Transport Layer Protocols, TCP & UDP
- update date : 2020.07.04
- 본 포스팅은 고려대학교 컴퓨터학과 김효곤 교수님의 2020년 1학기 Internet Protocol을 수강하고 이를 바탕으로 작성했습니다. 수업 내용 복습을 목적으로 작성하였기 때문에 내용 중 부족한 점이 있을 수 있습니다.
1. Introduction
Transport Layer에서 가장 많이 사용되는 프로토콜인 TCP는 IP를 사용하는 패킷 중 90% 이상을 차지하며 가장 보편적인 전송 수단으로 꼽힌다. HTTP를 비롯하여 웹 서비스의 기본적인 Application들이 TCP를 사용하여 데이터를 주고 받으며 IP 위에서 동작하는 가장 대표적인 프로토콜이기 때문에 TCP/IP로 묶에 부르기도 한다.
UDP는 Transport Layer에서 TCP에 이어 두 번째로 많이 사용되는 프로토콜이다. 두 번째라는 말이 무색하게 전체 패킷의 약 5%만이 UDP를 사용한다고 알려져 있지만 UDP는 TCP와 비교해 고유의 장점을 가지고 있고 UDP로만 처리되어야 하는 Application이 있다는 점에서 중요하다.
2. TCP, Transmission Control Protocol
TCP는 안정적인 전송을 제 1 목표로 한다. 이를 위해 TCP는 아래와 같이 다양한 기능을 제공한다.
- Make Connection
- Guarantee of delivery
- Retransmission
- In-order Delivery
- Flow Control
- Congestion Control
- Fragmentation
- PMTU Discovery
- Full Duplex
TCP Packet Format and Fields
다양한 기능을 제공하는 만큼 TCP는 비교적 큰 header를 가지고 있는데 고정 20Byte에서 optional field에 따라 최대 60Byte까지 늘어날 수도 있다. 대표적인 header field는 다음과 같다.
a. Sequence Number
보내고자 하는 데이터의 byte 단위 순서를 의미하며, payload의 첫 번째 byte의 sequence number가 들어간다.
b. Acknowledge Number
수신자 측에서 지금까지 받은 데이터의 마지막 byte의 sequence number에 1을 더하여 전송하며, 다음에 받을 것으로 기대되는 데이터의 sequence number를 의미한다.
c. Window size
수신자가 가지고 있는 receiver socket buffer에 남아있는 공간의 크기를 의미한다. receiver socket buffer는 수신하였지만 Application layer으로 전달되지 않아 아직 Transport layer에 남아 있는 데이터가 임시적으로 저장되는 공간이다.
d. Maximum Segment Size(option)
한 패킷에 담을 수 있는 data 영역의 크기를 의미한다. 일반적으로 MTU - 20 - 20 으로 계산하게 되는데 IP header의 크기와 TCP header의 최소 크기를 뺀 값이다. MSS에 대한 언급이 없는 경우에는 IP Datagram의 최소 크기인 576Byte에 40을 뺀 값인 536Btype를 MSS 값으로 상정한다. TCP는 Full Duplex이므로 양 방향으로 전송이 이뤄지는데 이 때 두 방향 모두 MSS의 크기는 동일해야 한다.
e. Window Scale Option(option)
window size field의 크기는 16비트이므로 표현하고자 하는 window size가 \(2^{16}-1\)보다 큰 경우에는 window sieze field 만으로는 부족하다. Window Scale Option field는 그 크기만큼 window size field를 left shift하여 window size를 인식하도록 해 보다 큰 window size를 표현하기 위해 사용한다.
f. Selective Ack Permitted(option)
현재 수신자가 가지고 있는 부분이 무엇인지 알려준다. 구체적으로 가지고 있는 데이터의 seqeunce number의 시작과 끝을 알려주어 부족한 부분이 어디인지 발신자가 알 수 있게 한다.
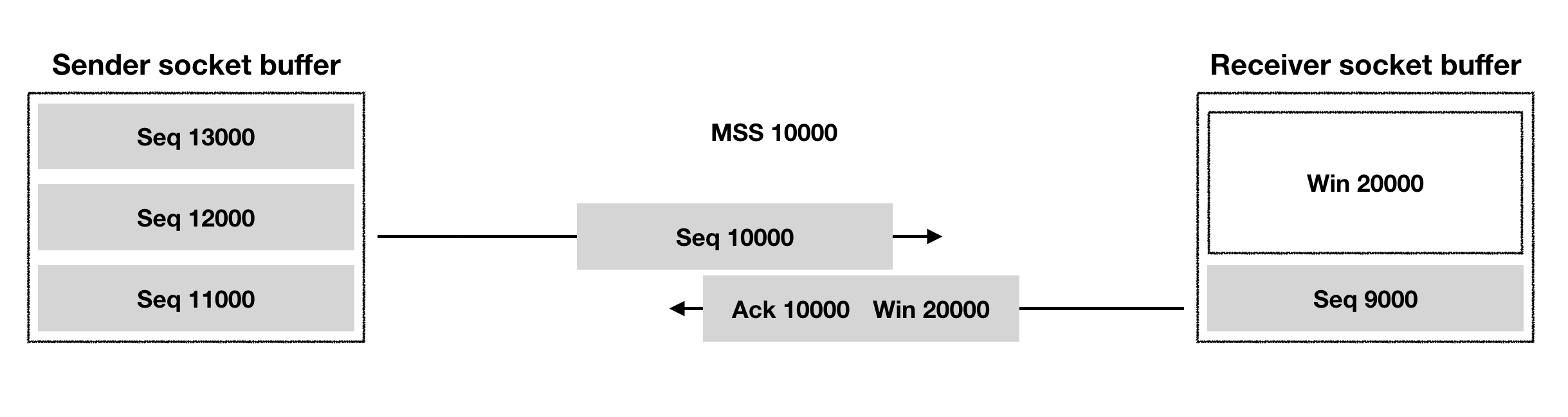
3. TCP Connection Management
TCP는 Connection Oriented Service로 데이터를 주고받기에 앞서 수신자와 발신자 간에 connection 형성이 이뤄지게 된다. connection을 형성하는 과정은 패킷을 주고 받을 때 공통적으로 사용할 규약을 확정하는 것이라고 할 수 있는데 이를 Synchronization이라고 한다. TCP의 Synchronization 대상은 아래 세 숫자이다.
- Initial Sequence Number
- Window Size
- Maximum Segment Size
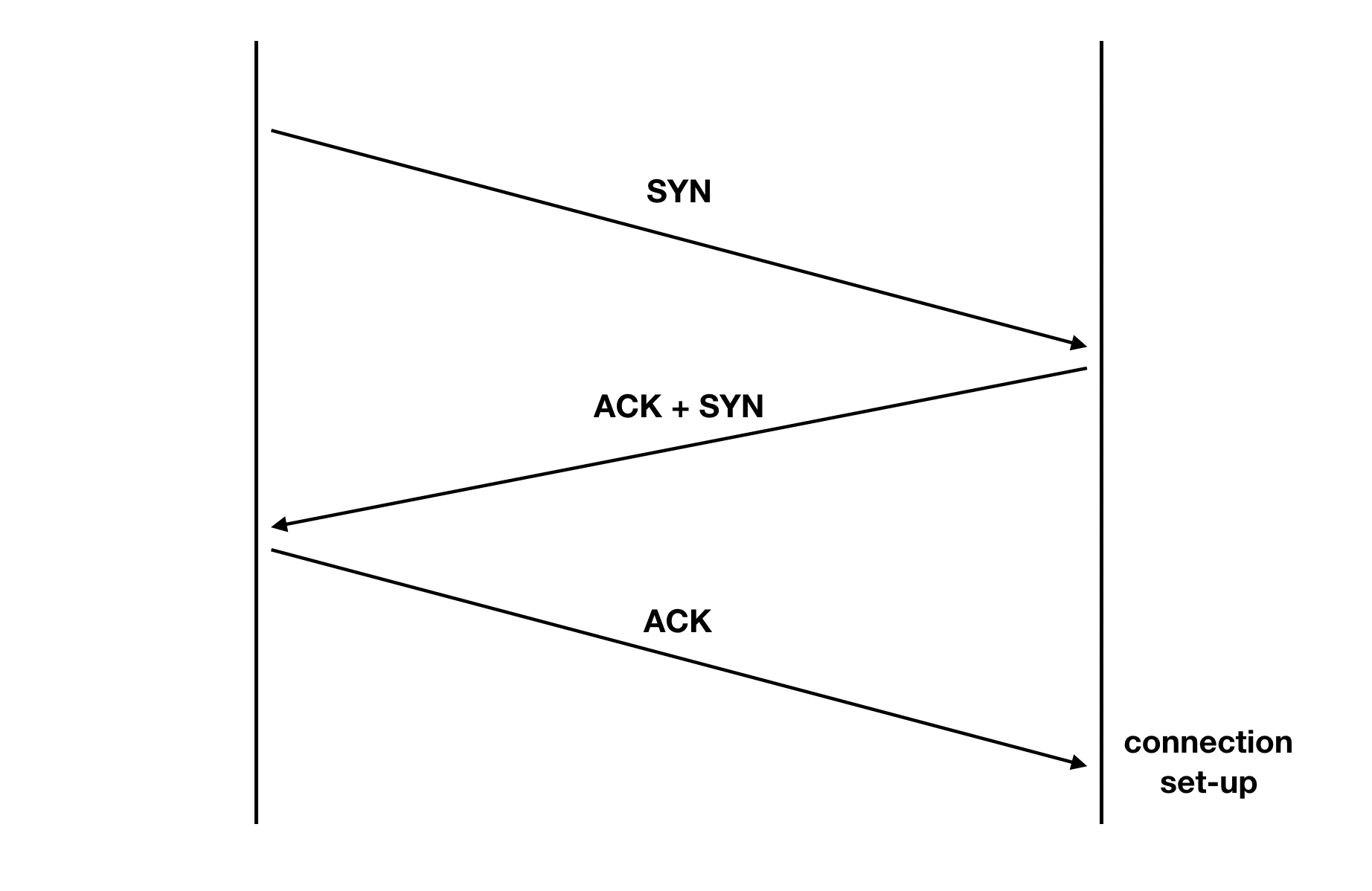
이때 Initial Sequence Number는 0이 아닌 random number로 채워지게 되며 MSS는 양방향 채널 중 작은 것을 사용하게 된다. 이러한 값들은 connection 생성과 관련된 데이터를 전송할 때 사용되는 SYN packet에 들어있다. SYN packet을 받은 수신자는 받았다는 것을 알라는 ACK 값을 자신의 SYN pakcet에 함께 포함하여 보낸다. 마지막으로 최소 발신자가 SYN + ACK packet에 대한 ACK를 보내면 connection이 형성된다. 3개의 패킷을 주고받게 되므로 3-way handshake라고 한다.
connection을 끊을 때에도 TCP는 수신자와 발신자 간에 확인하는 작업이 필요하다. 이때에는 FIN, ACK 패킷을 각각 보내므로 4개의 패킷을 사용하며 이러한 점에서 4-way handshake라고 한다.
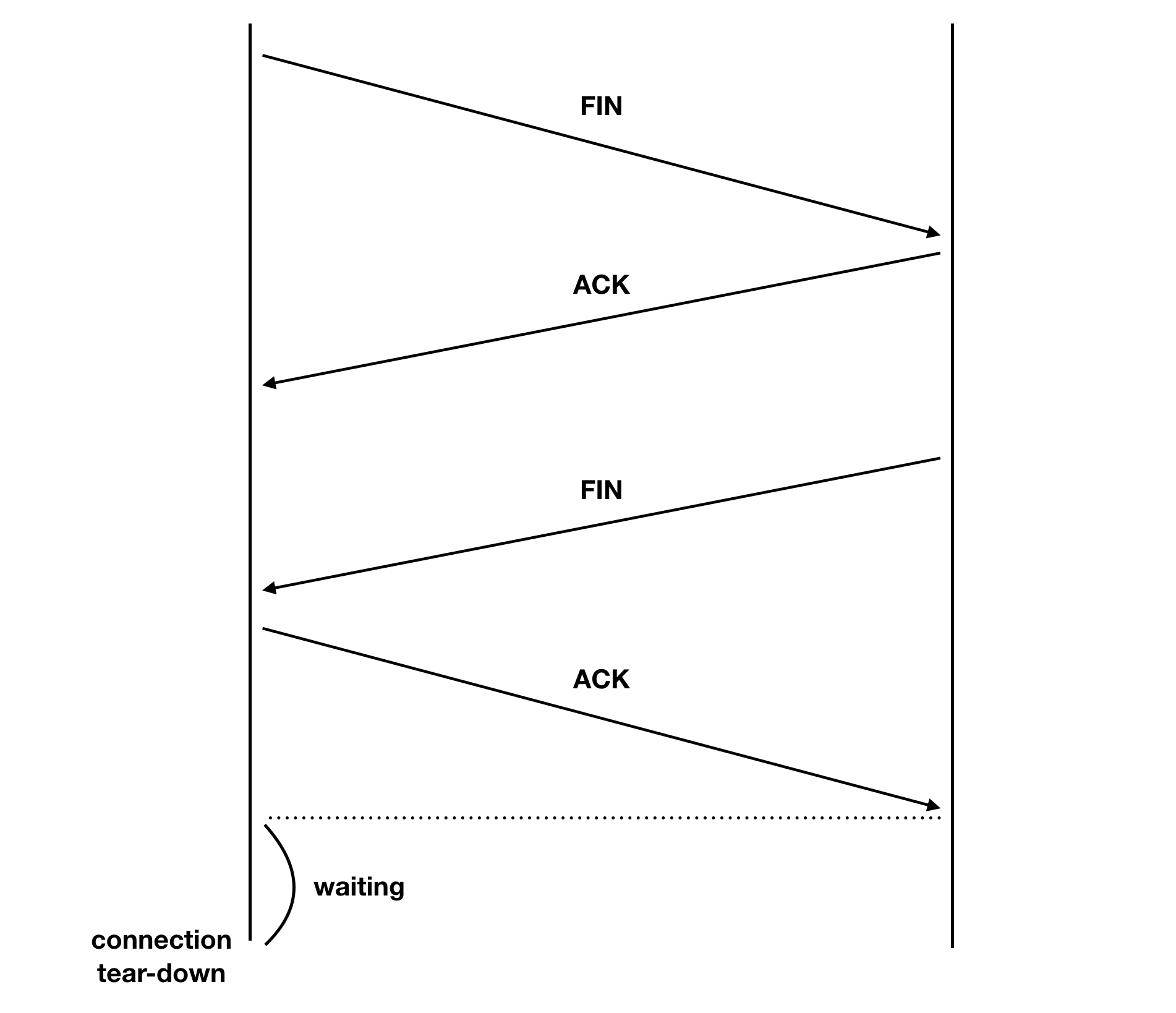
connection을 종료할 때에는 바로 종료하지 않고 위의 그림과 같이 2분 정도 connection을 유지하게 된다.
이와같이 하는 이유는 두 가지인데 우선 첫 번째는 마지막 ACK를 수신자가 받지 못하는 경우 다시 보내기 위해서이다. 두 번째 이유는 TCP connection의 naming과 관련있다. TCP connection은 <Receiver IP, Receiver Port, Sencder IP, Sender Port>로 이름이 붙여지게 된다. 이때 동일한 이름을 가진 connection이 종료 후 곧바로 다시 생성되는 경우를 생각해보자. 이름이 동일하므로 새롭게 만들어진 connection을 기존 connection으로 인식할 수 있다. 이렇게 되면 Synchronization이 제대로 수행되지 못하게 된다. 문제는 수신자와 발신자의 IP, Port만으로 이름이 결정되기 때문에 이러한 경우가 빈번하게 발생한다는 점이다. 웹 브라우저를 껐다가 곧바로 다시 실행하는 상황이 대표적이다. 이러한 문제를 피하기 위해 기존 connection을 잠시 동안 살려두는 것이다.
4. TCP Error Control
Receiver Side Error Control
수신자는 지금까지 받은 패킷의 마지막 Sequence Number에 1을 더한 Sequence Number의 패킷이 들어오기를 기대한다. 그러나 네트워크 환경에 따라 이후에 전송된 패킷이 더 빠르게 도착할 수도 있고, 중간에 패킷이 소멸될 수도 있다. 이에 대처하기 위해 수신자 측에서는 기대하는 Sequence Number E와 실제 들어온 Sequnce Nunber S를 비교하고 그에 맞게 대응한다.
E = S
기대에 맞는 Sequnce Number를 가진 패킷이 들어온 상황이다. 따라서 정상적으로 Receiver Socket Buffer에 수신된 데이터가 저장된다.
E > S
기대보다 작은 Sequence Number의 패킷이 들어왔다는 것은 이미 가진 데이터가 중복으로 수신되었다는 것을 의미한다. 따라서 새로 수신된 패킷은 버려진다.
E < S
기대보다 큰 Sequence Number의 패킷이 들어왔다는 것은 중간에 손실이 생겼다는 것을 의미한다. TCP는 In-order Delivery를 지원하므로 이 경우 중간의 손실이 채워지기 전에는 Receiver Socket Buffer로 들어가지 못하고 임시적으로 Reordering Buffer에 저장된다. 그리고 중간의 손실을 채우기 위해 이전 Acknowledge Number를 그대로 다시 발신자에게 보낸다.
Sender Side Error Control
발신자는 수신자가 수신하였음을 확인하기 위해 보내는 ACK를 사용하여 Error Control을 수행한다. 쉽게 말하면 ACK가 너무 안들어오면 네트워크에 문제가 생긴 것으로 간주하고 다시 동일한 패킷을 보내게 되는데, ACK가 늦게 들어온다는 기준으로는 아래 두 가지가 있다.
- Retransmission Timeout(RTO) = Average(Round-Trip Time) + 4 dev(RTT)
- 3 Duplicates ACK = 다음 segment의 ACK가 3개 도착한 경우
일반적으로 RTO보다 3 Duplicates ACK가 더 빠르게 대응한다고 한다.
5. TCP Flow Control
Flow Control이란 Receiver Socket Buffer가 가득 차 전송한 패킷을 잃는 것을 방지하는 것을 말한다. 임시로 데이터를 저장하는 공간이라고 할 수 있는 Buffer는 각각 고유의 크기를 가지고 있는데 가득 찬 상태에서 새로운 데이터가 들어오면 저장하지 못하고 잃어버리는 특성을 가진다. 이렇게 되면 TCP의 경우 retransmission을 지원하므로 동일한 패킷을 반복적으로 보내게 되는 문제가 발생한다.
Flow Control을 위해 TCP에서는 수신자가 보내온 Window Size와 Acknowledge Number를 사용한다. 구체적으로 보낼 수 있는 데이터의 크기는 아래와 같이 (A+W-1)-B이다.
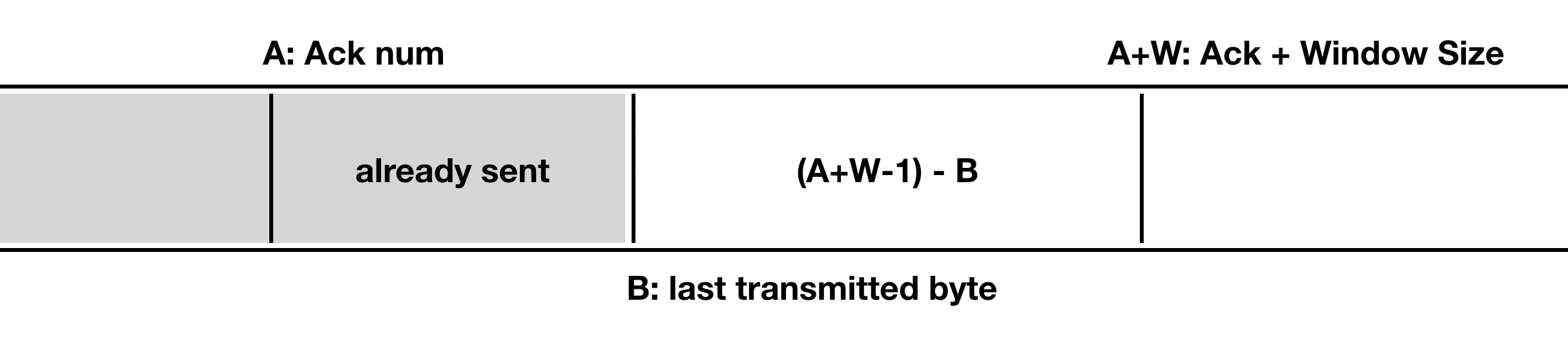
6. TCP Congestion Control
Congestion Control이란 수신자와 발신자의 문제가 아닌 네트워크의 문제로 인해 패킷이 매우 느리게 전송되거나 또는 전송이 불가능한 상태를 막기 위해 전송 속도를 조절하는 것을 말한다. 참고로 라우터의 처리량이 임계치를 넘어서 쓰루풋이 거의 0에 도달하는 경우를 Congestion Collapse라고 한다.
Congestion Control은 네트워크의 상태, 조금 더 구체적으로는 네트워크의 Capacity(Bandwidth X Delay)와 관련이 깊다. 그런데 이 Capacity는 지속적으로 변화하기 때문에 connection이 형성되어 있다면 지속적으로 확인하는 것이 필요하다. 이를 위해 사용되는 방법으로는 Fast Start Algorithm, Fast Retransmit Algorithm(3 Duplicates Ack), Fast Recovery Algorithm 등이 있다.
네트워크의 Capacity에 따라 앞으로 보낼 수 있는 적절한 데이터의 크기가 결정되는데 이를 Congestion Window Size라고 한다. 네트워크와 receiver socket buffer 모두에서의 overflow를 막기 위해 둘 중 작은 것을 기준으로 Flow Control을 하게 된다.
7. TCP is hating small segment
TCP는 MSS보다 작은 payload를 가진 패킷을 전송하는 것을 피하고 싶어한다. 제공하는 기능이 많고 그에 맞춰 큰 header를 가지는 TCP의 특성상 한 번 패킷을 주고받는데 비용이 크기 때문에 가능한 효율적으로 패킷을 전송하고 싶어하기 때문이다.
Nagle’s Algorithm은 이러한 문제를 해결하기 위한 방법이다. 쉽게 말하면 Sender Socket Buffer에 MSS보다 작은 데이터가 있는 경우에는 이전 Segment에 대한 ACK를 받기 전까지 전송을 미루는 것을 말한다. 전송을 미루는 경우 전체적인 통신 횟수가 줄어들어 네트워크 비용은 감소하지만 response time이 늘어나게 된다.
8. UDP, User Datagram Protocol
TCP와 비교해 UDP의 특성을 한 마디로 요약하자면 아무것도 하지 않는다라고 할 수 있다. TCP에서 안정적이고 원할한 통신을 위해 수행하는 다양한 작업들을 UDP에서는 대부분 하지 않기 때문이다. TCP에서는 이뤄지지만 UDP에서는 하지 않는 작업들로는 대표적으로 아래와 같은 것들이 있다.
- No Connection
- No Guarantee of delivery
- No Retransmission
- No In-order Delivery
- No Flow Control
- No Congestion Control
- No Fragmentation
- No PMTU Discovery
사실상 UDP는 Application layer와 데이터를 주고 받기 위해 필요한 Multiplexing, Demultiplexing 두 가지 작업 외에는 별다른 기능을 지원하지 않는다고 할 수 있다. 따라서 UDP는 PMTU size보다 패킷이 더 커서 전송에 실패하더라도 쪼개어 보내거나 재전송하지 않는다. 죽으면 죽었지 다시 보내지는 않는 것이다.
When UDP is used
아무것도 하지 않는다는 특성에서 얻을 수 있는 UDP의 장점은 TCP와 비교하여 매우 가볍다는 것이다. 데이터를 전송하기 전후로 connection을 만들고 없애기 위한 작업들이 필요없어 곧바로 데이터를 전송할 수 있고 수신자의 수신 여부는 생각하지 않고 바로바로 전송하기 때문에 TCP에 비해 전송의 안정성은 떨어지지만 보다 즉각적이고 빠르다. 이러한 점 때문에 TCP는 아래 세 가지 경우에 많이 사용된다.
- 실시간 전송: 빠르고 즉각적인 전송이 중요하다. 이전 패킷은 의미가 없다.
- 단순한 전송: 주고받는 패킷의 수가 적어 connction이 비효율적이다. DNS, DHCP, SNMP가 대표적이다.
- 멀티 캐스트: TCP는 멀티 캐스트, 브로드 캐스트가 불가능하다. IPTV가 대표적이다.
UDP Checksum
UDP는 checksum 또한 optional하다. 즉 써도 되고 안 써도 된다. 상대적으로 bit 하나하나가 매우 중요하게 작용하는 text의 경우에는 checksum을 사용하는 경우가 많은 반면 graphic, audio와 같이 해상도가 크게 중요하지 않은 경우에는 사용하지 않을 수 있다. 단 IPv6에서는 IP header에 checksum이 없으므로 UPD checksum이 의무적으로 요구된다.
참고로 checksum을 사용하지 않는 경우에는 field를 모두 0을 채워 넣게 된다. 이 경우 실제 계산된 checksum이 0인 경우에 문제되는데 checksum이 0이면 모두 1로 바꾸어 전송하게 된다.
UDP checksum과 관련해 가장 큰 특징 중 하나는 IP header를 재구성하여 만든 Pseudo Header를 포함하여 checksum을 계산한다는 것이다. 물론 Pseudo Header는 전송되지 않는데 IP header만을 가지고도 충분히 만들 수 있으므로 수신자 측에서도 동일한 과정을 거쳐 checksum을 검증하게 된다.