Thread
- update date : 2020.07.19
- 본 포스팅은 고려대학교 컴퓨터학과 유혁 교수님의 2020년 1학기 Operating system을 수강하고 이를 바탕으로 작성했습니다. 수업 내용 복습을 목적으로 작성하였기 때문에 내용 중 부족한 점이 있을 수 있습니다.
1. Multi Thread
쓰레드는 프로세스 내에서 작업을 처리하는 단위이다. 프로세스는 Protection Domain과 Execution Unit 이라는 두 가지 특성을 가진다고 했었는데 멀티 쓰레드가 가능해지면서 프로세스 내에 복수의 Execution Unit이 존재할 수 있게 되었다. 기본적으로 쓰레드는 단일 프로세스 내에서도 병렬화가 가능한 작업을 동시에 처리하면 더 빠르지 않을까 하는 아이디어를 가지고 있다. 정리하자면 프로세스가 CPU(코어)를 점유하는 기본 단위라면 쓰레드는 프로세스 내부의 실행 흐름 단위라고 할 수 있다.
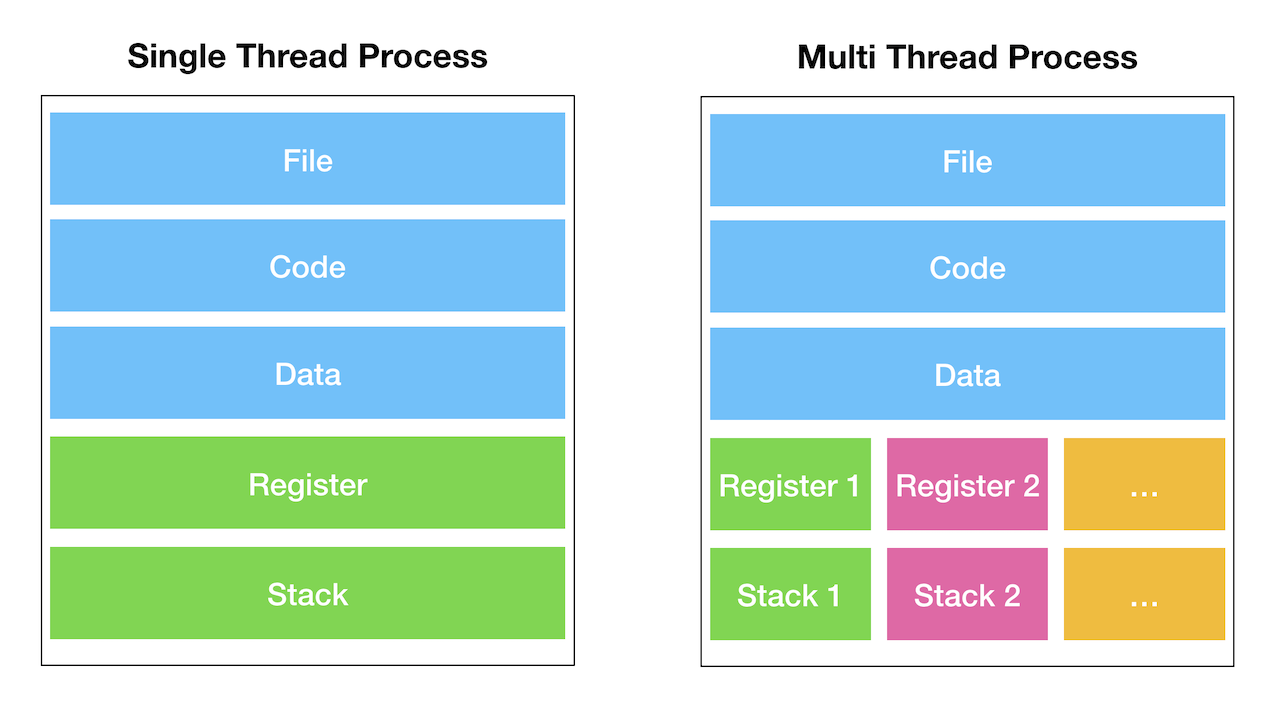
위의 그림은 단일 쓰레드를 갖는 프로세스와 멀티 쓰레드를 갖는 프로세스를 비교하고 있다. 왼쪽의 그림의 경우 쓰레드, 즉 실행 흐름이 하나이기 때문에 File, Code, Data, Register, Stack 모두 하나씩만 가지고 있다. 오른쪽의 멀티 쓰레드 프로세스 또한 File, Code, Data 영역은 하나씩 가지고 있지만 Register, Stack은 쓰레드마다 별도로 생성하는 것을 확인할 수 있다. 프로세스 내부의 공유 자원들은 최대한 공유하되, 코드를 실행하는데에 필요한 Registers, Stack 영역은 복수로 존재하는 것이다.
Pros & Cons
기본적으로 멀티 쓰레드는 컴퓨터의 Throughput을 높여준다. CPU에 복수의 코어가 존재한다면 하나의 프로세스 내에 존재하는 여러 쓰레드를 각각 다른 코어에 올려 동시에 처리할 수 있다. 이와 함께 오버헤드를 줄이고 처리량을 높이는 측면에서도 효율적이라고 할 수 있다. 구체적으로 멀티 쓰레드는 다음과 같은 장점을 가진다.
- 여러 쓰레드를 각각 다른 코어에서 동시에 실행할 수 있다(Scalability).
- 쓰레드 간 공유하고 있는 영역이 있으므로 Context Switch 비용이 줄어든다(Resource Sharing).
- 어떤 한 쓰레드가 block 되거나 시간이 오래 걸리게 되더라도 다른 쓰레드를 먼저 처리할 수 있어 interactive application에 효과적이다(Responsiveness).
하지만 멀티 쓰레드는 동기화 문제(Synchronization)를 해결해야 한다는 점에서 구현이 쉽지 않다. 프로세스는 Protect Domain으로 기능하며 다른 프로세스가 사용하는 메모리에 접근하여 쓰는 것이 기본적으로는 금지되어 있다. 하지만 Protect Domain 내에 복수의 실행 흐름(쓰레드)이 존재한다면 다른 작업을 수행하는 과정에서 필요한 Data 영역 등을 임의로 바꾸어버리는 문제가 발생할 수 있다. 동기화란 이러한 문제를 방지하고 프로세스 내부에서 쓰레드 간 공유하는 영역이 일관성 있게 유지되도록 하는 것을 말한다.
2. User Thread and Kernel Thread
쓰레드는 지원하는 주체에 따라 두 가지로 나누어 볼 수 있는데, 유저 쓰레드는 유저 어플리케이션에서 지원하는 쓰레드를 말하고 커널 쓰레드는 말 그대로 커널 레벨에서 지원하는 쓰레드를 말한다. 운영체제의 지원 여부에 따라 유저 쓰레드만 복수로 존재하는 경우도 있고, 유저와 커널 쓰레드 모두 복수로 존재하는 경우도 있다.
하나의 커널 쓰레드만 있다면 어플리케이션 레벨에서만 멀티 쓰레드를 지원하는 경우 여러 개의 유저 레벨 쓰레드가 하나의 커널 쓰레드에 물려 있는 구조를 띄게 된다. 따라서 어떤 한 쓰레드가 커널 쓰레드를 점유하고 있으면 프로세스의 다른 쓰레드들은 커널 쓰레드를 사용하지 못하고 block 된다. 즉 어플리케이션 레벨에서는 복수의 실행 흐름이 존재할지라도 커널의 관점에서는 하나의 프로세스일 뿐이므로 복수의 코어가 존재하는 멀티 프로세서 환경에서도 전체 프로세스가 하나의 프로세서 밖에 사용하지 못한다. 이러한 경우 위에서 언급한 동기화 문제가 발생하지 않는다.
커널에서 멀티 쓰레드를 지원한다면 프로세스의 어떤 한 쓰레드가 system call을 호출하여 하나의 커널 쓰레드를 점유하고 있다 하더라도 사용할 수 있는 다른 커널 쓰레드가 있으므로 다른 쓰레드를 처리할 수 있게 된다. 만약 멀티 프로세서 환경이라면 여러 개의 쓰레드를 각각의 코어에 할당하여 병렬적인 처리가 가능하다.
Mapping
유저 레벨과 커널 레벨에 따라 각각 쓰레드가 존재한다면 각 레벨의 쓰레드를 어떻게 매핑할 것인가라는 문제가 생긴다. 대표적으로는 Many to One, One to One, Many to Many가 있다.
1) Many to One
유저 쓰레드는 복수로 존재하지만 커널 쓰레드는 하나만 존재하는 경우를 말한다. 위에서 언급한 것과 마찬가지로 하나의 유저 쓰레드가 커널 쓰레드를 사용한다면 다른 유저 쓰레드들은 대기해야 한다는 점에서 진정한 의미의 병렬 처리는 지원하지 못한다고 할 수 있다.
2) One ot One
유저 쓰레드와 커널 쓰레드 모두 복수로 존재하는 상황에서 유저 쓰레드의 갯수만큼 커널 쓰레드를 생성하여 1:1로 매핑하는 방법이다. 이 경우 쓰레드 간 독립적으로 커널에 접근할 수 있으므로 하나의 프로세스가 쓰레드 갯수만큼 코어를 할당받아 병렬적으로 처리하는 것이 가능하다. 하지만 유저 쓰레드를 많이 생성하면 생성할수록 프로세스에 할당되는 CPU 자원이 많아진다는 점에서 도덕적 해이가 발생할 수 있다. 쉽게 말해 한 프로세스가 무한한 쓰레드를 생성한다면 전체 CPU 자원을 점유하는 것도 가능하다는 것이다.
3) Many to Many
Many to Many는 이러한 도덕적 해이 문제를 해결하기 위한 방법이라고 할 수 있다. 커널 쓰레드를 적절한 수만 생성하여 관리하고 복수의 유저 쓰레드를 스케쥴링하여 커널 쓰레드에 할당하여 하나의 프로세스가 일정 수준 이상의 CPU 자원을 차지하는 것을 방지하게 된다.