BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Summary
- BERT 는 Transformer 의 Encoder 구조를 사용하며, Bidirectional 하게 Contextual Representation 을 생성할 수 있다. Unidirectional 한 GPT-1 과는 구별된다.
- BERT 는 GPT-1과 같이
Unsupervised Fine-Tuning Approach에 속하며, 다양한 Downstream Task 에 적용 가능하다. Masked Language Model,Next Sentence Prediction이라는 두 개의 Unsupervised Pre-Training Method 를 제안한다.
Model Architecture
BERT는 Bidirectional Encoder Representations from Transformers 의 약자로, 이름에서 알 수 있듯이 Bidirectional 한 특성을 가지는 Transformer의 Encoder 구조를 적극적으로 활용한다. 실제로 논문의 저자들은 자신들이 BERT 의 구현에 사용한 코드가 Transformer 구현을 기초로 하였으며, 거의 동일하기 때문에 모델 구조에 대한 언급은 생략한다고 밝히고 있다.
BERT's model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation. ... Because the use of Transformers has become common and our implementation is almost identical to the original, we will omit an exhaustive background description of the model architecture
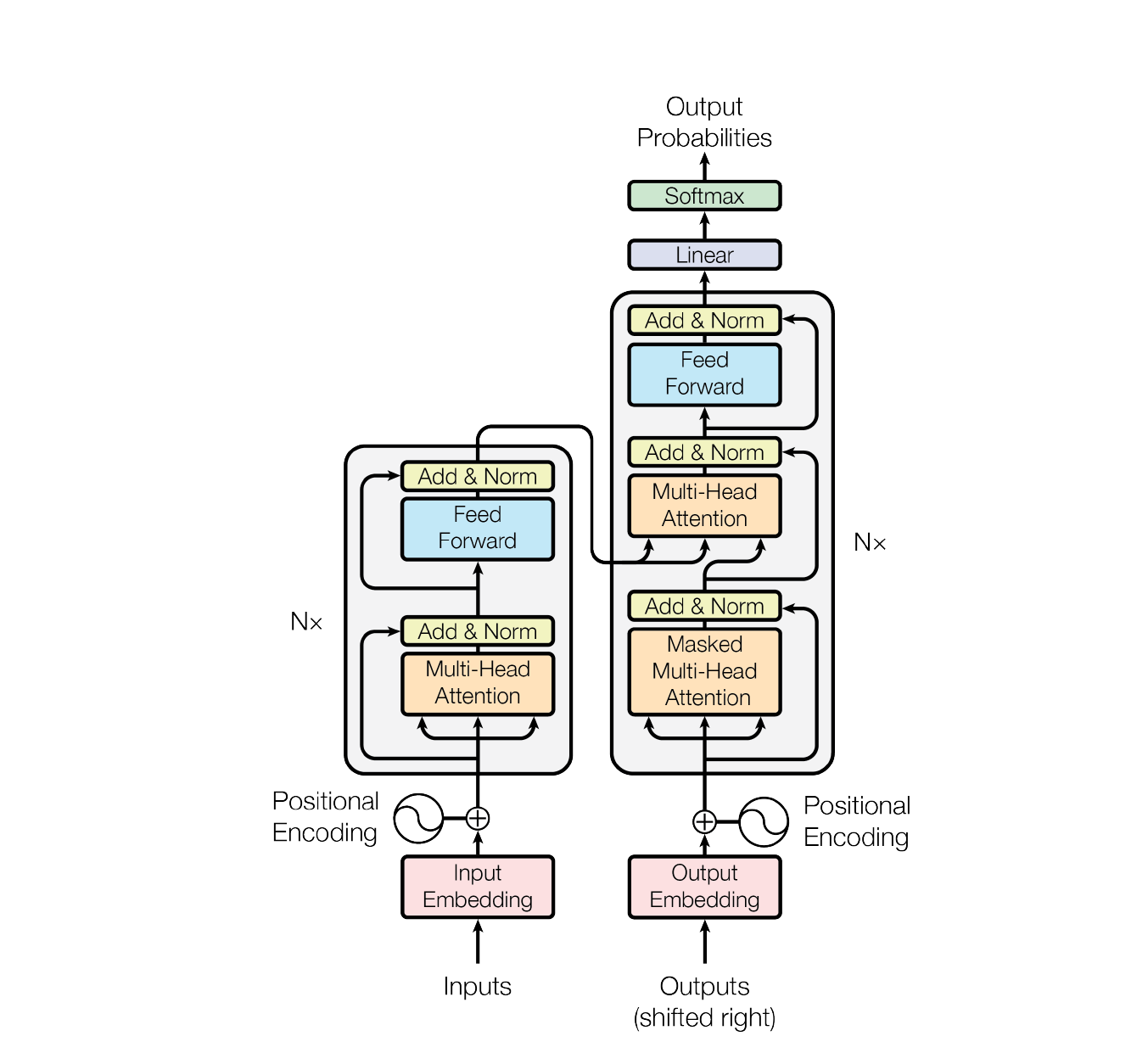
보다 구체적으로 BERT 는 Transformer 의 Encoder 구조에서 도입된 Bidirectional self-attention 메커니즘을 적극적으로 사용한다. 직역하면 ‘양방향’ 정도가 되는 Bidirectional 은 무엇을 의미할까. 이는 입력 Sequence 를 처리하는 방식과 관련있다.
단어 그 자체로 의미를 가지기도 하지만 대부분의 자연어는 문장과 같은 단어들의 Sequence 로 의미 전달이 이뤄진다. 어떤 문장이 주어져 있을 때, 사람이 이를 읽고 이해하는 방법은 왼쪽에서부터 오른쪽으로 읽는 방법(left-to-right) 하나와 오른쪽에서 왼쪽으로 읽는 방법(right-to-left) 두 가지가 있다. 그리고 이러한 방법들을 한 방향으로 읽는다고 하여 Unidirectional 이라고 한다.
Unidirectional Model: GPT-1, ELMo
GPT-1
대표적인 Unidirectional Model 로는 GPT-1(Generative Pre-trained Transformer) 이 있다. GPT-1 또한 Transformer 구조에서 영감을 받아 만들어진 모델인데, BERT 와 차이가 있다면 Transformer 의 Encoder 가 아닌 Decoder 를 활용한다는 점이다.
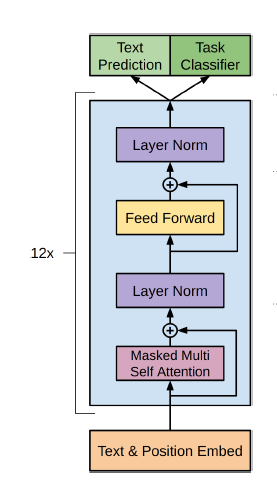
위 이미지는 GPT-1 논문에서 보여주고 있는 GPT-1 의 구조이다. 첫 번째 Transformer 의 Decoder 와 비교해 볼 때 전체적인 구조가 비슷하나, Encoder 의 출력 값을 사용하여 Attention Score 를 구하는 과정(Cross Self Attention)이 생략되었음을 알 수 있다. GPT-1 은 Transformer 의 Encoder 처럼 이전 step의 output 을 입력 받으며 한 번에 한 단어씩 순차적으로 추론하게 된다. 이러한 점에서 GPT-1 은 Unidirectional Model 이라고 하는 것이다.
ELMo
ELMo 는 GPT-1 처럼 left-to-right 방향으로 학습할 뿐만 아니라 right-to-left 방향으로도 학습을 진행하고, 두 방향에서 얻은 embedding 들을 모두를 사용한다. 하지만 BERT 논문의 저자들은 Shallow concatnation independently trained left-to-right and right-to-left LMs. 이라고 표현하며 BERT의 Deep bidirectional representation 과는 차이가 있다고 언급한다.
Bidirectional Model
그렇다면 BERT 에서 말하는 Bidirectional 의 의미는 무엇일까. 이름에서도 알 수 있듯이 Transformer 의 Encoder 연산을 보면 된다. Transformer 의 Encoder 는 token sequence 를 입력으로 받아, 각각에 맞는 feature 들을 출력한다. Decoder 는 이들 feature 를 받아 Attention 에 적용하여 최종 예측 값을 생성하게 된다. 즉 BERT 에서 말하는 Bidirectional 은 어느 한 방향으로 순차적으로 정보를 읽어들이는 것이 아닌, 전체 sequence 를 한 번에 입력으로 받고 그들 정보를 모두 활용하여 추론하는 것을 의미한다.
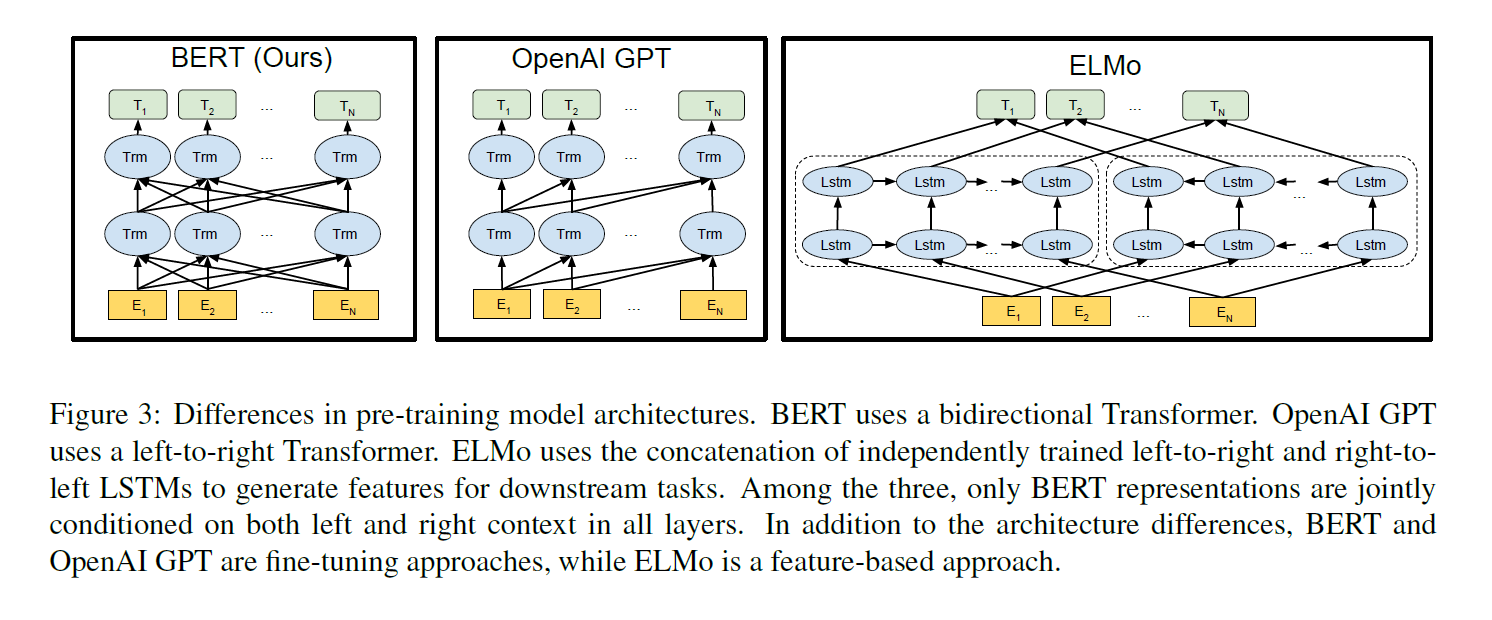
BERT 논문의 위 그림을 보면 세 모델의 차이를 보다 쉽게 확인할 수 있다.
call-out: Translation with BERT
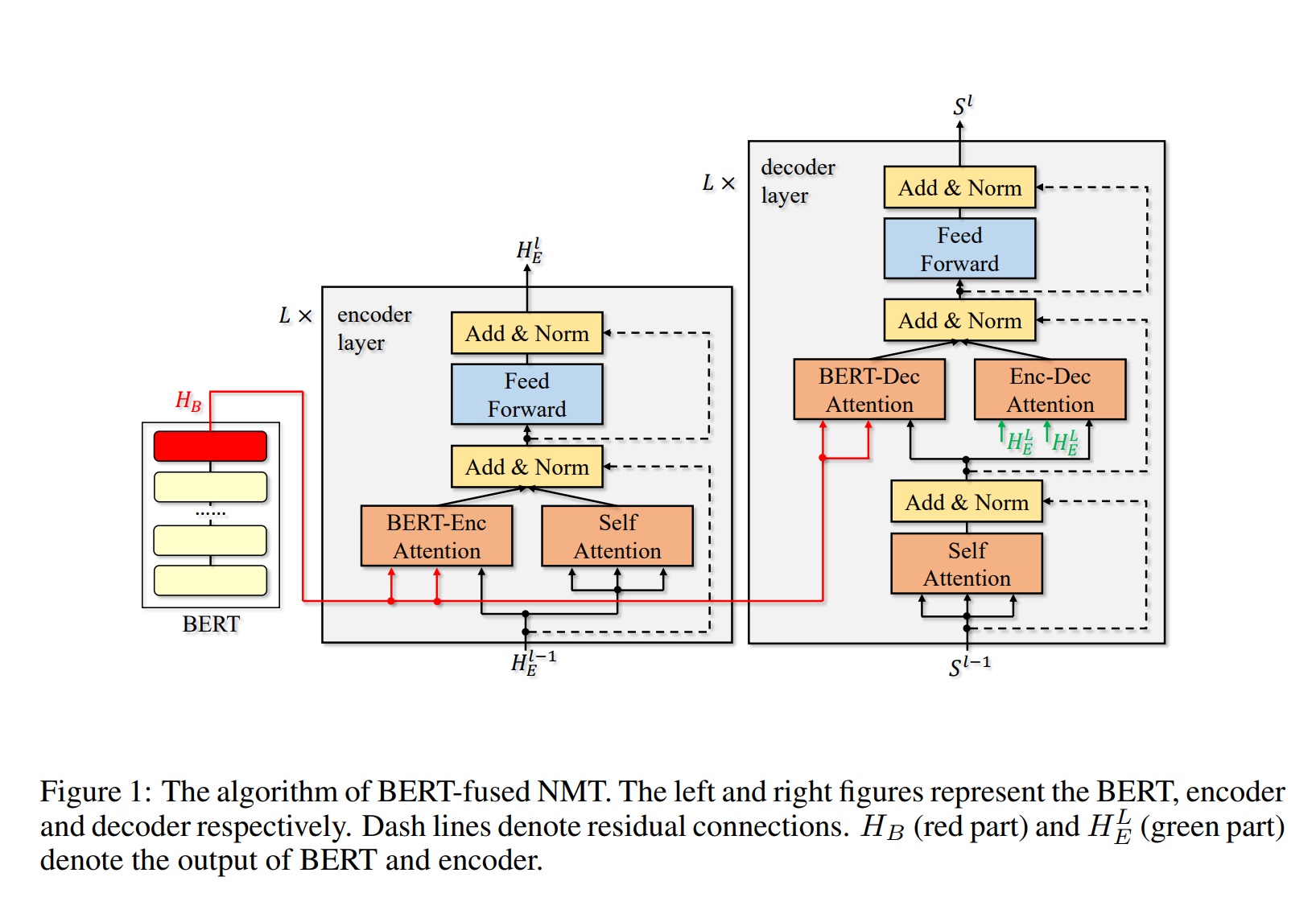
그렇다면 BERT 는 Translation 과 같이 입력과 출력의 갯수가 다른 Task 는 해결할 수 없을까. BERT 는 Sentence 의 Contextual Representation 을 추출하는 데에 적합한 모델로, 그 자체만으로는 번역과 같은 테스크에 적합하지는 않다고 한다. 하지만 Incorporating BERT into Neural Machine Translation 과 같은 논문에서 BERT 를 활용한 모델을 제안하기도 했다.
Training Strategy
BERT 는 학습 방법의 분류 상 Unsupervised Fine-Tuning Approach 에 속한다. 또한 BERT 는 Pre-training 시에 MLM(Masked Language Model)과 NSP(Next Sentence Predition) 이라는 두 가지 Unsupervised Task 를 학습하였다고 한다.
Unsupervised learning
GPT-1 과 마찬가지로 BERT 또한 문장 외에 별도의 레이블이 필요 없기 때문에 Unsupervised Learning 에 속한다. 사람에 의한 레이블링이 필요없다는 점에서 효율적인 학습이 가능하다.
Fine Tuning
BERT 는 GPT-1 과 같이 Fine-tuning 방식을 사용한다. Fine-Tuning 과 대비되는 개념이 Feature based Approach(ELMo가 대표적) 인데, 이는 Downstream Task 를 위한 추가 학습 방법에 관한 분류이다. Fine-Tuning Approach 는 추가 학습 시에 task 를 위해 추가적으로 붙는 layer 뿐만 아니라 기존 layer 도 전체 또는 일부 학습에 포함시키는 반면 Feature based approach 의 경우 추가 layer 에 대해서만 학습을 진행한다.
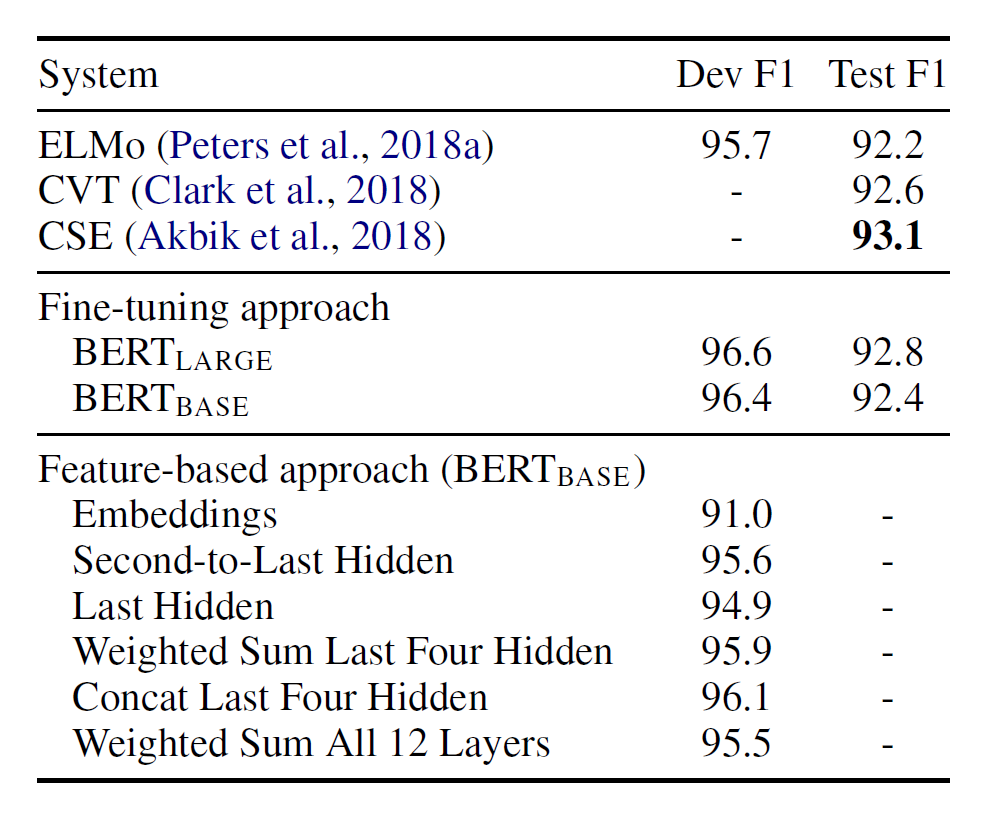
BERT 논문에서는 Feature based approach 를 적용한 경우에 대해서도 비교 실험 결과를 제공하고 있다. Fine-Tuning 의 결과가 보다 좋다는 것을 알 수 있다.
Masking Language Model
BERT 에서 Pre-Training 시 수행한 두 가지 테스크 중 하나인 MLM(Masked Language Model)은 입력 문장의 일부 Token 을 랜덤하게 [MASK] 라는 Special Token 으로 대체하고, Masking 된 Token 이 무엇인지 맞추도록 하는 학습 방법을 말한다. 이때 BERT 의 output 에 softmax 를 적용하는 layer를 붙인 채로 학습하게 된다.
MLM에 한 가지 문제가 있다면 Fine-Tuning 시에는 Special Token 인 [MASK] Token 이 입력으로 주어지는 경우가 없다는 것이다. Pre-Training 과 Fine-Tuning Task 간의 간극을 줄이기 위해 Masking 작업에 다음 조건에 따라 이뤄진다고 한다.
- 전체 단어 중 15%를 Masking 후보로 선정한다.
- 후보의 80%는
[Mask]Token 으로 대체한다. - 후보의 10%는 Token Embedding 중 임의의 Token 으로 대체한다.
- 후보의 10%는 Original Token 을 그대로 사용한다.
Next Sentence Prediction
BERT 에서 Pre-Training 시 수행한 다른 하나의 Task 는 NSP(Next Sentence Prediction) 이다. MLM이 문장 내에서 단어가 가지는 의미를 학습하는 데에 초점 맞춘 테스크라면 NSP 는 Sentence 간의 관계를 학습하는 테스크라고 할 수 있다. 이는 QA(Question-Answering), NLI(Natural Language Inference)와 같은 Downstream Task 를 타겟팅한 학습이기도 하다.
학습 데이터를 구성하는 방법은 간단하다. 전체 Corpus 에서 임의의 문장을 뽑은 뒤, 50%의 확률로 직후 문장을 함께 넣어주고, 50%의 확률로 직후 문장을 제외한 다른 임의의 문장을 함께 넣어주는 것이다. 그리고 IsNext와 NotNext 를 label 로 모델을 학습하면 된다. 이때 두 문장 사이에는 [SEP] 이라는 Special Token 이 들어가 모델이 서로 다른 두 문장이라는 것을 알게 해준다.
Input Token
끝으로 BERT의 Input Token 을 살펴보자. BERT 의 Input Token 은 Token embedding, Segmentation embedding, Position embedding 세 가지 embedding 을 concat 하여 생성한다.
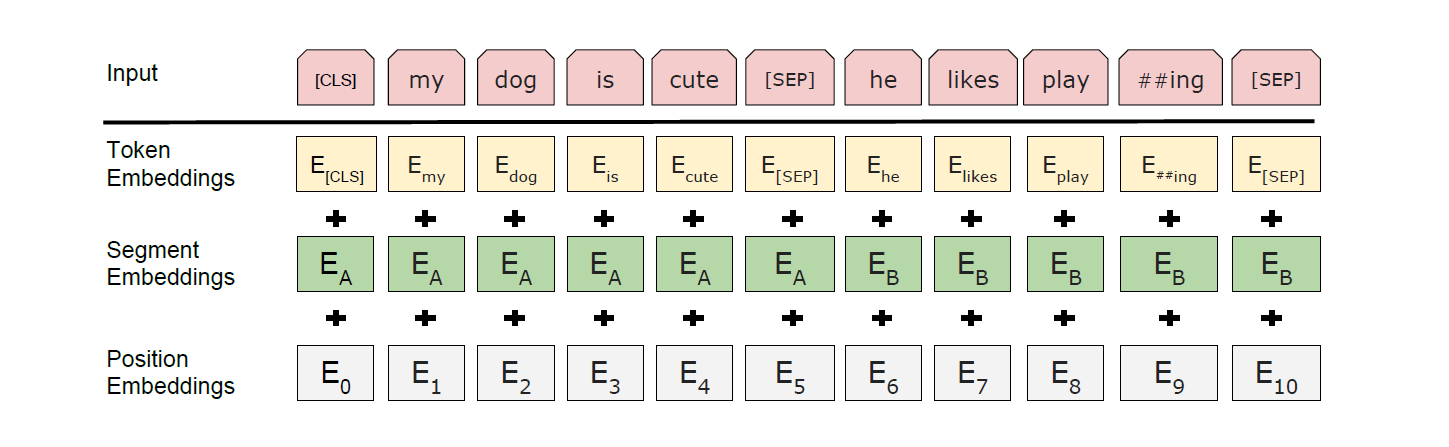
- Token Embedding: Word Piece Embedding 을 사용함
- Segmentation Embedding: 동일한 문장임을 알려주는 Embedding
- Position Embedding: 단어의 순서를 알려주는 Embedding
한 가지 흥미로운 점은 Position Embedding 으로 1,2,3 과 같이 단순 Incremental 한 숫자를 넣어주는 것이 아니라 sin, cos 함수의 값을 사용한다는 것이다. 이는 다음 두 가지 장점이 있다고 한다.
- 모든 값이 -1 에서 1 사이로 구해지기 때문에 학습에 유리하다.
- 절대적인 위치 값을 사용하게 되면 inference 시 최장 문장의 길이가 제한된다. sin, cos 함수의 값은 상대적인 위치 정보이므로 이러한 문제가 없다.
Special Token
BERT 에는 다음 세 가지 Special Token 이 있다.
[CLS]: 입력의 시작에 들어가는 Token 이다. 출력에서는 Sentence Classification 과 같은 추론 값이 나오는 자리가 된다.[SEP]: 문장과 문장 사이에 들어가는 Token 이다. 문장이 끝나고 새로 시작 됨을 알려준다.[MASK]: 문장 속 단어를 Masking 할 때 사용된다. MLM(Masking Language Model) 학습 방법과 관련 있는 Token 이다.
Downstream Tasks
논문에서 제시하는 대표적인 Downstream Task 유형으로는 Sentence Pair Classification, Single Sentence Classification, Question Answering Task, Single Sentence Tagging Task 등이 있다.
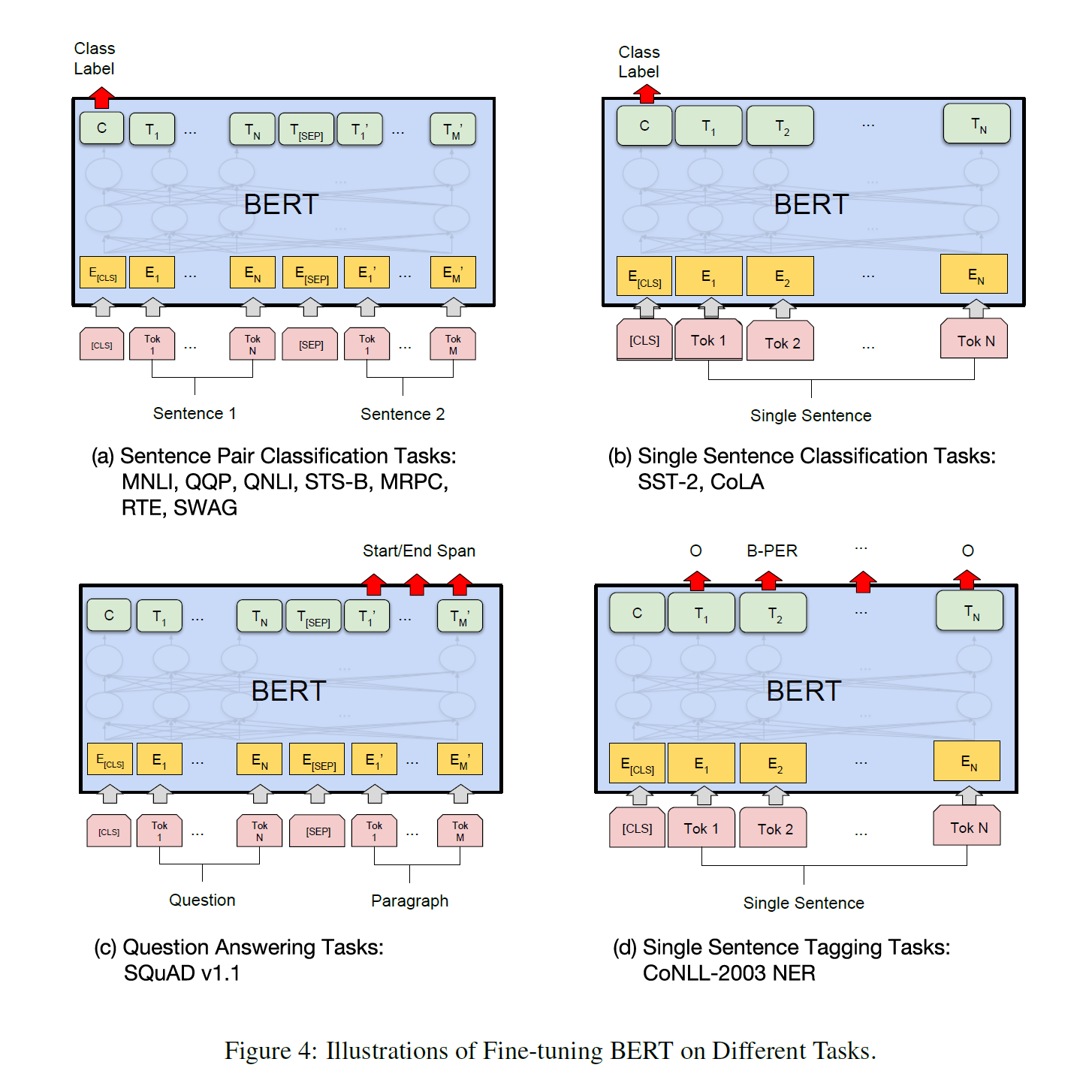
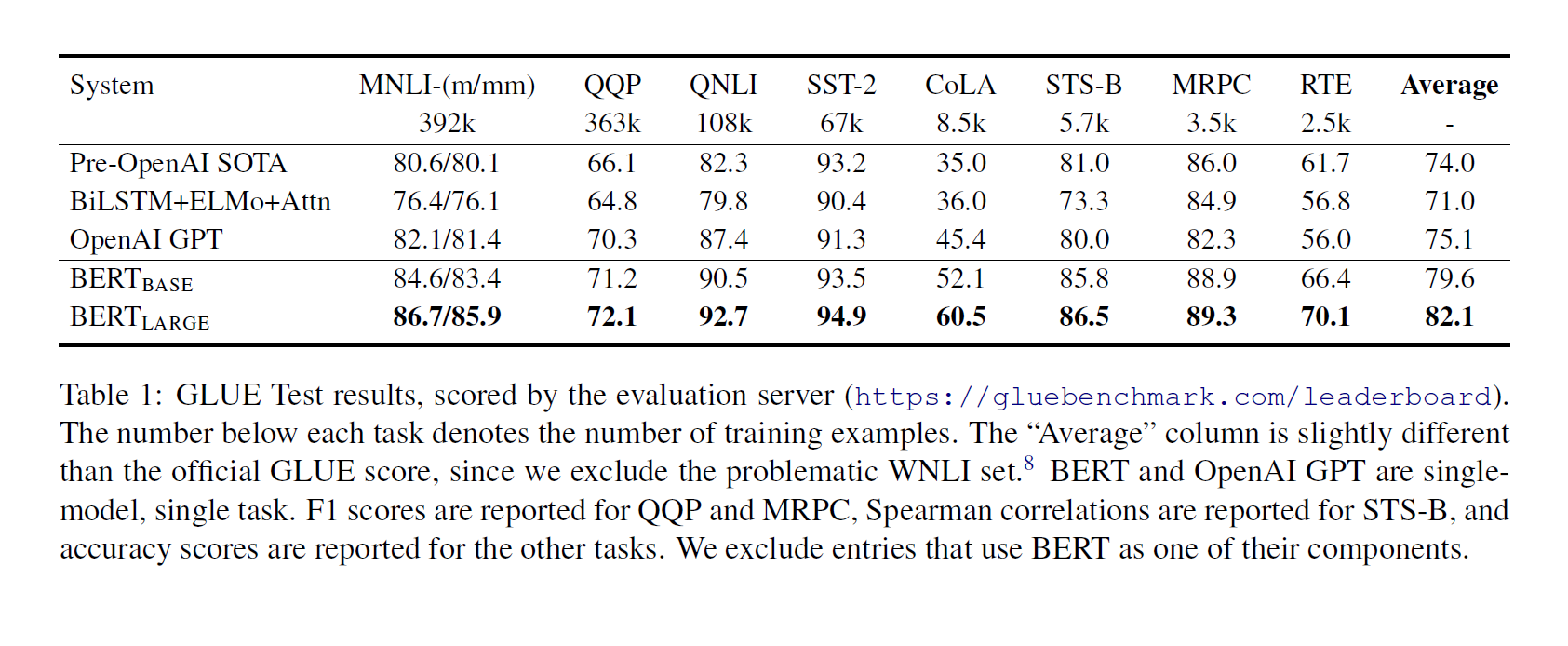
좌측의 두 Task 유형은 복수의 문장을, 우측의 두 Task 유형은 한 개의 문장을 입력으로 받는다. Downstream Task 들의 Benchmark 는 다음과 같다.
Reference
- Devlin, J. et al. (2019) Bert: Pre-training of deep bidirectional Transformers for language understanding, arXiv.org. Available at: https://arxiv.org/abs/1810.04805 (Accessed: 07 May 2024).
- Radford, A. et al. (2018) Improving Language Understanding by Generative Pre-Training, openai. (Accessed: 07 May 2024).
- Vaswani, A. et al. (2017) Attention is all you need, arXiv.org. Available at: https://arxiv.org/abs/1706.03762 (Accessed: 07 May 2024).
- Zhu, J. et al. (2020)Incorporating BERT into Neural Machine Translation, arXiv.org. Available at: https://arxiv.org/abs/2002.06823 (Accessed: 07 May 2024).