Planning and Learning
- Sutton의 2011년 책 Reinforcement Learning: An Introduction 2nd edition을 참고해 작성했습니다.
Introduction
강화학습 알고리즘을 구분하는 대표적인 기준 중 하나는 환경에 대한 Model을 상정하는지 여부로 나누는 것이다. 이때 어떠한 Model도 상정하지 않는 경우를 Model-Free Learning이라고 하고, 환경을 Modeling하여 이를 이용해 보다 나은 학습을 추구하는 Model-Based Learning이라고 한다. 딥러닝을 사용하는 현대의 대표적인 알고리즘인 DQN, DDPG, PPO 등은 모두 Model-Free Learning에 속하고, World Model, Dreamer 등이 Model-Based Learning의 예시라고 할 수 있다.
Sutton 책에서는 Model-Free learning을 Learning Method라고 표현하고, 그 예시로 Monte Carlo Method(MC)와 Temporal Difference Method(TD)를 제시한다. 그리고 Model-Based Learning을 Planning Method라고 하며 Dynamic Programming(DP)을 언급하고 있다. 이렇게 구분하면 두 가지에 큰 차이가 있는 것처럼 보이지만 결국 큰 틀에서 보면 주어진 환경에서 더 나은 Return을 보장하는 Optimal Policy를 찾기 위한 방법들이다.
Model of Environment
Model of Environment이란 Agent가 실제 환경이 어떤 Action에 대해 어떻게 대응할 것인지 예측하는 데에 Agent가 사용할 수 있는 것을 의미한다. 이러한 Model of Environment을 사용하겠다는 것은 어떤 State와 Action pair가 주어졌을 때 얼마나 큰 Reward가 주어지고 Next State는 어떻게 될지 환경과 직접 상호작용하지 않고도 학습을 통해 Agent가 알 수 있도록 하고, 이를 통해 보다 좋은 Action을 선택하도록 하겠다는 것이다.
Distribution Model & Sample Model
Model of Environment는 크게 두 가지로 나누어 볼 수 있다. Distribution Model은 어떤 Action의 결과로 얻을 수 있는 모든 결과를 예측하고, 각각의 결과가 발생할 확률을 계산하는 Model이다. 반면 Sample Model은 가능한 결과 중 하나와 그것의 확률만을 계산하는 Model을 말한다. 예를 들어 주사위를 던진다고 한다면 Distribution Model은 1,2,3,4,5,6과 각각에 대한 확률 1/6, 1/6, 1/6, 1/6, 1/6, 1/6으로 예측하고 Sample Model은 3이 나올 확률 1/6이라고 딱 하나의 Sample에 대해서만 예측하는 식이다. 당연히 Distribution Model이 더욱 강력하지만 얻는 것이 훨씬 어렵다.
Distribution Model과 Sample Model은 Model을 통해 반복적으로 예측한 결과를 보면 그 차이가 보다 명확해진다. State Space \(S = \{ s1, s2, s3, s4\}\)로 정의되는 환경이 있다면 Distribution Model은 매 Prediction마다 가능한 모든 경우의 수(Transition)를 에측하게 되므로 결과적으로는 아래와 같이 가능한 모든 Episode와 그것이 발생할 확률을 예측하는 꼴이 된다.
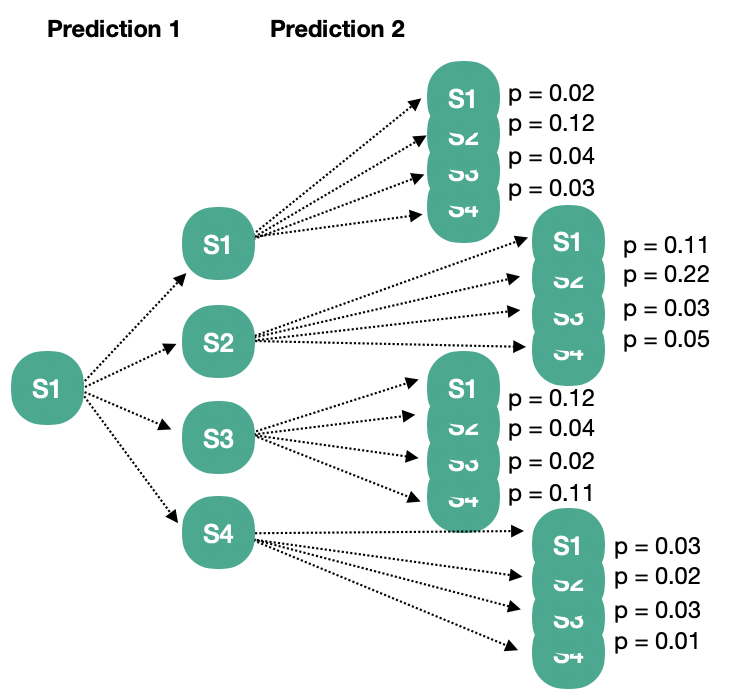
반면 Sample Model은 아래와 같이 한 번에 하나의 Episode와 그 확률을 예측하게 된다.
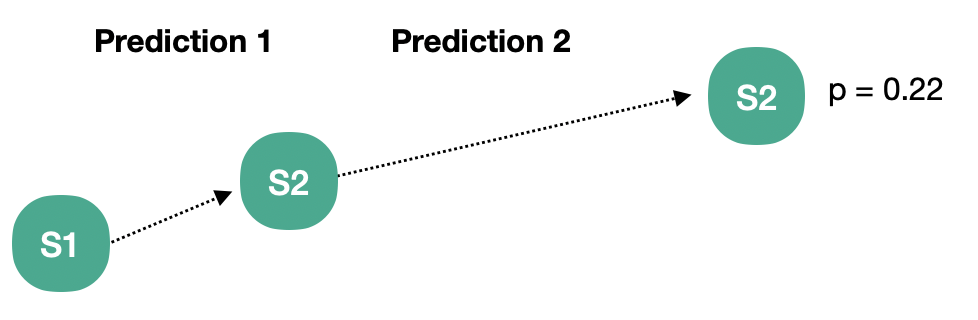
위와 같이 Model of Environment에 의해 만들어진 Transaction 또는 Episode를 Simulated Experience라고 한다.
Planning
Planning이란 Model of Environment를 사용하여 실제 환경에 대해 더 나은 Policy를 구하는 과정을 지칭한다. 즉 Planning이라는 함수가 있다면 Model of Environment를 입력으로 받아 더 나은 Policy를 출력으로 반환하는 함수라고 할 수 있다.

Sutton은 Planning을 Search Space에 따라 State-Space Planning과 Plan-Space Planning 두 가지로 나누고 있는데, 기본적으로 State Space를 단위로 Valu Function을 업데이트하고, Optimal Policy를 구하고자 하는 State-Space Planning만을 다루고 있다. State-Space Planning은 아래와 같이 Model이 예상한 Simulated Experience를 사용하여 Value function을 업데이트하고, 이를 통해 보다 나은 Policy를 구하는 형식으로 이뤄진다.

Learning & Planning
이러한 점에서 State-Space Planning은 실제 환경이 아닌 Model of Environment와의 상호작용으로 얻어진 경험들을 사용하여 Policy를 업데이트한다는 점에서만 차이가 있을 뿐 기본적인 강화학습 방법론으로 Policy를 업데이트하게 된다. 아래 예시에서 확인할 Dyna-Q를 비롯하여 Model of Environment를 사용하는 강화학습 방법론들은 Simulated Experience와 더불어 실제 환경에서 얻은 Experience 두 가지 모두를 사용하여 Policy를 업데이트 하게 된다.
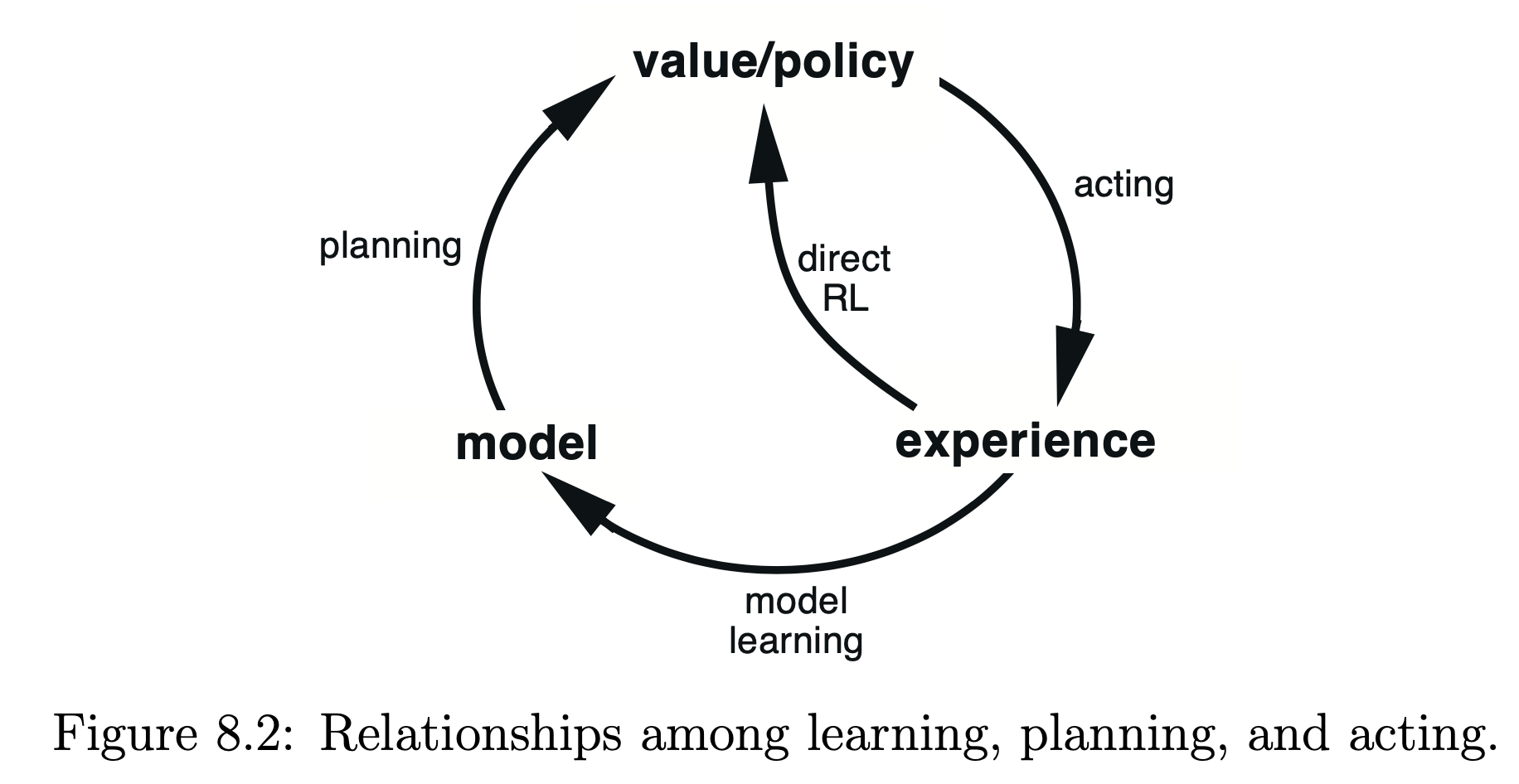
위의 그림에서 두 가지 경우를 모두 확인할 수 있다. Direct RL이 실제 환경에서 얻은 Experience로 Policy를 개선하는 것을, Planning(Model Learning)이 Modole of Environment를 통해 얻은 Simulated Experience로 Policy를 개선하는 것을 의미한다.
Planning: Pros & Cons
Planning을 통한 업데이트가 잘 이뤄지기 위해서는 당연하게도 Model of Environment가 정확하게 실제 환경을 반영하여야 한다. 이러한 점에서 본다면 Model of Environment를 사용한다는 것 자체가 Agent 이외에 새로운 Model을 정확히 구해야 한다는 것이고, 또다른 부담이 된다. 게다가 아무리 정확히 환경을 모사한다 할지라도 실제 환경과 비교해 본다면 미묘한 차이(bias)는 존재할 수 밖에 없다.
이와 같이 명백한 단점이 있음에도 불구하고 Planning은 이를 상쇄할 만한 장점들을 가지고 있는데, 대표적인 것이 학습을 위해 요구되는 환경과의 상호작용 횟수를 크게 줄일 수 있다는 점이다. Gym과 같이 잘 정의되어 있는 시뮬레이터 환경이 아니라면 실제 환경과의 상호작용에 많은 비용이 발생하는 경우가 많은데, 이러한 경우 Planning을 사용하면 비용을 크게 줄일 수 있다. 아래에 예시로 나오는 Dyna-Q에 딥러닝 모델을 적용한 Deep Dyna-Q 포스트에서 이러한 문제의식을 확인할 수 있다.
Example: Dyna-Q
Dyna-Q는 위의 Figure 8.2를 거의 그대로 구현하고 있다. Policy와 실제 환경의 상호작용을 통해 얻는 Real Experience를 (1) Direct RL Update에 사용(왼쪽 화살표)하기도 하고, (2) Model of Environment를 업데이트하는 데에 사용(오른쪽 화살표)하기도 한다. 학습을 통해 Model of Environment가 보다 정확해지면 해질수록 Simulated Experience가 실제와 가까워질 것이다. 이를 통해 적은 수의 Real Experience 만으로도 Policy를 업데이트하는 횟수를 크게 늘릴 수 있다.
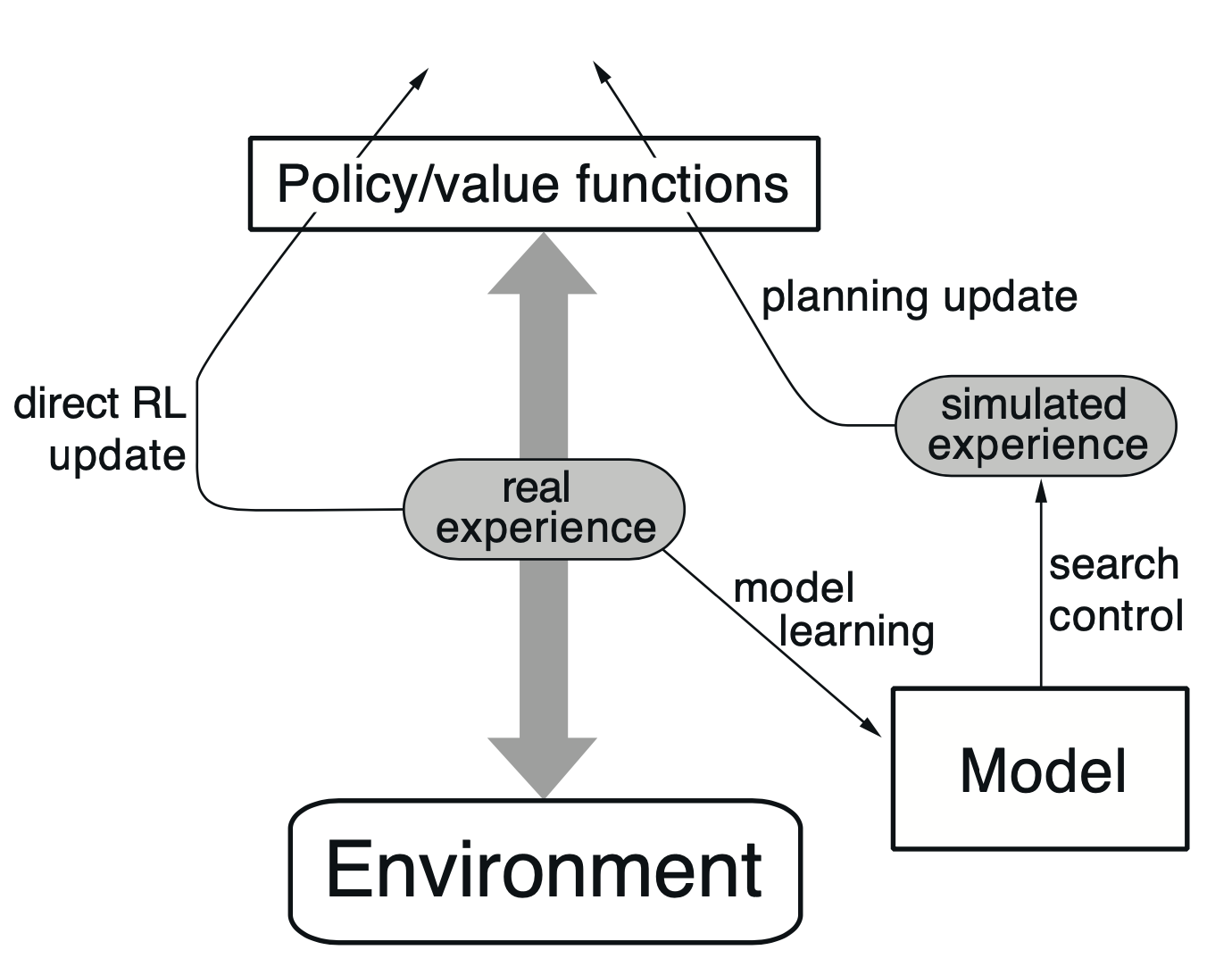
책에서는 왼쪽 부분을 Direct RL Process, 오른쪽 부분을 Model Based Process라고 한다.