필요한 Language Model capability 를 높일 수 있다.
- Trasnfromer 의 구조적인 특성(Attentional memory)이 LSTM에 비해 다양한 task를 해결하는데 도움이 된다.
첫 번째 가정을 검증하기 위해 Pre-Training 횟수에 따른 성능 비교를 진행하였고, pre-training 의 횟수가 늘어나면 날수록 성능이 좋아지는 것을 확인하였다고 한다. 즉 Generative Pretraining 의 결과가 좋을 수록 다양한 task 와 관련된 학습 능력이 높아진다는 것이다.
또한 Transformer 의 구조적인 특성과 관련된 두 번째 가정과 관련하여 zero-shot performance 기준으로 LSTM 이 transformer 보다 variance 가 더 높다는 것을 확인하였고, 이를 통해 Transformer의 Inductive Bias 가 LSTM의 그것보다 효과적이라고 결론짓는다.