Gradient Descent
- Ian Goodfellow, Yoshua Bengio, Aaron Courville의 Deep Learning Book을 참고하여 작성했습니다.
Gradient Descent
Objective function
objective function이란 극대화 또는 극소화하고자 하는 대상 함수를 말한다. 극대화 문제는 음수를 취하면 극소화 문제로 간단히 표현할 수 있기 때문에, 최적화 이론에서는 극소화 문제를 중심으로 다루는 것이 일반적이다. 극소점을 표현할 때 \(x^*\)를 사용하며, 수학적으로는 다음과 같이 표현된다. 참고로 objective function은 경우에 따라서는 cost function, loss function 등으로 불리기도 한다.
\[x^* = \arg \min f(x)\]함수의 극소점을 찾는 것은 쉽지 않은데, 미분을 이용하면 함수 위의 어떤 지점에서 극소점이 어디에 위치해있는지 짐작할 수 있다. 어떤 함수의 미분 값은 함수 위의 어떤 지점에서 경사의 기울기를 의미하기 때문에 미분 값을 통해 어느 방향이 높고 낮은지 알 수 있기 때문이다. 수학적으로는 다음과 같이 표현할 수 있다.
\[f(x -\epsilon \ sign(f'(x))) < f(x)\]딥러닝에서 사용하는 Gradient Descent가 바로 이러한 원리를 이용한다.
Gradient
함수의 입력이 복수인 경우(\(f : \rm I\!R^n \rightarrow \rm I\!R\))에도 기울기를 구한다는 점에서는 크게 다르지 않는데, 이때는 단순 미분으로 구할 수 없고 각각의 변수에 대한 편미분을 통해 함수의 기울기를 구하게 된다. 따라서 기울기 또한 입력과 크기가 동일한 vector 값으로 구해지는데, 이를 Gradient라고 한다. 즉 Gradient란 편미분 값으로 이뤄진 vector를 의미하며 수학 기호로는 \(\nabla_x f(x)\)로 표현된다.
\[\nabla f = {\partial f \over \partial x} p + {\partial f \over \partial y} q + {\partial f \over \partial z} r\]위의 그림은 입력이 3개인 경우이며, 여기서 p, q, r은 각각 x축, y축, z축의 단위 벡터를 의미한다. 참고로 단위 벡터란 벡터의 크기가 1인 vector를 말하며, 방향을 표현하기 위해 사용하는 벡터라고 할 수 있다. 즉 각 축에 대한 편미분 값을 각 축의 방향을 표현하는 단위 벡터에 곱하여 모두 더한 값이 Gradient가 된다.
Directional Derivative
Gradient 방향으로 이동하면 최저점에 보다 가까워진다는 것은 Directional Derivative를 통해서도 확인할 수 있다. Directional Derivative란 우리 말로 하면 방향도함수인데, 이는 벡터 공간에서 함수 상의 어떤 지점에서 임의의 방향이 갖는 변화율을 구하기 위해 사용된다. 방향도함수는 방향에 따른 변화율을 표현하므로 그 값이 음수라면 해당 방향으로 움직였을 때 그 값이 줄어든다는 것을 의미한다고 할 수 있다. 어떤 함수 \(f\)의 방향도함수는 Gradient \(\nabla f\)와 임의의 방향을 의미하는 단위 벡터 \(v\) 간의 내적(dot product)로 구할 수 있음이 증명되어 있다.
우리의 목표는 함수 \(f\)를 최소화하는 방향을 찾는 것이므로, 가장 빠르게 줄어드는 방향 \(u\)를 찾아야 한다. 이때 방향도함수의 값이 가장 작은 방향이 \(f\)를 최소화시켜주는 방향이 되기 때문에 다음과 같이 표현된다.
\[\min v \cdot \nabla_x f(x)\]이는 내적의 계산 방법에 따라 다음과 같이 표현된다.
\[= min \| v \|_2 \| \nabla_x f(x) \|_2 cos \theta\]여기서 \(\theta\)는 Gradient와 단위벡터 \(v\) 간의 각도를 의미한다. \(v\)는 단위벡터이므로 L2 NORM(L2 NORM은 유클리드 공간에서의 벡터의 크기를 의미)이 1이며, \(\nabla_x f(x)\)는 찾고자 하는 단위 벡터 \(v\)와 무관하다. 결국 위의 최소화 문제는 \(cos \theta\)를 최소화하는 문제가 된다. \(cos \theta\)는 \(1\pi\), 즉 180도에서 극소점을 가지므로 결과적으로 \(f\)를 최소화하기 위해서는 \(\nabla_x f(x)\)의 방향과 반대되는 방향으로 업데이트해야 한다.
\[x' = x - \epsilon \ \nabla_x f(x)\]이렇게 업데이트 하는 것, 즉 Gradient와 반대방향으로 업데이트 하는 방법을 Gradient Descent라고 한다.
Local Minimum and Global Minimum
\(f'(x) = 0\)이면 어느 방향으로 업데이트해야할지 알 수 없는데, 이러한 지점을 critical point 또는 stationary point라고 한다. critical point는 다음 세 경우로 나누어진다. 참고로 함수의 입력이 복수인 경우에는 모든 편미분 값이 0인 지점이 된다.
- local minimum : \(f(x)\) 상의 점들 중 모든 주변 점들보다 작은 점
- local maximum : \(f(x)\) 상의 점들 중 모든 주변 점들보다 큰 점
- saddle point : \(f'(x)=0\)을 만족하면서 \(f(x)\) 상의 점들 중 주변에 있는 점들보다 크기도 하고 작기도 한 점
즉 \(f'(x) = 0\)을 만족한다고 해도 local minimum이라는 것을 보장할 수 없다.
Gradient Descent의 문제 중 하나는 local이라는 표현에서도 알 수 있듯이 local minimum은 찾을 수 있어도 항상 global minimum을 찾는 것이 보장되지는 않는다는 점이다. 딥러닝의 경우 목적 함수가 복잡하여 매우 많은 수의 local minimum, local maximim, saddle point를 가지고 있으며, flat region 또한 자주 난다. 그리고 입력의 차원 또한 크기 때문에 이러한 점들이 네트워크의 학습을 어렵게 하는 원인이 된다.
Update Network with Gradient Descent
딥러닝에서 데이터셋이 주어져 있고, 이것에 대해 Gradient Descent 방법으로 학습을 진행한다는 것은 아래와 같은 objective function의 크기를 최소화하는 방향으로 네트워크를 업데이트하겠다는 것을 의미한다.
\[J(\theta) = E_{(x,y) \backsim \hat P_{data}} L(f(x;\theta), y)\]여기서 loss function \(L(\cdot)\)은 모델의 예측값 \(f(x;\theta)\)와 레이블 \(y\)를 통해 계산된다. 위 식을 풀이하자면 주어진 데이터셋 \(\hat p_{data}\)에 대한 expected loss가 objective function이 된다는 것이다.
한 가지 눈여겨 봐두어야 할 것이 있다면 objective function의 입력값으로 \(\theta\)가 주어진다는 것이다. 여기서 \(\theta\)란 네트워크 파라미터를 뜻하는데, 딥러닝을 포함한 머신러닝에서는 데이터는 주어진 것으로 간주하고 이에 네트워크 등 모델을 업데이트하여 loss가 작아지도록 맞추게(fitting) 한다는 점에서 이를 이해할 수 있다.
Condition of Gradient Descent Update
Gradient Descent 방법을 이용하여 네트워크를 학습시키기 위해서는 조건이 있는데, 그 중 하나가 아래와 같이 전체 데이터에 대한 loss function의 기대값이 개별 데이터의 loss function 값의 합과 동일해야 한다는 점이다.
\[J(\theta) = E_{x,y \backsim \hat p_{data}}L(x,y,\theta) = {1 \over m} \Sigma_{i=1}^m L(x^{(i)}, y^{(i)}, \theta)\]그 중 대표적인 것이 딥러닝 학습에 많이 사용되는 Negative Log-Likelihood(NLL) loss function이다.
\[\eqalign{ & \text{when} \ L(x,y,\theta) = -\log p(y \lvert x; \theta),\\ & \nabla_\theta J(\theta) = {1 \over m} \Sigma^m_{i=1} \nabla_\theta -\log p(y^{(i)} \lvert x^{(i)}; \theta) }\]위와 같은 특성을 갖는 loss function을 사용하면 전체 데이터셋을 통해 한 번 Gradient Descent를 수행하는 것과 한 번에 하나의 데이터를 이용해 Gradient를 구하고 이를 이용해 조금씩 업데이트하는 것이 동일해진다.
Three ways of Gradient Descent
Stochastic Gradient Descent
그런데 위 식을 그대로 적용하게 되면 전체 데이터셋에 대한 loss를 모두 구해야 모델을 한 번 업데이트 할 수 있다. 이러한 방법은 업데이트 속도가 느리고 한 번의 업데이트를 위해 많은 연산을 처리해야하므로 메모리 등 컴퓨터 자원을 많이 요구하게 된다. Stochastic Gradient Descent(SGD)는 이러한 문제를 해결하기 위해 제시된 방법이다.
Batch, Minibatch, SGD
전체를 나누어 Gradient를 계산해도 된다는 SGD의 개념을 생각해 볼 떄, Gradient Descent를 적용하는 데에는 한 번에 사용하는 데이터의 개수를 기준으로 크게 세 가지 방법이 가능하다는 것을 알 수 있다. 첫 번째는 전체 데이터셋을 모두 이용하여 Gradient를 구하는 Batch Gradient Descent, 두 번째는 한 번에 하나의 데이터만 사용하는 Stochastic Gradient Descent, 마지막으로 정해진 개수의 데이터만을 부분적으로 사용하는 mini-batch Gradient Descent가 있다.
세 가지 방법은 업데이트 방식에서 약간의 차이가 있다. 이를 위해 network \(\theta\)가 업데이트 되는 과정을 매우 간단하게 다음 그림으로 표현해보았다. 아래 그림에서 x는 네트워크의 입력 데이터를 의미하며, 전체 데이터의 갯수는 9개이다. 또한 현재의 \(\theta\) 값에 맞게 검은 선으로 \(\theta_t\)일 때의 objective function을 나타내고 있으나, \(\theta\) 값이 연속적인 만큼 그 값의 변화에 따라 \(J(\theta)\)도 그림의 \(\theta\)축을 따라 연속적으로 변한다고 할 수 있다.
보라색은 SGD, 그러니까 하나의 데이터만 사용해서 업데이트하는 방법을 표현하고 있다.
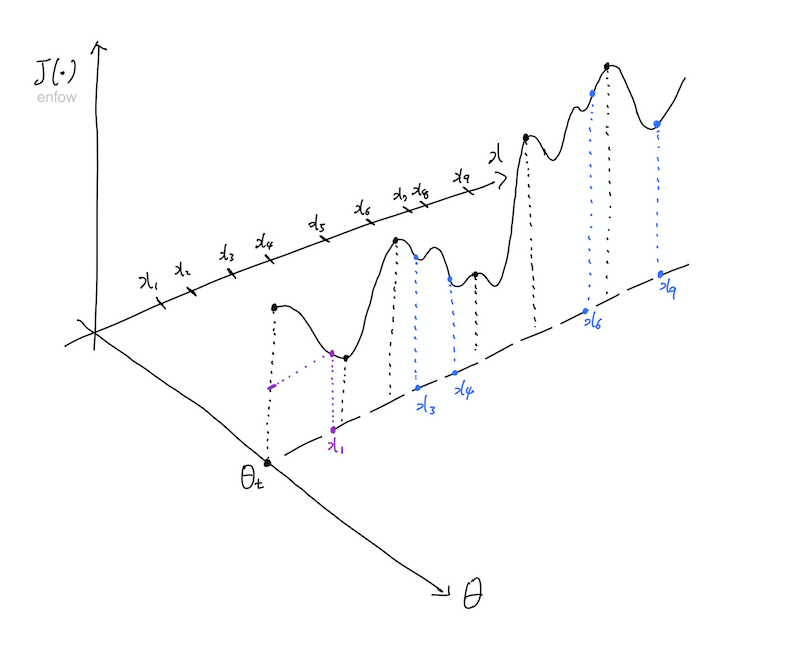
SGD에서 데이터로 \(x_1\)이 들어왔다고 가정해보자. 이때의 loss는 위의 그림과 같이 표현된다. 업데이트는 objective function의 Gradient 값인 \(\nabla_\theta J(\theta)\)에 의해 결정되므로 이것의 기울기를 구할 필요가 있다. 여기서 중요한 것은 기울기를 구하는 방향인데, 아래와 같이 \(\theta\)축을 기준으로 구해야 한다.
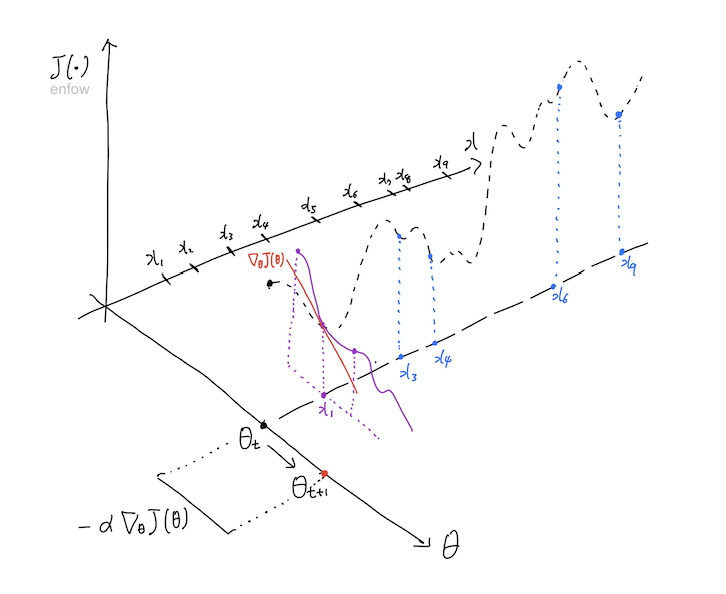
즉, 검은 선의 기울기가 아니라 보라색 선의 기울기에 따라 업데이트의 크기와 방향을 결정해야 한다. 위의 그림의 빨간 선을 의미하는데, 여기서는 \(\nabla_\theta J(\theta)\)의 값이 음수이므로, \(\theta\)값이 커진 것을 확인할 수 있다. 보다 정확하게는 그림에 나와있듯이 \(- \alpha \nabla_\theta J(\theta)\)만큼 변화한다.
Minibatch와 같이 복수의 데이터를 사용하는 경우는 파란색으로 표현했다. 이 경우도 각각의 데이터에 대한 Gradient를 계산할 수 있는데, 업데이트의 방향은 위의 네 점의 Gradient 간의 평균으로 구하게 된다.
\[J(\theta) = {1 \over m} \Sigma_{i=1}^m L(x^{(i)}, y^{(i)}, \theta)\] \[\nabla_\theta J(\theta) = {1 \over m} \Sigma^m_{i=1} \nabla_\theta L(x^{(i)}, y^{(i)}, \theta)\]즉, SGD와 같이 한 개의 데이터를 쓰는 것과 Minibatch와 같이 복수의 데이터를 쓰는 것은 \(\nabla_\theta J(\theta)\)의 크기를 구하는 방법(그대로 쓰느냐와 평균을 내서 쓰느냐)에만 차이가 있다.
그리고 SGD와 같이 하나의 데이터에 따라 업데이트를 할 경우에는 전체가 아닌 일부의 data point만 사용하여 \(\nabla_\theta J(\theta)\) 값을 결정하기 때문에 variance가 크고, 그 결과 \(\theta\) 값의 변화 크기와 방향이 비교적 다양하게 나타난다. 이러한 이유로 SGD 또는 mini batch에서는 업데이트의 방향이 횡보하는 경우가 많다. 이것이 꼭 나쁘다고만 할 수는 없는 것이 local minimum에서 빠져나올 확률을 높여주는 방법이 되기 때문이다. 이는 보다 안정적인 수렴이 가능하다는 장점을 가지는 Batch Gradient Descent를 잘 사용하지 않는 이유 중 하나이다.
1) Batch Gradient Descent
Batch Gradient Descent는 전체 데이터셋(full training set)을 이용해 Gradient를 업데이트하는 방식을 말한다. 여기서 batch란 부분을 말하는 것이 아니라 전체를 의미한다.
Pros
- 전체 데이터셋을 이용하여 loss를 계산하므로 local minimum으로 안정적인 수렴이 이뤄질 가능성이 높다(횡보할 가능성이 낮다).
- 업데이트 횟수가 적다.
Cons
- local minimum에 빠질 가능성이 높다.
- 한 번 학습하는데에 시간이 오래 걸리며, 메모리 사용량이 높다.
2) Stochastic Gradient Descent
SGD는 한 번의 업데이트에 하나의 데이터로 구해진 loss를 사용하는 것이다. 즉 데이터를 하나만 사용한다.
Pros
- 전체가 아닌 부분의 데이터만 이용하기 때문에 횡보하며 이에 따라 local minimum에서 빠져나올 가능성이 높다.
- 한 번의 업데이트에 걸리는 시간이 짧다.
Cons
- global opimta를 찾지 못할 가능성은 여전히 존재한다.
- 메모리를 적게 요구한다는 점은 역으로 하드웨어를 효율적으로 사용하지 못한다는 것을 뜻한다.
3) Minibatch Gradient Descent
위의 두 가지 방법의 절충안으로 정해진 크기의 데이터를 사용해 loss를 구하는 방법이다. 이때 한 번에 사용되는 데이터를 전체 batch보다 작다는 뜻으로 mini batch라고 한다. 순수한 의미의 SGD는 잘 사용하지 않으며, mini batch 방식을 SGD라고 하는 경우가 많다.
Pros
- local minimum에 빠질 가능성이 낮다.
- 한 번에 사용되는 데이터의 크기를 조절할 수 있으므로 하드웨어의 성능을 적절하게 사용할 수 있다.
Cons
- 위의 두 가지 방법이 가지고 있는 문제가 조금씩 나타날 수 있으므로 batch size를 적절하게 설정해야 한다.
mini-batch의 경우 batch size를 어떻게 설정하는지가 중요하다. batch size가 너무 크면 SGD의 장점을 충분히 누릴 수 없고, batch size가 너무 작으면 Gradient 추정치의 variance가 커서 안정적인 업데이트가 어려울 수 있기 때문이다. 따라서 특히 batch size가 작은 경우라면 learning rate를 작게 하는 것이 안정적인 업데이트에 도움이 된다고 한다.
Optimizer
minibatch Gradient Descent를 기본으로 하여 여러 다양한 업데이트 방식들이 시도되어왔는데, 딥러닝에서 Optimizer라고 부르는 알고리즘으로 정리되어있다. 대표적인 Optimizer로는 SGD와, Adagrad, RMSProp 그리고 이 둘의 장점을 취하는 ADAM 등이 있다.
REFERENCE
- Gradient의 수학적 표현과 관련해서는 이 블로그를 참조했다.