What is Process
- update date : 2020.05.25
- 본 포스팅은 고려대학교 컴퓨터학과 유혁 교수님의 2020년 1학기 Operating system을 수강하고 이를 바탕으로 작성했습니다. 수업 내용 복습을 목적으로 작성하였기 때문에 내용 중 부족한 점이 있을 수 있습니다.
1. Program and Process
- Process is a program in execution
책 Operating System Concepts의 표현 중 프로세스와 프로그램의 관계 혹은 차이를 설명하는 좋은 표현이 있어 가지고 왔다. 한마디로 프로세스는 실행 중인 상태의 프로그램이라는 것인데 이것의 의미는 아래 그림을 통해 보면 보다 명확하게 알 수 있다.
compile -> linking -> loading
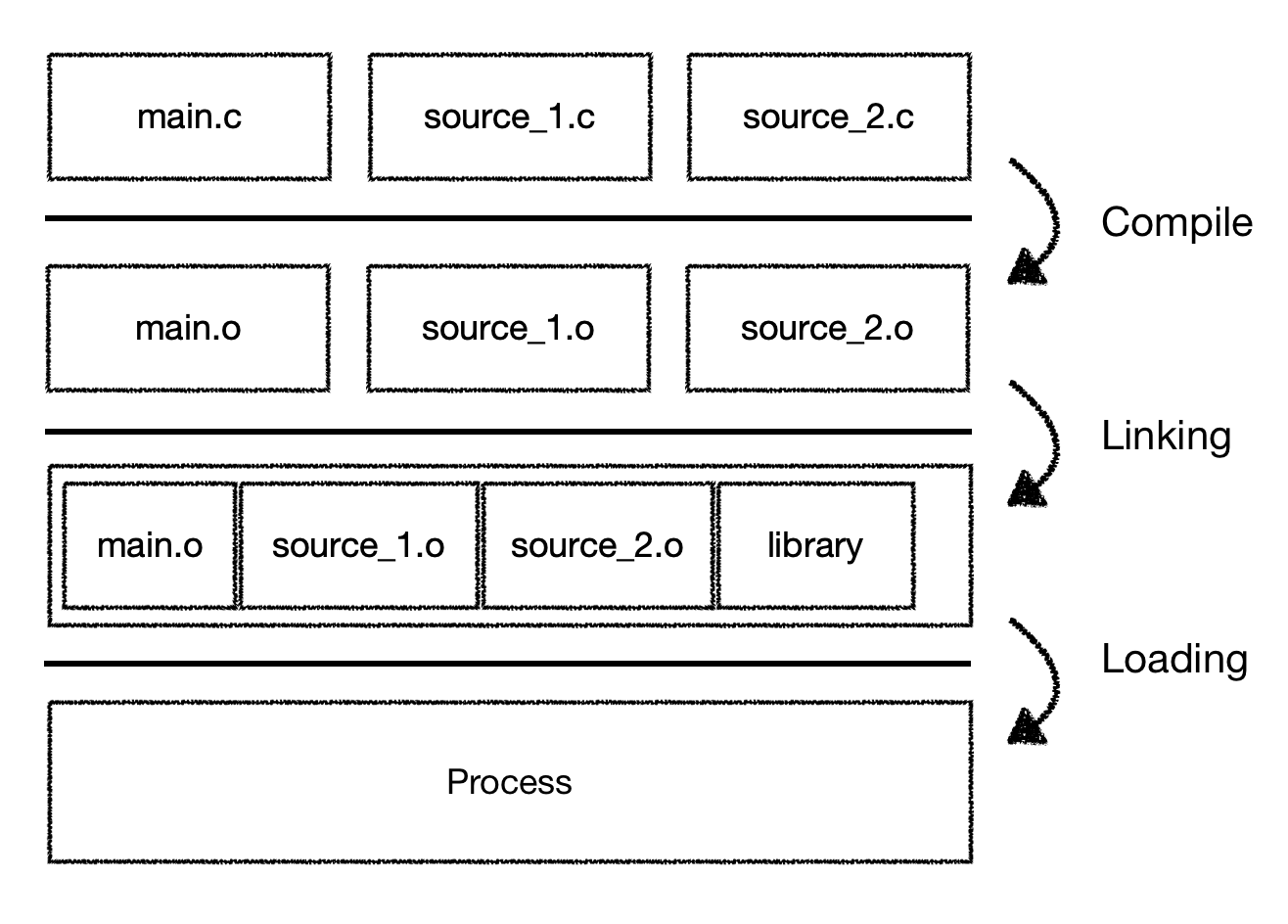
우리가 어떤 코드를 작성하면 일반적으로 compile, linking, loading의 세 단계를 거쳐 컴퓨터의 메모리에 올라가 CPU가 처리하게 된다. C++, python 등 프로그래밍 언어의 문법에 따라 코드를 작성하게 되지만 CPU의 관점에서 볼 때 소스코드는 확장자만 다를 뿐 이해할 수 없는 텍스트일 뿐이다. 따라서 이를 컴퓨터가 이해할 수 있는 기계어로 바꾸어주는 Compile이 필요하다. Compile의 결과물을 Object file이라고 한다.
- complie: One Source Code, One Object File
compile이 되었다고 해서 곧바로 실행할 수 있는 것은 아닌데 왜냐하면 어떤 소스코드를 실행하기 위해서는 소스코드가 사용하는 다른 소스코드 또는 라이브러리가 필요하기 때문이다(C의 #include <stdio.h>가 대표적이다). 이를 위해 다른 파일 및 라이브러리와 연결하는 작업이 필요하며 이것이 Linking 이다.
- Linking: Many Object Files, One Executable File
Linking 과정을 거치게 되면 비로소 CPU가 처리할 수 있는 상태가 되는데 이러한 점에서 이를 Executable File이라고 한다. Executable File은 특정 OS에서 수행될 수 있는 파일로( =OS마다 다른 형식을 갖는다), 실행에 필요한 정보들을 하나로 모아 만든 덩어리라고 할 수 있다.
- Loading: Executable File to Process
그런데 Executable File은 실행이 가능한 상태이지 실행 중인 상태가 아니다. 이를 실행 중인 상태, 즉 CPU가 언제든지 읽을 수 있는 상태로 만들기 위해서는 저장장치에 있는 executable을 Memory에 올리는 과정이 필요하다. 물론 executable file이 그대로 올라가는 것이 아니고 process로 만들어주는 작업이 함께 이뤄지는데 이것을 Loading 이라고 한다. Loading이 완료되어 Memory에 완전히 올라간 Executable file을 Process라고 한다.
Program은 저장장치에 저장된 instruction의 집합 정도로 정의된다. Operating System Concepts에서는 Program = Executable file이라고 하지만 Stack overflow에서는 Program을 사람이 읽을 수 있는 소스코드로 보고 있다.
On Storage or On Memory
Program의 정의에 모호성이 있다고 하더라도 Process와 Program의 가장 큰 차이는 저장된 위치에 있다. 즉 HDD 또는 SSD와 같은 저장장치에 저장되어 있으면 Program이고 Memory에 올라가 있으면 Process라는 것이다. 이러한 점에서 Program은 passive entity이고 Process는 active entity라고도 표현한다.
2. Program to Process
프로세스는 Executable File에 담긴 정보를 이용하여 만들게 되는데 이때 Executable File의 각 영역은 해체되어 프로세스의 메모리 구조에 따라 재구성된다. 그리고 프로세스를 실행하는데에 필요한 환경이 구축되는데 이 모든 과정이 Runtime System(RTS)에 의해 이루어진다.
Runtime System
일반적으로 Runtime이란 특정 프로그램의 실행 중인 상태 또는 실행 중인 동작을 의미한다. Runtime system은 Runtime이 이뤄질 수 있도록, 즉 프로그램의 실행이 이뤄질 수 있도록 해주는 virtual machine 또는 Engine이라고 할 수 있다. Runtime System의 가장 기본적인 역할은 Executable model을 만드는 것, 다시말해 Executable File을 이용하여 실행하기에 충분한 상태로 만들어주는 것이다. 환경 변수를 설정하거나 C언어에서 main 함수를 호출하는 것, Dynamic Linking을 사용하는 경우 라이브러리에 접근하는 것 또한 모두 Runtime System에 의해 이뤄진다.
참고로 Runtime Error는 프로그램의 실행 도중에 발생하는 Error를 말한다. 언어에 따라 사용하는 Runtime System이 다르기 때문에 Runtime Error 또한 언어에 따라 그 종류나 특성이 다르다. 대표적으로 C와 같은 언어들은 Type Checking이 Compile 단에서 이뤄지므로 Type Error가 Compile Error이지만 Python의 경우 Runtime 과정에서 Type Checking이 이뤄지기 때문에 Type이 맞지 않으면 Runtime Error로 출력된다. 이와 관련해서는 Functional Programming and Static Type Checking With Ocaml 포스팅에서 보다 구체적으로 정리해 두었다.
Memory layout of Process
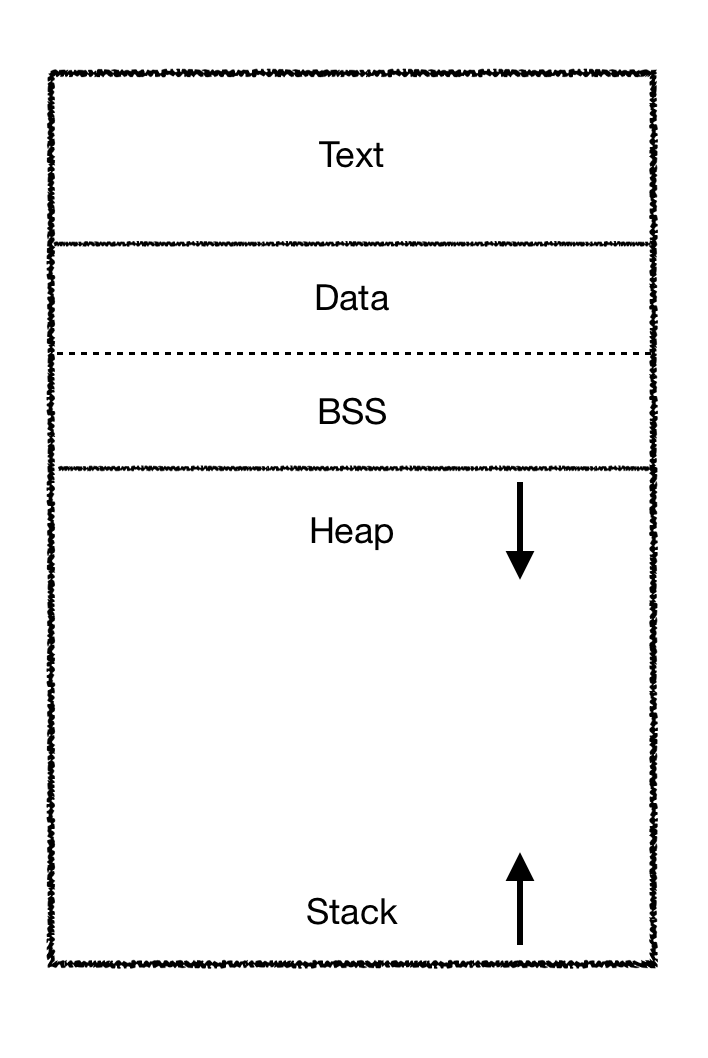
Memory에 올라간 프로세스는 위의 그림과 같이 크게 Text, Data, BSS, Heap, Stack 의 5가지 영역으로 구성되어 있다. Data와 BSS는 모두 전역 변수를 저장하는 공간이기 때문에 Data로 합쳐 4가지 영역으로 표현하는 것이 보다 일반적이다. 구체적으로 각각의 영역에는 다음과 같은 데이터들이 저장되어 있다.
| Text | 실행 코드 |
| Data | Global variables 중 초기값이 있는 경우 |
| BSS(Data) | Global variables 중 초기값이 없는 경우 |
| Heap | 프로그램 실행 도중 이뤄지는 동적 할당 데이터 |
| Stack | local variables, function parameters 등 함수의 실행 과정에서 필요한 데이터 |
Text, Data 영역의 경우 프로세스가 생성되는 순간 정해져 runtime 동안에 바뀌지 않는다. 반면 Heap과 Stack 영역의 경우 runtime 과정에서 끊임없이 할당과 해제가 반복된다. 이때 문제는 프로그램이 Heap과 Stack을 얼마나 많이 사용할지에 대해서 수행 전에는 알 수 없다는 것이다. 따라서 효율적으로 메모리를 사용하기 위해 다른 영역처럼 고정적인 크기를 할당하는 것이 아니라, 시작 지점을 남은 영역의 양 끝으로 하여 채워가도록 하고 있다. 물론 OS는 한 영역이 다른 영역을 침범하지 않도록 관리해야 한다.
Dynamic linking & Static linking
위에서 언급한대로 Linking 이란 여러 Objective File 및 라이브러리를 연결하여 실행이 가능하도록 만드는 것이다. 이때 프로그래밍 언어에 따라 항상 사용되는 가본적인 라이브러리가 있는데 대표적인 것이 C 표준 라이브러리(C standard library) libc 이다. linux등과 같은 운영체제를 포함하여 C 언어로 작성된 프로그램을 실행하면 libc는 항상 사용하게 되며 이때 매번 libc 전체 내용을 각각의 executable file에 포함시키는 것은 비효율적이다. 이러한 중복을 줄이기 위해 libc와 같이 자주 사용되는 라이브러리는 미리 Memory(Runtime System)에 올려두고, Executable file에는 언제 어떤 라이브러리가 필요한지만 명시하여 Runtime 도중에 동적으로 접근하는 방법을 생각해 볼 수 있다. 이러한 방법을 Dynamic Linking 이라고 한다. 반대로 처음 말한 것과 같이 executable file에 사용하는 라이브러리를 모두 포함하는 것을 Static Linking 이라고 한다.
3. Two characteristics of the process
지금까지는 프로세스가 만들어지는 과정에 관한 이야기였다면, 이제 프로세스 자체가 가지는 특성에 대해 다뤄보고자 한다. 프로세스는 Execution Unit, Protection Domain의 두 가지 특성을 가진다.
Protection Domain
프로세스는 다른 프로세스를 침범할 수 없다. 각각의 프로세스는 Memory 내에 특정 공간을 점유하며 프로세스가 실행되는 과정에서 다른 프로세스가 점유하고 있는 영역에는 접근하지 못한다는 것이다. 참고로 이러한 Protection Damain을 깨는 것이 해킹의 기본 아이디어이다.
Execution Unit
Execuction Unit이라는 것은 프로세스(CPU)를 사용하는 기본 단위라는 것을 의미한다. Multi Programming 또는 Time Sharing 환경에서는 복수의 task가 concurrent 하게 수행되는데 이때 CPU를 점유하는 기본단위가 프로세스라는 것이다. 이러한 점에서 프로세스는 CPU Scheduling의 기본 단위가 된다.
4. Process state
모든 프로세스는 New, Ready, Waiting, Running, Terminated 의 5가지 중 하나의 상태를 가지고 있다.
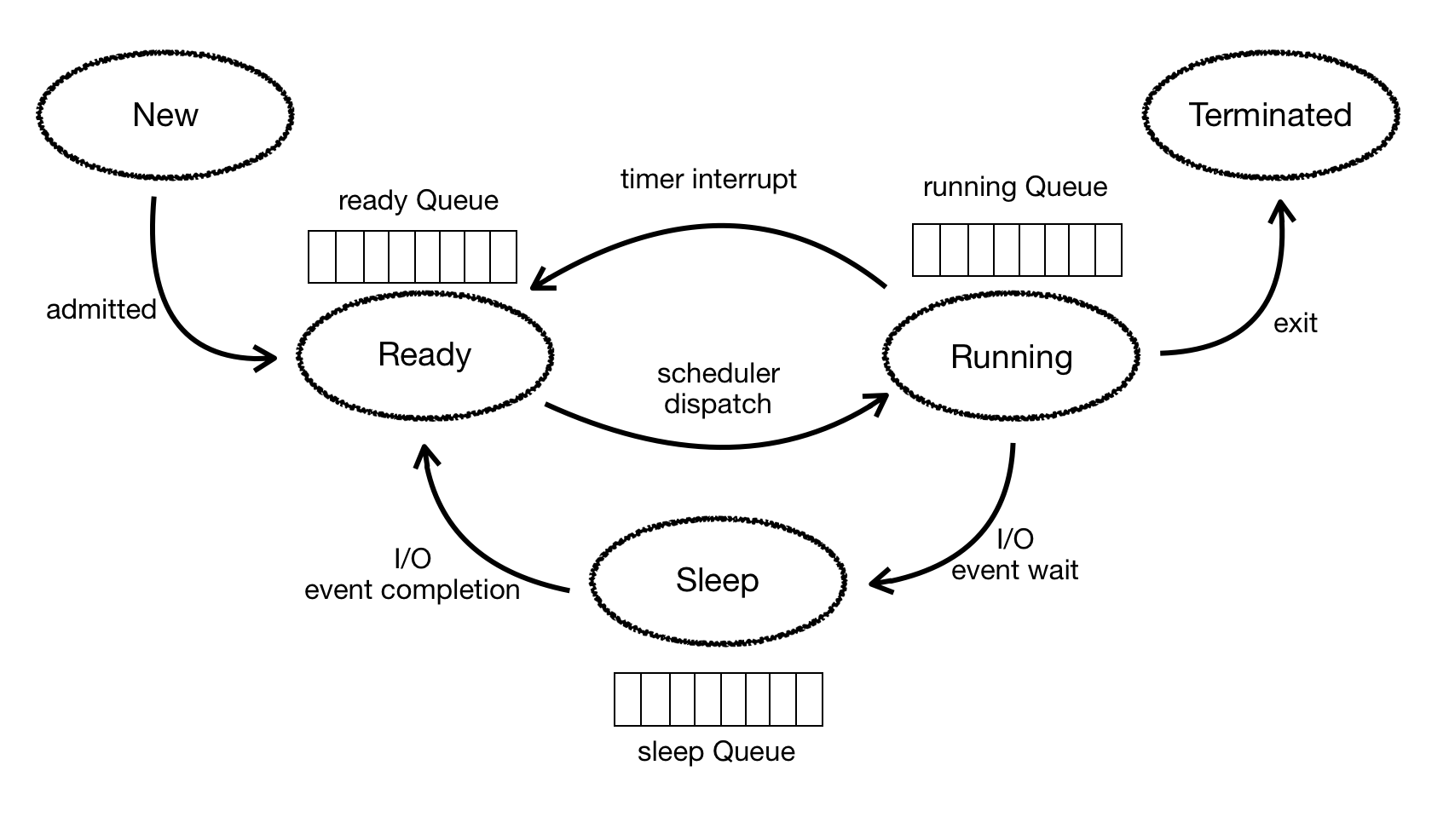
이때 각각의 state는 Queue를 가지고 있어 이를 사용하여 다음에 어떤 프로세스를 수행할지 결정한다.
Context Switch
프로세스가 실행되기 위해서는 register에 해당 프로세스의 실행을 위해 필요한 데이터들이 올라가야 한다. 이때 기존에 실행 중인 프로세스를 이어서 처리하기 위해서는 이전의 register 정보를 저장하는 과정도 필요하다. 이와 같이 기존 프로세스와 관련된 정보를 저장하고 새로운 프로세스와 관련된 정보를 CPU register에 올리는 과정을 Context Switching 이라고 한다. 즉 여기서 말하는 Context란 프로세스가 실행되는 문맥을 말하는 것이다.
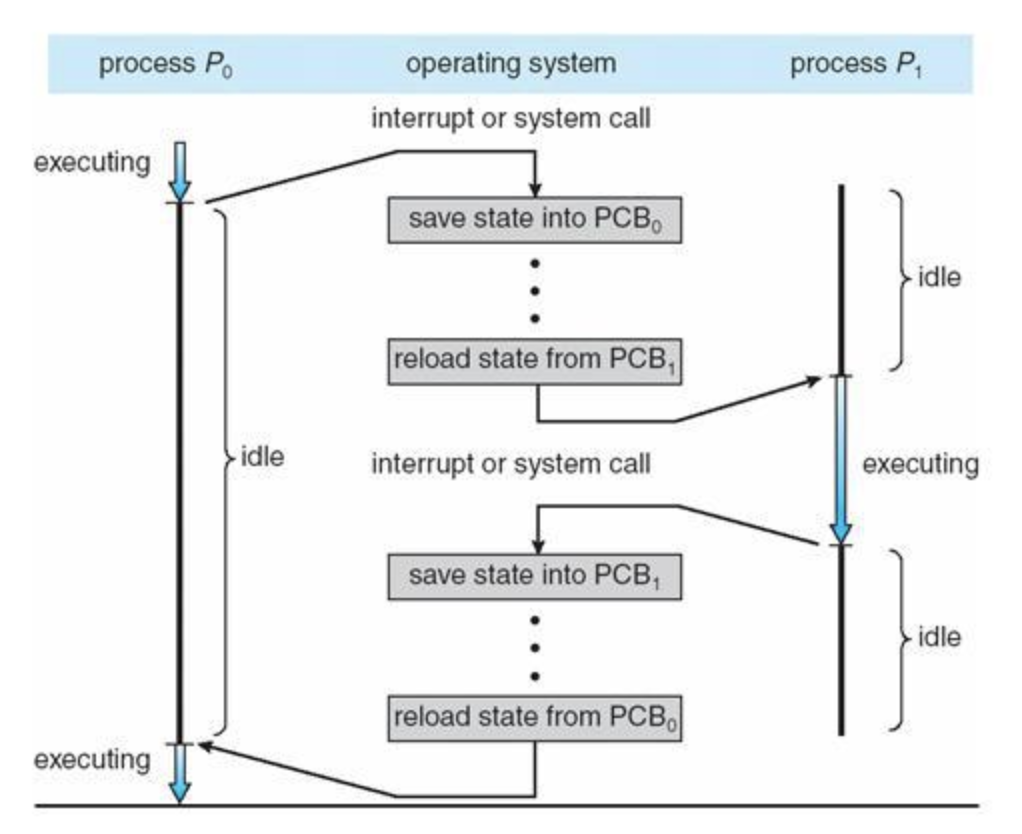
구체적으로 Context Switching은 Time Quantum(Time sharing)이 만료되거나 I/O 호출이 있는 경우에 이뤄진다. 정확한 Register 값이 준비되지 못하면 프로세스를 정상적으로 수행할 수 없으므로, Context Switching이 완료되기 전까지는 프로세스를 처리할 수 없으며 이러한 점에서 필연적으로 Context Switching은 오버헤드를 발생시킨다.
위의 Context Switch를 보면 PCB라는 표현이 나온다. Process Control Block의 준말인데 차후에 프로세스를 다시 처리하기 위해 필요한 register 값 등과 같은 데이터를 저장하는 자료구조라고 할 수 있다. PCB에는 현재 프로세스의 상태, program counter, register 값 등이 저장되어 있으며 각각의 프로세스는 하나의 PCB를 가진다(One process One PCB). PCB는 Process Memory 공간에 저장되지 않고 Kernel에 저장되는데 이는 Process Memory의 주소를 모르는 상태에서 PCB를 찾지 못하는 문제를 방지하기 위함이다.
System call and Context Switch
System call은 다른 프로세스로 전환되는 것이 아니라 동일한 프로세스의 실행 모드가 User Mode에서 Kernel Mode에서 변경되는 것이다. 따라서 Context Switch가 이뤄지지 않는다.
I/O and Context Switch
반면 I/O 의 경우에는 Kernel Mode에서 User Mode로 돌아갈 때 I/O를 호출한 기존 프로세스가 아닌 다음 프로세스로 돌아가게 되므로, Context Switch가 발생한다. 이때 기존 프로세스는 다음에 수행할 수 있도록 Running Queue 또는 Sleep Queue에 추가하게 되며 이러한 작업을 Queuing이라고 한다.
Processor Architecture and Context Switch
Context Switch는 Register의 값들을 저장하고 로드하는 작업이기 때문에 register의 특성에 영향을 받는다. 이러한 register 특성은 CISC, RISC 와 같은 Processor Architecture에 따라 나누어 볼 수 있다.
CISC의 경우 ISA가 다양하고 이에 따라 회로의 구성도 복잡하다. 이러한 특성 때문에 상대적으로 요구되는 register의 크기가 작아 Context Switch에 의한 오버헤드가 작다. 반면 RISC의 경우 ISA가 단순하고 회로가 단순한 반면 Context Switch에 따른 오버헤드가 큰 편이었고 이로 인해 빠른 클럭 속도의 장점이 상쇄되는 문제가 있었다. 이는 CPU 발전 초기 RISC가 널리 사용되지 못한 이유이기도 했다. 최근에는 회로가 단순해 공간 확보가 유리한 장점을 이용하여 Register Window 등 새로운 기법을 적용해 Context Switch로 인한 오버헤드가 크게 줄어들었다고 한다.
Process Creation
일반적으로 프로세스는 처음부터 끝까지 새롭게 만들지 않고 기존의 프로세스를 복제하여 기본 틀을 우선 구성한 후 만들고자 하는 program의 내용으로 채워넣어 생성한다. 이렇게 하는 이유는 효율성을 높이기 위해서인데 프로세스는 PCB를 비롯하여 수많은 자료구조로 구성되어 있고 이를 처음부터 만드는 것은 비효율적이기 때문이다.
이러한 작업은 모두 system call에 의해 이뤄진다. 기존 프로세스를 복제하는 system call이 fork()이고 이렇게 복제된 프로세스를 새로운 program으로 채우는 system call은 exec()이다.
복잡해 보이는 과정이지만 실제로는 매우 빈번하게 사용된다. 대표적인 것이 terminal에서 ls 명령어를 입력하는 경우이다. 현재 디렉토리 내에 어떤 파일과 디렉토리가 있는지 확인할 때 사용하는 명령어 ls를 입력하면 다음과 같은 과정을 거쳐 결과가 보여지게 된다.
$ ls를 입력한다.- 명령어를 받은 shell이
fork()를 호출하여 스스로를 복제한다. exec()을 호출하여 새롭게 복제한 프로세스를bin/ls로 채워넣는다.- 프로세스의 실행 결과를 받아 보여준다.
Linux를 비롯하여 UNIX계열에서는 사실상 모든 user process가 이러한 방식으로 만들어진다. 이때 모든 user process의 시초가 되는 프로세스가 init 이다.
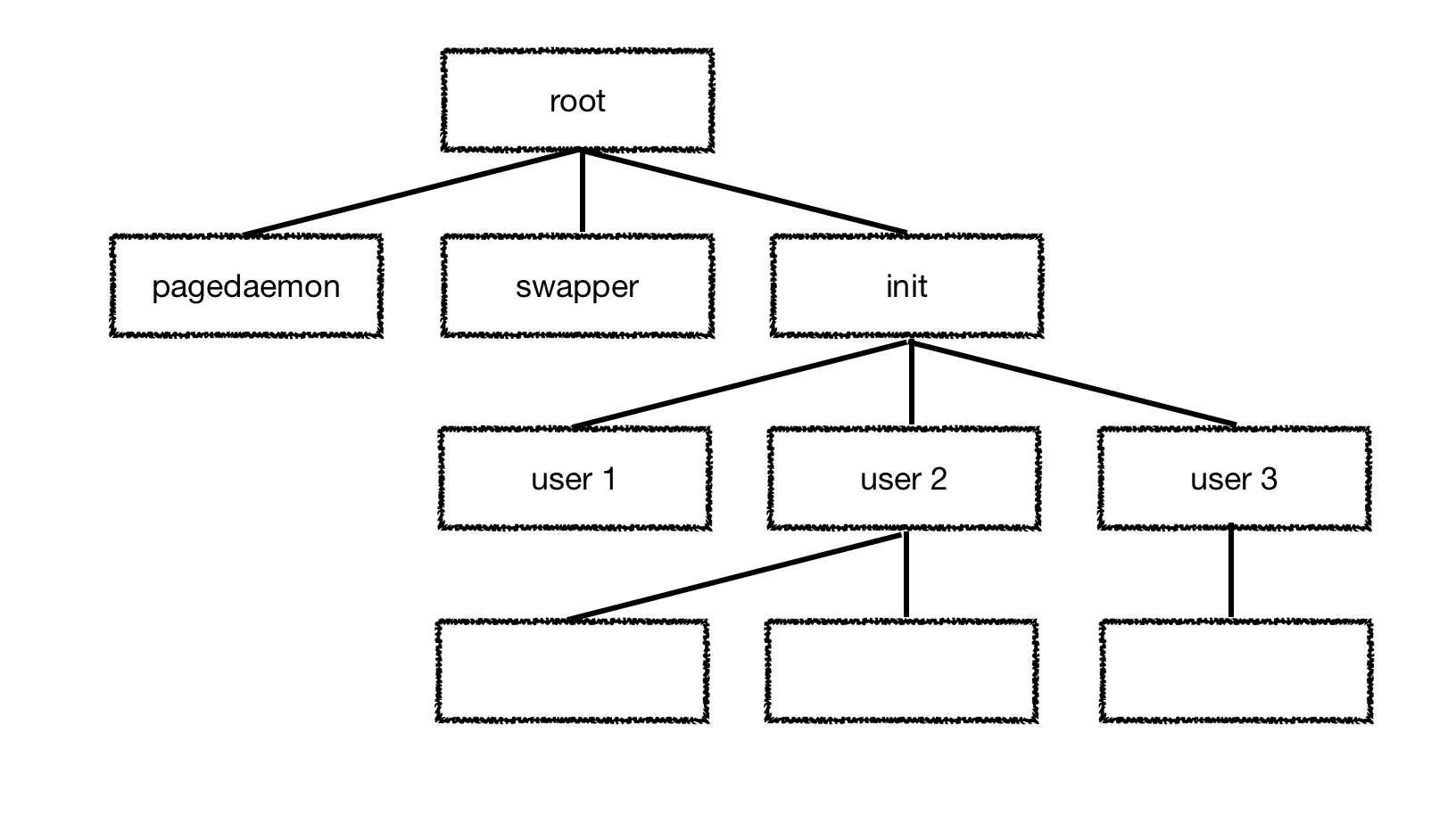
Process Termination
프로세스를 새로 만들 때와 마찬가지로 완료된 프로세스를 종료시키는 과정 또한 system call을 통해 이뤄진다. Runtiem System이 system call exit()을 호출하게 되면 해당 프로세스의 결과가 parent process로 전달되며, 프로세스에 할당되었던 Memory 영역이 해제된다. 만약 어떠한 이유로 exit()이 호출되지 않는 경우 강제로 프로세스를 죽일 수도 있다. 이때 사용되는 것은 abort()이다.