Pytorch Training Routine
- update date: 2020.07.20
- Environment Setting: python(3.7.4), torch(1.5.1)
1. Introduction
Pytorch에서 classification model을 학습시키는 기본적인 Training Routine은 아래 코드와 같다( 출처 - training a classifier).
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
각각의 의미를 풀어쓰면 다음과 같다.
optimizer.zero_grad(): gradient를 모두 0으로 만들어 준다.outputs = net(inputs): 입력 데이터를 network에 통과시킨다.loss = criterion(outputs, labels): 현제 network의 loss를 계산한다.loss.backward(): 계산된 loss에 따라 backpropagation을 진행한다.optimizer.step(): gradient에 따라 network를 업데이트한다.
본 포스팅에서는 위의 5가지 줄이 가지는 의미를 보다 구체적으로 확인해 보고자 한다.
2. Network Parameters and Gradient
학습이 이뤄지는 과정을 살펴보기 전에 Pytorch에서 학습에 필요한 Gradient를 관리하는 방법에 대해 살펴보고자 한다. Pytorch에서는 네트워크를 구성하는 각 Layer들의 parameter들에 계산된 gradient가 저장되어 있고 업데이트가 필요한 시점에 저장된 값을 사용하여 parameter를 업데이트하게 된다.
구체적인 예시로 확인해보기 위해 Linear Module의 소스 코드를 살펴보면 다음과 같이 되어 있음을 확인할 수 있다.
class Linear(Module):
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
...
def forward(self, input):
return F.linear(input, self.weight, self.bias)
...
Fully Connected Network에서 하나의 layer를 구성하는 Linear Module의 코드를 살펴보면 gradient와 관련된 것이 선언되어 있지 않다. 대신 weight, bias로 저장되어 있는 torch.Tensor의 멤버 변수 grad에 각각의 gradient 값이 저장된다. 따라서 어떤 네트워크 net의 layer fc1이 가지고 있는 gradient 값을 확인하고 싶다면 다음과 같은 코드로 가능하다.
net.fc1.weight.grad
참고로 torch.Tensor()는 모두 grad를 멤버 변수로 가지고 있으며 아래와 같이 None으로 초기화되어 있다.
ts = torch.tensor([1,2,3])
print(ts) # tensor([1, 2, 3])
print(ts.grad) # None
None이 저장되어 있는 경우에는 backward()에 의해 graident가 계산된 후에야 실제 값이 할당된다. 이와 관련해서는 torch.Tensor()의 documenation에서 확인할 수 있다.
3. Calculating Gradient
학습을 진행하면서 network의 어떤 한 layer가 가지는 gradient의 합을 단계별로 구해보면 아래 그림과 같이 도식화 할 수 있다.
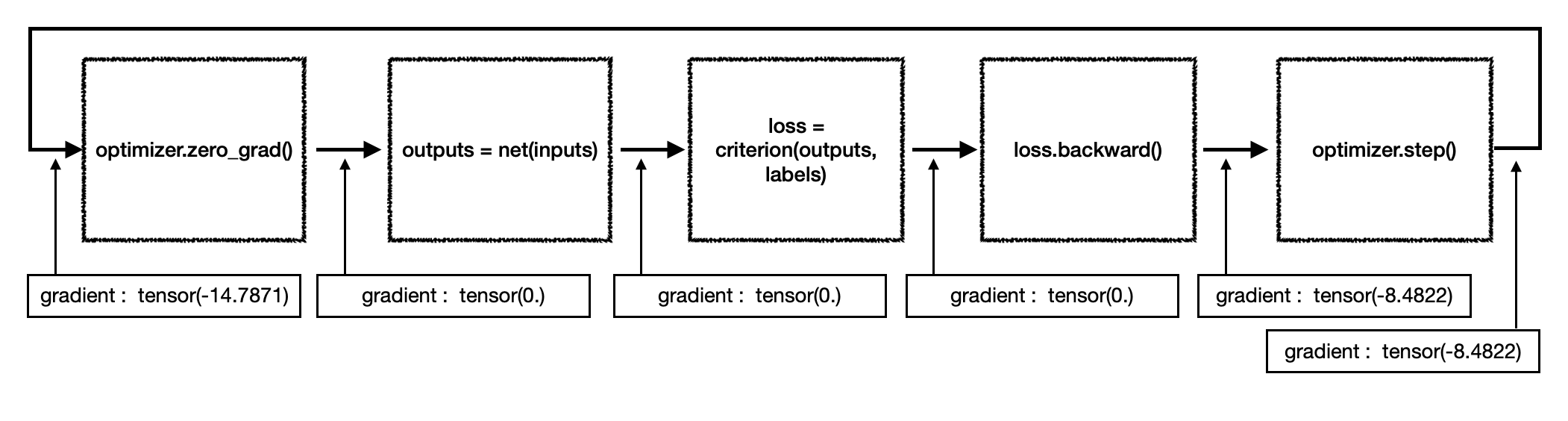
학습이 진행 중이므로 첫 번째 step에서는 그림의 tensor(-14.7871)과 같이 이전 mini batch를 통해 구해진 gradient가 여전히 각 layer에 남아있는 상태이다. 이전의 학습 방향 및 크기가 현재의 학습에 영향을 미치지 않도록 하기 위해서는 이를 0으로 만들어 주어야 하는데 optimizer.zero_grad()가 이와 같은 역할을 수행한다. 그림에서도 zero_grad()를 통과한 이후 layer의 gradient 값이 0이 되었음을 확인할 수 있다.
이후 gradient가 다시 업데이트 되는 순간은 loss.backward()이다. 즉 network의 output을 label과 비교하여 loss를 계산한 뒤 이를 오차역전파법(back propagation)에 따라 network layer의 역순으로 전파하는 단계에서 각 layer의 gradient가 업데이트 되는 것이다.
4. Update Network Parameters
parameter마다 계산된 gradient를 parameter에 빼주는 과정이 네트워크 업데이트라고 할 수 있다. 어떤 지점에서 네트워크 업데이트가 이뤄지는지 확인하기 위해 위의 gradient 도식처럼 parameter 합의 변화를 도식화 하면 다음과 같다.
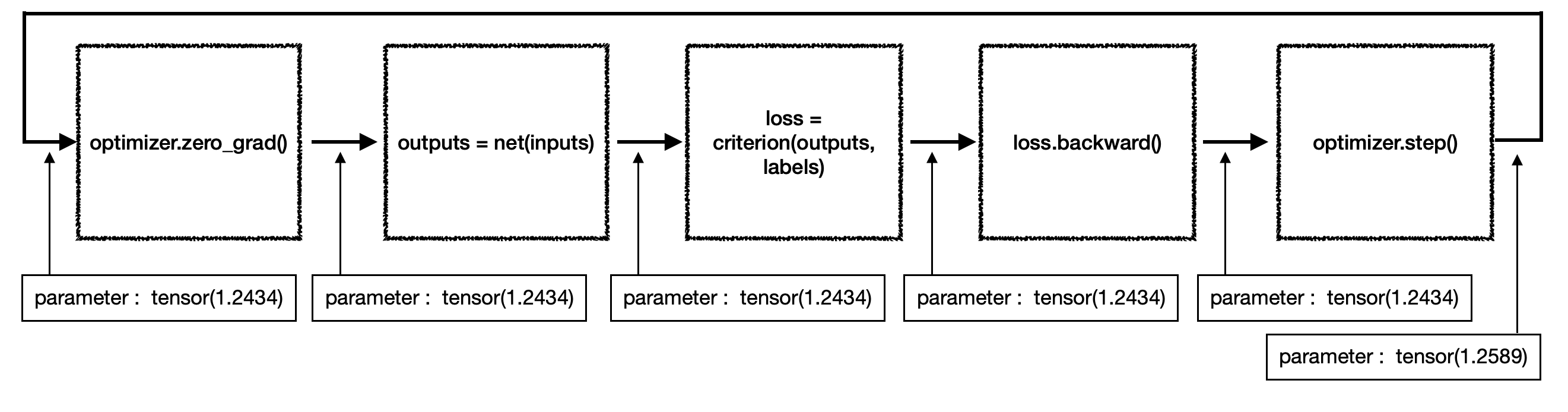
계속해서 유지되던 parameter가 optimizer.step()를 거치면서 값이 변화한다는 것을 알 수 있다. 이 부분도 코드로 확인하면 보다 명확하므로 대표적인 optimizer인 torch.optim.SGD()의 소스 코드를 가지고 왔다.
class SGD(Optimizer):
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
...
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
if weight_decay != 0:
...
if momentum != 0:
...
p.add_(d_p, alpha=-group['lr'])
return loss
weight_decay, momentum과 같이 계산에 필수적이지 않은 부분들은 생략했다. 위의 코드 중 이중 for 문의 안쪽 Iteration이 Module 내에서 Parameter(torch.Tensor()) 형태로 선언된 parameter들을 업데이트하는 코드라고 할 수 있다. 사실상 SGD에서 업데이트를 담당하는 부분은 다음 마지막 한 줄이다.
p.add_(d_p, alpha=-group['lr']) # parameter = parameter + (gradient * -lr)
여기서 add_()는 add()의 inplace 버전으로 p, 즉 현재의 parameter를 gradient d_p와 alpha 값으로 주어진 음의 learning rate -group['lr']를 곱한 값과 더한 값으로 대체하겠다는 것을 의미한다.