Markov Property and Bellman Equation
- Sutton의 2011년 책 Reinforcement Learning: An Introduction 2nd edition을 참고해 작성했습니다.
Summary
- Markov Property란 현재 State에 담긴 정보 만으로도 과거 State 정보가 없더라도 충분히 미래에 어떤 일이 벌어질 지 알 수 있다는 특성을 의미한다.
- Bellman Equation은 Current State Value와 Next State Value의 관계를 나타내는 식으로, 이를 통해 Value Function을 보다 정확하게 업데이트하는 것이 가능하다.
- 더 좋은 Policy란 모든 State/State-Action Pair에 대해 Value Function의 값이 항상 더 큰 Policy를 의미한다.
Agent-Environment Interaction
강화학습은 학습의 주체이자 의사결정자인 Agent와 이를 둘러싸고 있는 외부 환경 Environment 간의 상호작용을 바탕으로 학습이 이뤄진다.
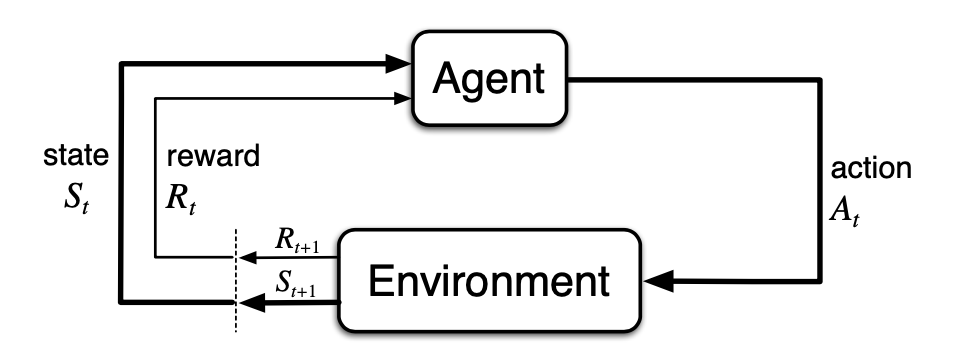
위 그림은 Agent와 Environment 간의 상호작용을 보여주고 있다. 하나씩 살펴보면 Agent는 현재 State \(s_t\)에 따라 가장 적절하다고 판단한 Action \(a\)를 Environment에 전달한다. 그럼 Environment는 그에 맞춰 Reward \(r_{t+1} \in R\)와 Next State \(s_{t+1} \in S\)을 정하여 Agent에게 알려주는 식이다. 강화학습은 이러한 Agent와 Environment 간의 반복적인 상호작용의 결과로 장기적인 관점에서 좋은 행동을 취하는 Agent를 학습하는 것을 목표로 한다. Agent와 Environment 간의 상호작용을 정의하는 데에 사용되는 기본적인 개념들로는 아래와 같은 것들이 있다.
State \(s_t\)
State란 Environment가 Agent에게 현재 상태가 어떠한지 알려주는 정보라고 할 수 있다. 이때의 State는 반드시 현재 상태를 알려주는 정보일 필요는 없고 복잡한 처리 과정을 거쳐 추출한 정보이거나, 과거의 정보들을 Sequence로 제공해주는 것도 가능하다.
Action \(a_t\)
Agent가 현재 State를 바탕으로 결정한 행동을 의미한다. Action의 형태는 다양하며 Agent가 임의로 통제할 수 있는 값이라면 모두 Action이라고 할 수 있다. 이러한 점에서 Agent와 Environment를 구분하는 경계는 Agent에 의한 자유로운 통제의 가능성에 있다.
Policy \(\pi(a \lvert s)\)
Agent는 Environment로부터 현재 State를 전달받아 그에 맞춰 적절한 Action을 결정한다고 했었다. 즉 Agent는 내부적으로 State를 Action으로 매핑하는 기능을 가지게 되는데, 이를 Policy라고 부른다. 한마디로 Policy는 State를 Action으로 매핑하는 함수이며 \(\pi(a \lvert s)\)로 표기한다. 그리고 강화학습의 목표는 이 Policy를 적절히 변화시켜 받을 수 있는 Reward의 총합을 극대화시키는 것이다.
Reward \(r_t\)
Reward는 매 time step 마다 주어지며, 이전 시점에서의 State, Action 조합이 얼마나 좋았는지 알려주는 지표라고 할 수 있다. 실제 문제에 강화학습을 적용할 때 학습에 큰 영향을 미치는 요소 중 하나가 Reward Shaping, 그러니까 Reward를 언제 어떻게 줄 것인지 결정하는 것이다. 책에서는 Reward Shaping과 관련해 다음과 같은 내용들을 언급하고 있다.
- Reward는 Agent에 의해 계산되는 것이 아닌 Environment에 의해 주어지는 것이어야 한다.
- Reward는 Agent가 최종적으로 달성해야 하는 목표를 알려줘야 한다. 그 과정이나 방법을 알려주는 방향으로 Reward를 설정하면 안 된다.
- Sub Goal을 여러 개 설정하면 비교적 쉬운 Sub Goal만 반복적으로 달성하고 Real Goal을 찾으려는 노력을 하지 않게 된다. 즉 Chess를 예로 들면 승리한 경우에만 Reward를 받아야 한다.
Return \(G_t\)
특정 시점 \(t\) 이후에 받을 Reward의 총합을 Return 이라고 하고 \(G_t\)로 표기한다. 강화학습은 경험을 통해 Agent가 Policy를 변화시켜 누적 Reward를 극대화하는 것이라고 했는데, 이때 누적 Reward가 바로 Return이다.
Simplist Sum Return
Return을 계산하는 방법은 크게 두 가지가 있는데 첫 번째 방법은 아래와 같이 단순히 모든 time step에서의 Reward를 더하는 Simplest Sum Return이다.
\[G_t = r_{t+1} + r_{t+2} + ... + r_{T}\]여기서 \(T\)는 Terminal State로, 말 그대로 하나의 Episode가 끝나는 State를 의미하며 이에 도달하게 되면 Environment는 Starting State 또는 Starting State Distribution에 따라 임의로 결정한 State로 돌아가게 된다.
Discounted Return
그런데 Task의 종류에 따라서는 Treminal State가 존재하지 않을 수도 있는데, 이 경우 위의 Simplest Sum 방법으로는 Return이 무한이 되어버린다. 따라서 아래와 같이 Discounted Factor \(\gamma\)를 도입해 시점에 따라 가중치를 달리하여 더하는 방법이 있다. 이러한 Return을 Discounted Return이라고 한다. 참고로 Terminal State를 가지는 문제를 Episodic Task라 하고 그렇지 않은 문제를 Continuing Task라고 한다.
\[\eqalign{ G_t &= r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+2} + ... = \Sigma_{k=0}^\infty \gamma^k r_{t+k+1} }\]Discounted Factor \(\gamma\)는 1보다 작아야 \(G\)의 크기가 무한히 커지지 않으며, 크기가 커지면 커질수록 미래 Reward가 미치는 영향이 커진다. 그리고 \(\gamma = 0\)이면 현재의 Reward만 고려하게 된다. 실제 구현에서는 0.99를 많이 사용하는 편이다.
Markov Property
강화학습에서 가장 중요한 가정 중 하나인 Markov Property에 대한 정의는 다음과 같다.
- In probability theory and statistics, the term Markov property refers to the memoryless property of a stochastic process. … A stochastic process has the Markov property if the conditional probability distribution of future states of the process (conditional on both past and present values) depends only upon the present state (Wiki).
한 마디로 풀어보자면 Markov Property란 확률 프로세스 중 현재 State만을 조건으로 미래 State 프로세스의 확률분포가 결정되는 특성을 말한다. Markov Property의 핵심적인 키워드는 Memoryless로, 과거 State에 대한 기억 없이 현재 State에 담긴 정보 만으로도 미래에 벌어질 일을 예측하는 것이 가능하다는 의미로 이해할 수 있다.
\[\eqalign{ &1. \ Pr \{ r_{t+1}=r, s_{t+1}=s' \lvert s_0, a_0, r_1, ... r_t, s_t, a_t \} \\ &2. \ Pr \{ r_{t+1}=r, s_{t+1}=s' \lvert s_t, a_t \} }\]Markov Property를 만족한다는 것은 위의 두 식이 완벽하게 동일하다는 것을 의미한다. 따라서 현재 시점의 State와 Action 만으로도 충분히 그에 대한 Reward와 Next State를 알 수 있다. 이는 곧 Markov State만으로도 Agent가 최선의 Action을 선택하는 데에 충분한 정보를 담고 있다는 것을 의미한다.
Markov Decision Process(MDP)
Markov Property가 중요한 이유는 강화학습이 Markov Decision Process(MDP)에 기반하여 문제를 정의하고 있기 때문이다. MDP는 확률적인 환경 속에서 일정 시간마다 의사결정을 내려야 하는 상황을 수학적으로 모델링하는 방법이라고 할 수 있다. MDP의 주요 키워드는 다음과 같다.
- Stochastic(Randomness): MDP는 불확실성이 존재하는 환경을 가정한다. Agent가 결정할 수 있는 것은 Action 하나 뿐이며, 이외의 모든 것은 임의로 주어질 수 있다.
- Discrete Decision Making: MDP는 Time Step마다 의사결정을 해야 하는 경우를 가정한다. 이때 Time Step 간의 간격은 가변적일 수 있다.
- Sequential Decision Making: MDP는 과거의 결정이 현재의 상황에 영향을 주는 상황에서 반복적으로 의사결정을 해야 하는 경우를 가정한다.
MDP는 \(<S, A, P, R>\) 네 가지 요소로 정의된다.
- \(S\) : State Space
- \(A\) : Action Space
- \(P\) : State Transition Probability
- \(R\) : Reward Function
State Space와 Action Space가 유한한 경우를 Finite MDP라고 하는데, 강화학습에서 다루는 많은 문제들이 Finite MDP라고 한다. Finite MDP를 만족한다면 State \(s\), Action \(a\)와 Next State \(s'\), Reward \(r\)의 관계는 다음과 같이 One-Step Dynamics로 정의할 수 있다.
\[P(s', r \lvert s, a) = Pr \{ s_{t+1} = s', r_{t+1} \lvert s_t = s, a_t = a \}\]현재 State \(s\)에서 어떤 Action \(a\)를 선택했을 때 환경으로부터 다음 State \(s'\)와 Reward \(r\)을 받을 확률을 의미한다. 위의 식을 기반으로 하여 MDP의 구성 요소로 현재 State \(s\)에서 Action \(a\)를 취했을 때 다음 State로 \(s'\)이 주어질 확률을 의미하는 State Transition Probability \(P\)를 정의할 수 있다.
\[\eqalign{ \text{State-Transition Probability : }P(s' \lvert s, a) &= Pr \{ s_{t+1} = s' \lvert s_t = s, a_t = a \} \\ &= \Sigma_{r \in R} p(s', r \vert s, a) }\]Reward Function \(R\) 또한 다음과 같이 정의할 수 있다.
\[\eqalign{ \text{Reward Function : }r(s, a) &= E[r_{t+1} \lvert s_t = s, a_t = a]\\ &= \Sigma_{r \in R} r \Sigma_{s' \in S} p(s',r \vert s, a) \\ }\]Reward Function과 State-Transition Probability는 Environment의 특성을 결정하는 함수로서 시뮬레이터 환경에서는 필요에 따라 이를 조절하여 Agetnt가 특정한 행동을 선택하도록 만들 수 있다. 이때 중요한 것은 Agent는 Environment가 어떤 Reward Function과 State-Transition Probability를 가지는지 추측할 수 있는 정보는 충분히 가지되, 환경 내부에 정의된 각 함수에는 접근할 수 없어야 한다는 것이다. 즉 Agent 입장에서 Next State와 Reward는 철저하게 주어지는 것이어야 한다.
Value Function
Value Function은 특정 State(또는 State- Action Pair)가 얼마나 좋은지, 즉 기대할 수 있는 Expected Return이 어떻게 되는지 알려주는 함수를 말한다. 대부분의 강화학습 알고리즘은 이 Value Function을 정확하게 추정하는 방향으로 학습이 이뤄진다. Value Function을 정확하게 알면 그에 맞춰 Action을 선택하면 되기 때문이다.
Value Function의 중요한 특징 중 하나는 특정 Policy에 따라 정의된다는 것이다. 예를 들어 \(V_\pi(s)\)는 State \(s\)에서 시작하여 어떤 Policy \(\pi\)에 따라 Action을 선택할 때 받을 수 있을 것으로 기대되는 Expected Return 이라고 할 수 있다. 그리고 Value Functiond에는 State Value Function과 Action Value Function 두 가지가 있는데, 각각 State, State-Action Pair에 대한 Expected Return을 추정한다. 구체적으로 State Value Function \(v\)는 특정 State가 얼마나 좋은지를 알려주는 함수로 다음과 같이 구해진다.
\[\eqalign{ v_\pi (s) &= E_\pi [G_t \lvert s_t = s]\\ &= E_\pi [\Sigma_{k=0}^\infty \gamma^k r_{t+k+1} \lvert s_t = s] }\]특정 State에서 어떤 Action을 하는 것이 얼마나 좋은지 알려주는 Action Valun Function \(q\)는 다음과 같다.
\[\eqalign{ q_\pi (s, a) &= E_\pi [G_t \lvert s_t = s, a_t = a]\\ &= E_\pi [\Sigma_{k=0}^\infty \gamma^k r_{t+k+1} \lvert s_t = s, a_t = a] }\]Value Function을 정확하게 추정하기 위해서는 당연히 Environment와 많은 상호작용을 해야 한다. 경우에 따라서는 동일한 State에서 동일한 Action을 하더라도 받게 되는 Reward가 달라질 수 있으며, 이 경우 Reward의 Variance를 줄이기 위해서라도 더 많은 상호작용이 필요할 것이다.
Bellman Equation
Value Fucntion의 가장 큰 특징 중 하나는 아래와 같이 재귀적으로 Next State \(s'\)에 대한 value function으로 표현할 수 있다는 점이다. 이를 Bellman Equation이라고 한다.
\[\eqalign{ v_\pi(s) &= E_\pi[G_t \lvert s_t = s] \\ &= E_\pi [\Sigma_{k=0}^\infty \gamma^k r_{t+k+1} \lvert s_t = s]\\ &= E_\pi [r_{t+1} + \gamma \Sigma_{k=0}^\infty \gamma^k r_{t+k+1} \lvert s_t = s]\\ &= E_\pi [r_{t+1} + \gamma G_{t+1} \lvert s_t = s]\\ &= E_\pi [r_{t+1} + \gamma v(s_{t+1}) \lvert s_t = s]\\ }\]Bellman Equation은 어느 State \(s_t\)의 Value를 Next State \(s_{t+1}\)의 기대 (Discounted) Value와 Reward \(r_{t+1}\)의 합으로 표현할 수 있게 해준다. 이에 따라 특정 시점의 State Value는 Next State Value를 기준으로 더욱 정확하게 업데이트 할 수 있게 되는데(Action Value에 대해서도 물론 가능하다), 이를 Backup Operation이라고 한다. Sutton은 책에서 Backup Operation을 강화학습 방법론의 심장이라고 표현하고 있다.
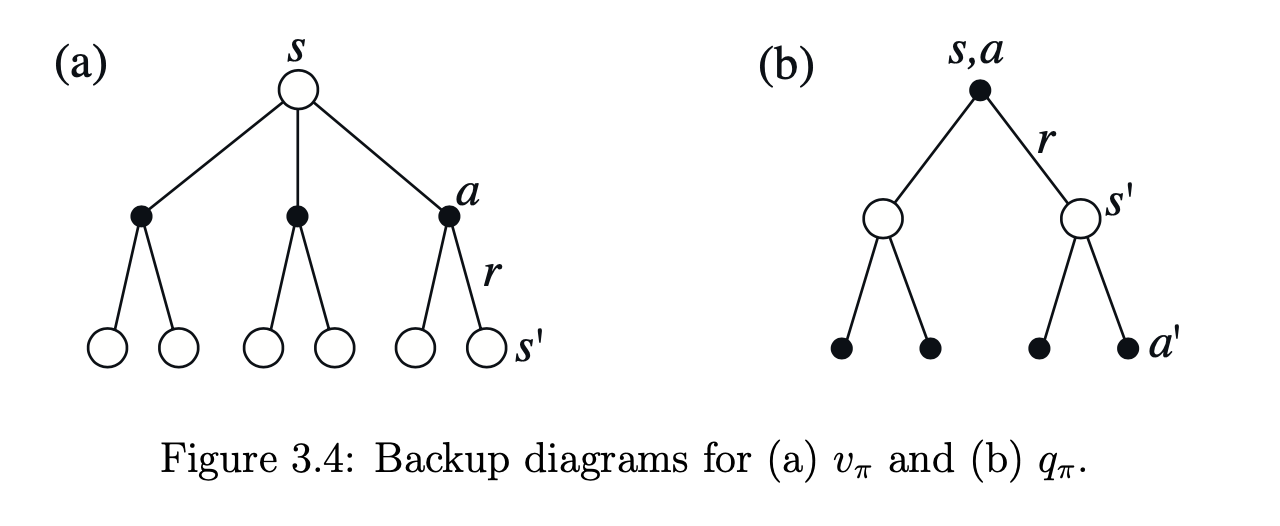
Optimal Value Function
Value Function을 정의했다면 이를 사용하여 어떠한 Policy가 더욱 좋은 Policy인지 개념적으로 정의하는 것도 가능하다. State Value Function의 값이 각 State에서 받을 수 있을 것으로 기대되는 Expected Return 이라고 했으므로 모든 State에 대해 \(v_\pi(s) > v_{\pi'}(s)\)가 성립한다면 \(\pi\)를 따를 때 \(\pi'\)를 따르는 것보다 어디에서나 더 큰 Return을 받는다는 것을 의미하게 된다. 이와 같은 경우에 대해서만 \(\pi\)가 \(\pi'\)보다 더 좋은 Policy라고 할 수 있다.
\[\pi \geq \pi' \qquad \text{ if and only if } v_\pi(s) \geq v_{\pi'}(s) \text{ for all } s \in S\]그리고 모든 Policy에 대해 위의 식이 성립하는 Policy를 Optimal Policy라고 하고 \(\pi^*\)로 표기한다. Optimal Policy를 따를 때의 State Value Function은 아래와 같이 정의되며 Optimal State Value Function이라 한다.
\[v^*(s) = \max_\pi v_\pi(s) \quad \text{For all state } s \in S\]Optimal Action-Value Function은 다음과 같다.
\[q^*(s, a) = \max_\pi q_\pi(s, a) \quad \text{For all state } s \in S \text{ and action } a \in A\]그리고 둘 사이에는 다음과 같은 관계가 성립한다.
\[q^*(s, a) = E[r_{t+1} + \gamma v^*(s_{t+1}) \lvert s_t = s, a_t = a]\]마지막으로 어떤 state \(s\)에서 Optimal Action-Value Function \(q^*\)에 따라 그 값이 가장 큰 Action \(a\)를 결정한다면 기대 Return을 극대화할 것으로 기대할 수 있다. 이러한 점에서 Optimal Policy \(\pi^*\)는 다음과 같이 정의할 수 있다.
\[\pi^*= \eqalign{ & 1 \qquad \text{ if } \ a = \arg \max_a q^*(s, a) \\ & 0 \qquad \text{ otherwise} }\]즉, Optimal Value Function을 계산한다면 Optimal Policy를 알 수 있다.
Bellman Optimality Equation
Optimal을 가정하게 되면 위와 같이 State \(s\)에서 \(q(s, a)\)의 크기가 가장 큰 Action \(a\)를 선택하게 된다. 따라서 다음과 같은 식이 성립하는데 이를 Bellman Optimality Equation이라고 한다.
\[\eqalign{ v(s)^* &= \max_{a \in A(s)} q_{^*}(s, a) \\ &= \max_{a \in A(s)} \Sigma_{s', r} p(s', a \lvert s, a) [r + \gamma v^*(s')] }\]\(q\)에 대해서도 다음과 같이 성립한다.
\[\eqalign{ q^*(s, a) &= E[r_{t+1} + \gamma \max_{a'} q^*(s_{t+1}, a') \lvert s_t = s, a_t = a] \\ &= \Sigma_{s', r} p(s', r \lvert s, a) [r + \gamma \max_{a'} q^*(s',a')] }\]Optimal에서의 Back-up Diagram은 다음과 같다.
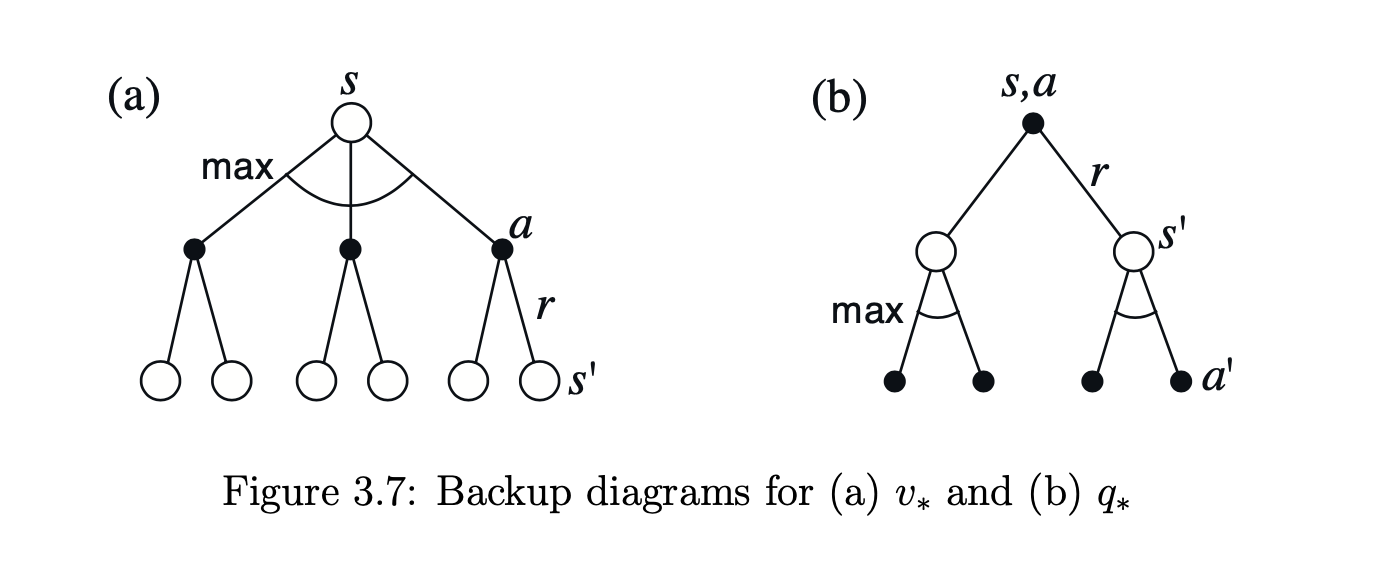
Optimality and Approximation
강화학습 문제는 결국 Optimal Policy가 무엇인지 알아내는 과정이다. 하지만 Optimal Policy를 정확하게 구하기 위해서는 매우 많은 비용이 드는데, 구체적으로 다음 두 가지 문제를 생각해 볼 수 있다.
- Optimal Policy를 Bellman Equation으로 구하기 위해서는 매우 많은 연산량을 요구한다.
- Optimal Policy 혹은 Optimal Value Function을 구했다고 할지라도 모든 State, Action에 대해서 정보를 저장하려면 매우 많은 메모리가 필요하다.
이때 State의 개수가 적고 유한하다면 array, table 형태로 데이터를 저장하고 이를 바탕으로 Optimal Policy를 근사하는 것이 가능하다. 이를 Tabular Case라고 하며 이러한 방법으로 근사하는 것을 Tabular Method라고 한다.
Agent-Environment Interaction을 샘플링하고 이를 기준으로 근사하는 방법은 state의 방문 빈도에 따라 정확도가 달라질 수 있다는 문제에서 자유롭지 못하다. 방문할 확률이 낮은 state의 경우 그 값이 정확하지 않을 가능성이 높고, 이 경우 좋지 못한 행동을 할 가능성이 높아진다. 이러한 문제는
- 자주 방문하는 State에 대해서만 많이 학습하게 된다는 점
- 방문 빈도가 낮은 경우 Sub Optimal을 선택하더라도 전체에 미치는 영향이 낮다는 점
등으로 인해 발생한다. 이러한 문제 때문에 경우에 따라서는 프로들과만 바둑을 두며 높은 승률을 기록한 강화학습 알고리즘이 초보들과의 바둑에서는 승률이 그보다 낮을 수 있다.